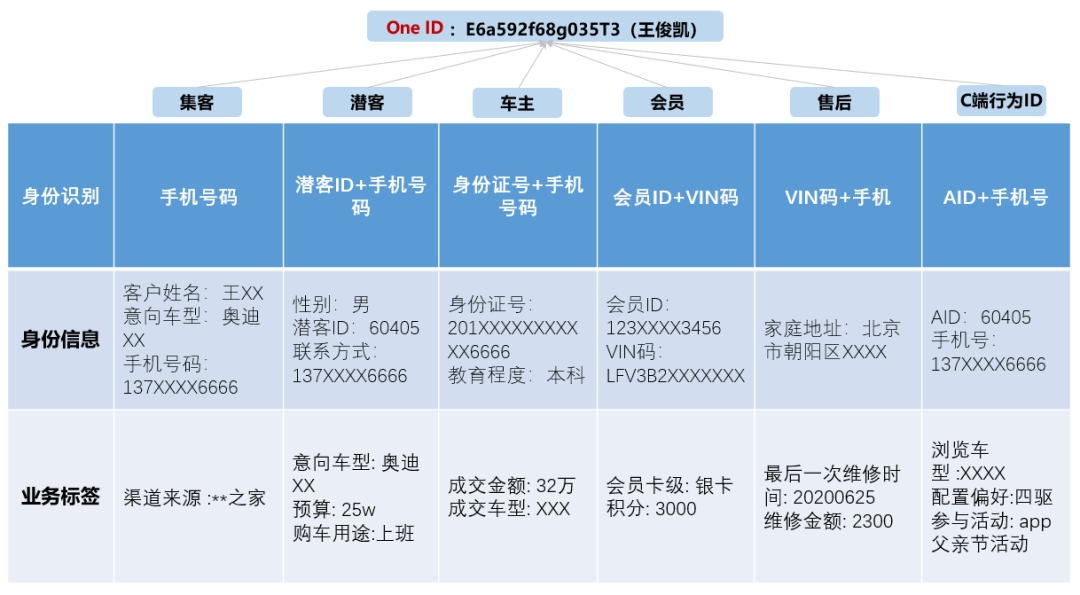
在OneData 体系中,OneID 指统一数据萃取,是一套解决数据孤岛问题的思想和方法。
数据孤岛是企业发展到一定阶段后普遍遇到的问题。各个部门、业务、产品,各自定义和存储其数据,使得这些数据间难以关联,变成孤岛一般的存在。
OneID的做法是通过统一的实体识别和连接,打破数据孤岛,实现数据通融。简单来说,用户、设备等业务实体,在对应的业务数据中,会被映射为唯一识别(UID)上,其各个维度的数据通过这个UID进行关联。
各个部门、业务、产品对业务实体的UID的定义和实现不一样,使得数据间无法直接关联,成为了数据孤岛。
基于手机号、身份证、邮箱、设备ID等信息,结合业务规则、机器学习、图算法等算法,进行 ID-Mapping,将各种 UID 都映射到统一ID上。通过这个统一ID,便可关联起各个数据孤岛的数据,实现数据通融,以确保业务分析、用户画像等数据应用的准确和全面。
一、ID Mapping 的背景
在推进用户画像和风险控制时,遇到的最大的问题是用户身份信息的混乱:
- 相同设备,不同账号间切换
- 相同用户,不同渠道下账号不相同,如微信小程序和APP
- 同个用户,在不同的设备商登录
- …
假如没有网络身份证,那么每个商家(App)只能基于自己的账号体系标识用户,并记录用户的行为。而有了统一的网络身份证之后,各个商家之间的数据就可以打通了,天猫不仅知道用户A在淘宝系的购物数据,也能了解到该用户在社交网络的行为,以及旅游的喜好,等等。
在现实的数据中,由于,用户可能使用各种各样的设备,有着各种各样的前端入口,甚至同一个用户拥有多个设备以及使用多种前端入口,就会导致,日志数据中对同一个人,不同时间段所收集到的日志数据中,可能取到的标识个数、种类各不相同;
存在的问题
- 用户设备的标识,没办法轻易定制一个规则来取某个作为唯一标识:
- mac地址:手机网卡物理地址, 若干早期版本的ios,winphone,android可取到
- imei(入网许可证序号):安卓系统可取到,若干早期版本的ios,winphone可取到,运营商可取到
- imsi(手机SIM卡序号):安卓系统可取到,若干早期版本的ios,winphone可取到,运营商可取到
- androidid :安卓系统id
- openuuid(app自己生成的序号) :卸载重装app就会变更
- IDFA(广告跟踪码)
常见的标识
设备 ID
需要注意的是,设备 ID 并不一定是设备的唯一标识。例如 Web 端的 Cookies 有可能被清空(例如各种安全卫士),而 iOS 端的 IDFV( Identifier For Vendor)在不同厂商的 App 间是不同的,而且重新安装IDFV会被重置。
比如用户可能使用各种各样的设备,其次是不同设备有不同的操作系统,设置是软件本身的版本也会影响我们对用户的标识,
-
手机、平板电脑、PC
-
安卓手机、ios手机、winphone手机
-
安卓系统有各种版本 ( 5.0 6.0 7.0 8.0 9.0 )
-
ios系统也有各种版本(3.x 4.x 5.x 6.x 7.x … 12.x )
登录 ID,用户名,手机号
登录 ID 通常是业务数据库里的主键或其它唯一标识。所以 登录 ID,相对来说更精确更持久。但是,用户在使用时不一定注册或者登录,而这个时候是没有_
登录 ID
_ 的。
二、方案详解
-
**基于账号:**体系企业中最常用的是基于账号体系来做ID的打通,用户注册时,给到用户一个uid,以uid来强关联所有注册用户的信息。
-
基于设备
:那对于未注册用户可以通过终端设备ID精准识别,包含Android/iOS两类主流终端的识别。通过SDK将各种ID采集上报,后台利用的ID关系库和校准算法,实时生成/找回终端唯一ID并下发。 -
**基于账号&设备:**结合各种账户、各种设备型号之间的关系对,以及设备使用规律等用户数据,采用规则规律、数据挖掘算法的方法,输出关系稳定的ID关系对,并生成一个UID作为唯一识别该对象的标识码。
-
方案一:仅使用设备 ID,不管用户是谁,只要设备未变,设备ID 就不变,即使多人使用同一个设备,也会被识别为同一个用户。
-
方案二:关联设备 ID 和登录 ID(一对一),
-
当用户换手机后,登录账号之后的行为与换手机之前的行为贯通了,但是在新设备上首次登录之前的行为仍没法贯通,仍被识别为新的用户的行为。
-
当用户把旧手机送给朋友之后,由于旧手机已被关联到自己的登录 ID 了,无法再与朋友的登录 ID 关联。后续使用这台旧手机的用户们,若不登录就操作,则都会被识别为同一个用户。
-
-
方案三:关联设备 ID 和登录 ID(多对一)
-
当用户把旧手机送给朋友之后,由于旧手机已被关联到自己的登录 ID 了,无法再与朋友的登录 ID 关联。后续使用这台旧手机的用户们,若不登录就操作,则都会被识别为同一个用户)。
-
而事实上,旧手机上后续的匿名登录很难识别到底是谁,可能归为匿名登录之前最近一次登录的用户会更合理一些。
-
其实,三种方案没有对与错,我们应该结合自己的业务场景以及埋点复杂度来选择合适的方案。
百度用的是图数据库的方式解决的。
图计算的逻辑就是把数据抽象成“点”和“边”,然后用图计算天然的“连接”特效,实现数据的自动识别和打通。

怎么实现ID串联

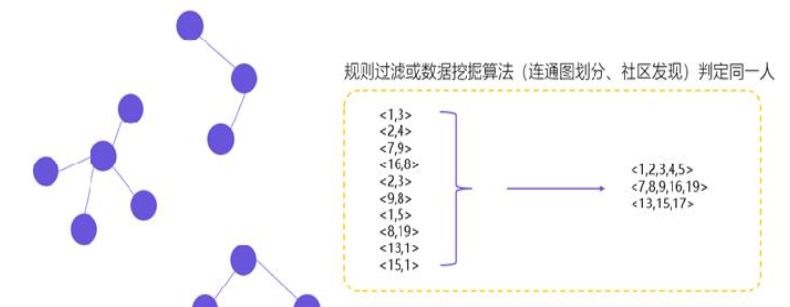
你看,其实我们要做的,就是把这几个数据做一个打通,类似于这样:
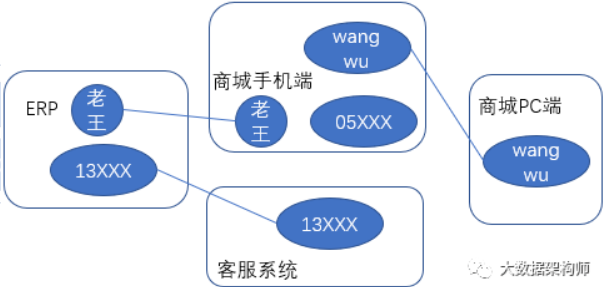
你看这个图,既没有方向,也可能不能形成“环”状。这就是一个无向连通图。这么着一连,这些信息就能对上了。
三、ID Mapping的核心技术
ID Mapping 有几个场景:1、多端数据的识别;2、多源数据的打通。这两种情况的处理方式基本是一样的。
先举一个例子:老王在商城PC端浏览商品,在手机端下单,后台自动生成订单,交给ERP进行后续的订单、物流处理。后来老王有点不耐烦,给供应链金融客服打电话咨询。那么老王的数据如下:
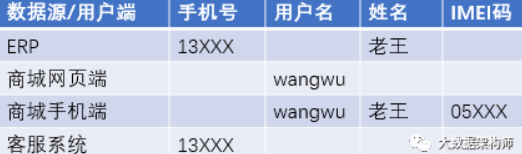
(注:大多数情况下网页端和手机端的 UUID 是一样的,这只是一个例子,理解大意就行)
所以呢, ID Mapping 的过程基本是以下几步:
- 1、各源/端的要素识别,就是能够识别用户信息的各个要素,原始 ID 也是有用的;
- 2、各自抽象和组装成“点”和“边”的数据集,设置边阈值,过滤弱连接;
- 3、构建一个图模型,用连通子图算法求得那些ID标识属于同一个对象;
- 4、得到结果集,分配一个新的 ID ;
- 5、去重、合并数据,生成最终结果;
- 6、循环 3-5 环节,同时在3环节使用已有结果集,已有 id 则沿用老 ID 。
整体流程:
- 将当日数据中的所有用户标识字段,及标志字段之间的关联,生成点集合 、边集合
- 将上一日的ids->guid的映射关系,也生成点集合、边集合
