1.动机
为了学习更区别的点云特征,我们将3D体素卷积网络和基于PointNet的方法提取特征相结合。
既可以利用3D体素卷积网络高效的学习和高质量的建议,又利用了基于PointNet的网络的灵活感受野的优势。
2.怎么做的
首先采用稀疏3D体素卷积进行有效的特征编码并产生建议,为了更有效的池化3D建议对应的特征,我们用了两种新的操作:voxel-to-keypoint scene encoding:将场景中的所有体素汇总成少量关键点;point-to-grid RoI feature abstraction:将场景关键点特征聚集到RoI网格,用于建议置信度预测和位置细化。
3.网络

3.1 3D Voxel CNN for Efficient Feature Encoding and Proposal Generation

投影到BEV图上再产生建议,每个建议产生包括两个方向的anchor。
3.2. Voxel-to-keypoint Scene Encoding via Voxel Set Abstraction
Keypoints Sampling
首先仍要通过Furthest- Point-Sampling (FPS) algorithm从点云集中采样n个关键点。
Voxel Set Abstraction Module

我们用Voxel Set Abstraction (VSA) module去编码从3D体素特征到关键点的多尺度语义特征。(用的是PointNet++中的方法,区别是现在上一步中提取出的关键点的周围都是经过3D体素CNN处理过后带有多级语义特征的规则的体素,而不是PointNet++中的用PointNet学到的raw point的特征)

是第k层的每个体素的特征。
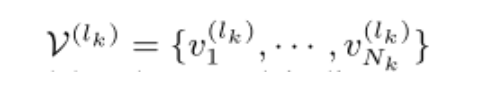
是第k层的体素的3D坐标。
Nk是第k层中非空体素的数量。

表示坐标的局部相对位置。
之后通过PointNet block产生关键点pi的特征
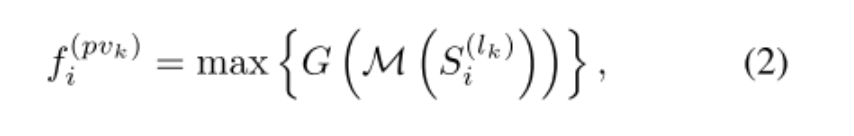
M表示从S中随机取样最多Tk个体素,G是多层感知机去解码体素特征和相对位置(也就是S中包含的两项)。
得到的f(pvk)i是关键点pi的特征向量。
并且我们要使用多个距离rk去得到多个尺度的特征(就像PointNet++中一样),再把得到的各个尺度的特征拼接起来。
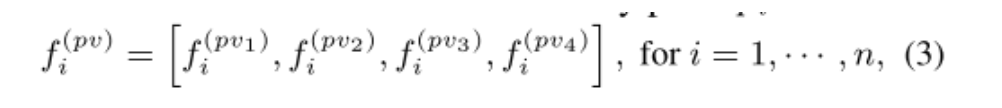
Extended VSA Module
我们在上一步得到的特征中还加入了从原始点云和从2DBEV图中得到的关键点特征,原始点补充了体素化过程中的损失,2DBEV图在Z轴有更大的感受野。
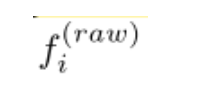
也是根据这个公式产生的:

是将关键点投影到2DBEV图中产生的,并且使用了双线性插值。
所以,最终得到的关键点pi的特征:
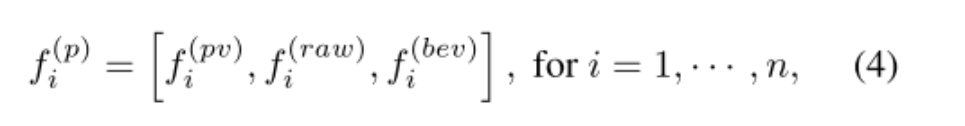
Predicted Keypoint Weighting

FPS选取的关键点中有前景点也有背景点,前景点在建议细化时应该占更大的比重,而背景点应该占的少些。
通过标注可以知道某个关键点是属于真实3D框内部还是外部,从而判断它是前景点还是背景点,从而实行监督。
Predicted Keypoint Weighting(PKW) module计算公式如下:

3.3. Keypoint-to-grid RoI Feature Abstraction for Proposal Refinemen
RoI-grid Pooling via Set Abstraction

先将每个3D建议框分成6×6×6=216个grid
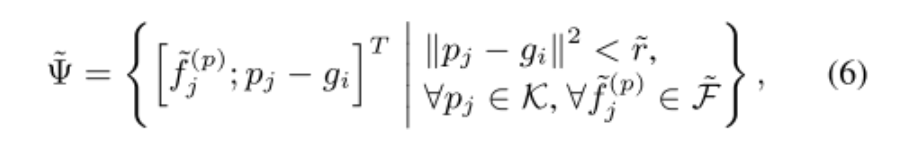
p是关键点,g是每个网格的中心点。
再通过与之前同样的公式(PointNet),得到每个grid的特征。
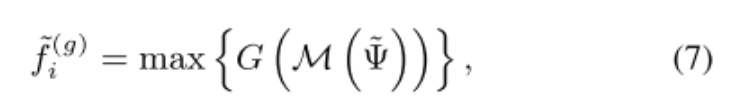
并且像之前一样,也采用了多个半径r来获得多个不同尺度获得的特征,再将它们拼接起来,经过一个两层的MLP得到256维的特征来代表整个建议框。
3D Proposal Refinement and Confidence Prediction

4.实验结果与消融实验
PV-RCNN的结果非常好
KITTI数据集

![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BdOaGYKb-1634785282830)(C:\Users\小秦\AppData\Roaming\Typora\typora-user-images\1613615880121.png)]](https://img-blog.csdnimg.cn/75a990c4af5c4a3ba649329dacc652ed.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBAYnJ5YW50IGZvcmV2ZXI=,size_20,color_FFFFFF,t_70,g_se,x_16)
Waymo数据集

消融实验:


