RNN循环神经网络
应用:
物体移动位置预测、股价预测、序列文本生成、语言翻译、从语句中自动识别人名、
问题总结
这类问题,都需要通过历史数据,对未来数据进行预判
序列模型
两大特点
-
输入(输出)元素具有
顺序关系
,有前后关系 - 输入输出不定长。如:文章生成、聊天机器人
简单理解
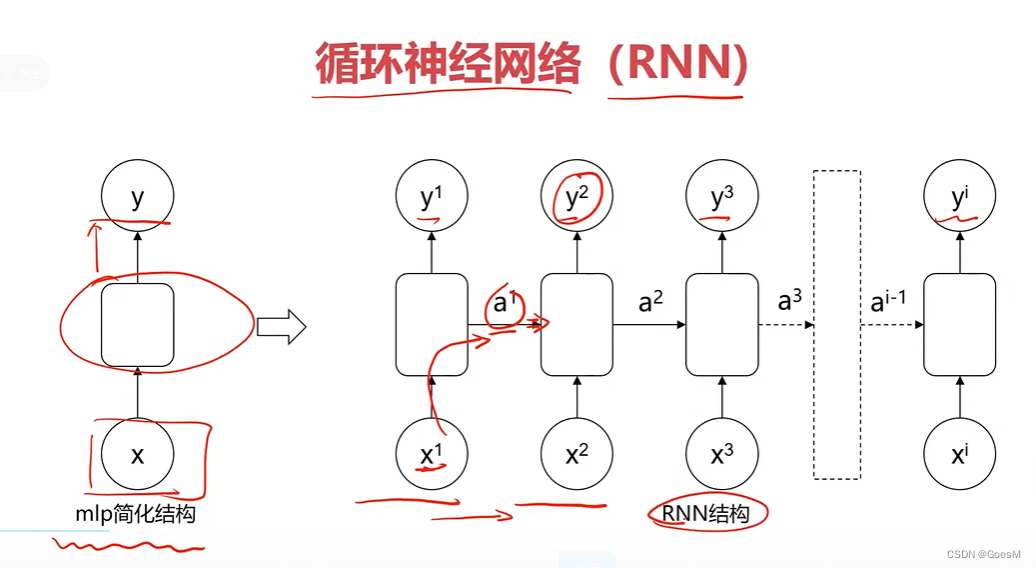
以人名识别为例

常见结构
多输入单输出结构
eg. 自然语言文字的情感识别
输入:语句(文字为多个输入信息)
输出:情感判断(是积极的还是消极的)
单输入多输出结构
eg. (序列数据生成器)根据关键词生成文章、音乐等
输入:关键词(单维信息)
输出:文章(多元信息)
多输入多输出结构
eg. 语言翻译
输入:中文(n维数据)
输出:英文(m维数据)
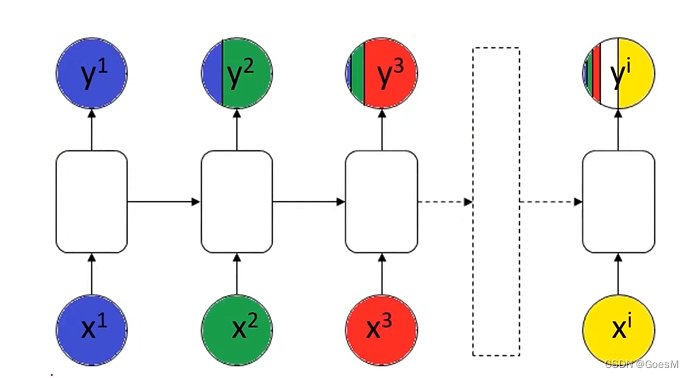
普通RNN模型
越新的信息对结果的影响占比越大,越旧的信息对结果的影响占比越小
缺陷
: 可能导致重要的旧信息丢失(图中蓝色在y中的占比即表示旧信息在结果中的影响占比)
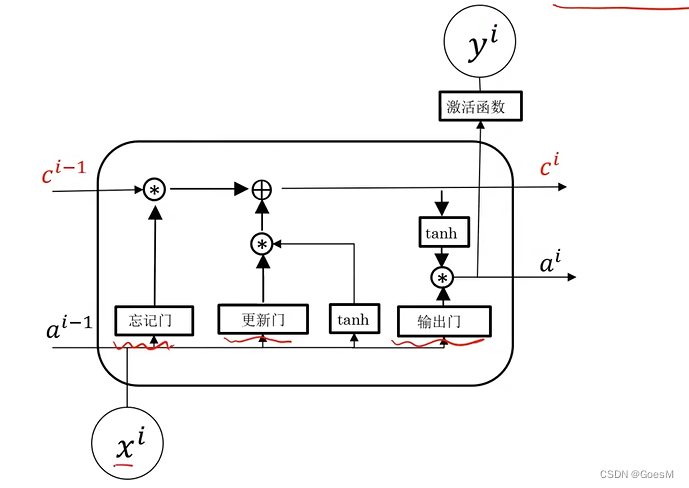
长短期记忆网络(LSTM)
算法逻辑:增加记忆细胞 C[i],以记忆重要信息
双向循环神经网络(BRNN)
简单理解
: 普通循环神经网络,只根据上文推测下文;双向循环神经网络,则是根据上文和下文来推测当前片段。
深层循环神经网络(DRNN)
简单理解
单层RNN+MLP,实现更好的拟合效果
实战一:RNN实现股价预测
算法效果
给定(数据-时间轴)数据集,
设定
Input_shape = (samples, time_steps, features)
,
sample
表示样本数量(默认为:根据输入数据自动计算)
time_steps
表示每次用前time_steps个数据预测下一个数据
features
表示样本的特征维数
生成预测曲线
算法流程:
Step 1. 数据载入 与 预处理
序列切断:按time_steps的长度,对被预测数据进行切断
# 数据切断函数
import numpy as np
def extract_data(data,time_step):
x=[] #前time_step个时间点的数据
y=[] #当前被预测时间点的数据
for i in range(len(data)-time_step):
x.append( [a for a in data[i:i+time_step] ] )
y.append( data[i+time_step] )
x = np.array(x)
x = x.reshape(x.shape[0],x.shape[1],1)
y = np.array(y)
return x,y
time_step = int(input("输入参考时间区间的长度:"))
x,y = extract_data(price_norm,time_step)
#print(x.shape)
Step 2. 建立RNN模型
from keras.models import Sequential
from keras.layers import Dense,SimpleRNN
#顺序模型
model = Sequential()
#RNN层
model.add(
SimpleRNN(
units=5, #神经元个数
input_shape = (time_step,1),
# 输入格式:以前time_step为根据,预测当前位置
# 数据维数为 1
activation = 'relu',# 激活函数用relu
)
)
#输出层
model.add(Dense(units=1,activation='linear'))
#参数设置
model.compile(
optimizer='adam',
loss='mean_squared_error', #平方差
metrics=['accuracy'] #这个模型看accuracy没有意义
)
model.summary()
Step 3. 预测
pred_y_train = model.predict(x) * max(price) #逆归一化
y_train = y*max(price)
#训练数据-预测训练数据预览
from matplotlib import pyplot as plt
fig1 = plt.figure(figsize=(8,5))
truth, = plt.plot(y_train)
pred, = plt.plot(pred_y_train)
plt.title('close price')
plt.xlabel('date')
plt.ylabel('price')
plt.legend( (pred,truth), ('pred_line','true_line'))
plt.show()
实战二:LSTM自动生成文本
算法效果
给定(文本)数据集,
构建 (文本-编码)字典
输入 编码后的文本数据
生成预测文本的编码
编码转文本
算法流程
Step 1. 数据载入 与 预处理
导入文本数据 => 转化为one-hot标签形式
data = open('file_name').read()
#移除换行符号
data = data.replace('\n','').replace('\r','')
print(data)
#建立字典
letters = list(set(data)) #去除重复
print(letters)
print(len(letters))
int_to_char = {a:b for a,b in enumerate(letters) }#建立字典
print(int_to_char)
Step 2. 建立RNN模型
Step 3. 预测