- 将上面两类点集合、边集合合并到一起生成一个图
- 再对上述的图执行“最大连通子图”算法,得到一个连通子图结果
- 在从结果图中取到哪些id属于同一组,并生成一个唯一标识
- 将上面步骤生成的唯一标识去比对前日的ids->guid映射表(如果一个人已经存在guid,则沿用原来的guid)
最后,就生成一张 id 映射字典,大概的意思就是:
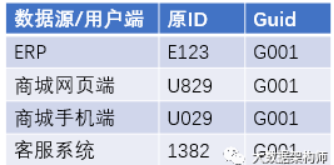


就这样,孤立的系统数据就算是从 ID 层面打通了,我们基于这个字典我们就能做更多事情了,比如更全面的画一个用户画像。
数据我们也能存好,怎么放都行,最好是扔ES等查询速度快的数据库里,对外提供 One ID 的查询服务。
以上就是ID-Mapping的核心技术了。在实际落地的时候,你还会遇到各种各样的问题,比如遇到多对多的情况怎么办?之前缺少要素匹配不上,但是后来用户增加了信息,又匹配上了咋办?
结果数据存成什么样比较好用?放在那里比较好?要不要建一个DV模型方便找数据?那是工程建设中需要考虑的问题。这就得完全靠实践出真知了。
OneID的规则设计
虽然上面的示例讲起来非常简单,但真实的用户数据存在于车企多个平台,且数据形式和数据信息也存在差异,真正操作起来还会存在很多“模棱两可”、“拿不准”的情况,因此,在利用ID Mapping串联用户信息的时候,需要设定规则。
规则的范围包含:①针对新增用户数据、②针对同一用户在不同渠道数据整合规则、③用户数据整合过程中涉及的细节、颗粒度补充规则等。
① 比如
新增用户规则
:如何判断不同组数据是否为同一用户数据?假如我们设定身份证号相同,即判断为同一人(E6a592f68g035T3),身份证号不同,赋予新的OneID(E6a592f68g035T4);
②
同一用户若在不同渠道/平台间都存在数据
,且数据相悖,那么我们应该取信哪个?如:VIN码为LFV123XXXXXX的车辆,在发票系统中留的车主姓名为王俊凯,而在售后系统中留的车主姓名为黄晓明。那么这辆车的车主到底叫什么名字?这时候我们应该对渠道来源置信度做规则设定。如根据了解,发票系统是每个用户在购车时需出示身份证件登记录入的,而售后去返厂维修保养的时候,却只需要送修人口头说一声即记录,因此我们判定:
发票> 售后
。在做OneID用户信息整合的时候,应该取这辆车的车主姓名王俊凯。
③ 用户
数据整合
过程中涉及的细节、颗粒度问题:虽然我们知道
发票系统置信度较高
,但实际探查发现,发票系统中有些用户信息的填充率很低(比如:婚姻状态、学历、邮箱等),这种情况下,就要“变通行事”,采用
多主键
或取其他渠道信息
填充率高且准确率也高的数据
,
补充完善车主信息。
总结
One ID的核心价值是打通数据孤岛,把不同时期孤立建设的系统,用统一的ID串联起来。One ID功能就像是在修桥梁,把各个数据孤岛贯通之后,这些孤岛就连成一片。
数据孤岛被打破之后,我们就能更全面、更完整的了解我们的用户、产品、商家,能够更加精准的评价他们的价值,进行进一步的价值发现,为精细化运营夯实数据基础。
One ID的核心技术是ID-Mapping,其原理是将各系统的关键要素抽象成图计算用的“点”和“边”,用图计算算法很轻易的判定同一个“对象”,从而构建一个个无向连通图,生成ID映射字典。
这个ID映射字典就是一座座通往各个数据孤岛的桥梁。我们通过这些桥梁,可以把相同“对象”在不同孤岛中的数据串联起来。这样,我们就掌控了全局,而非局部。
参考链接: