本系列是对《深度强化学习落地指南》全书的总结,这本书是我市面上看过对深度 强化学习落地讲的最好的一本书,大大拓宽了自己对RL落地思考的维度,形成了强化学习落地分析的一套完整框架,本文内容基本摘自这本书,有兴趣的读者可以点击文末链接自行购买。
作者对这本书的推荐序:
https://zhuanlan.zhihu.com/p/403191691
2.1 动作空间设计:这里大有可为
2.1.1 被忽视的价值
关于动作空间的设计容易被大家忽视,因为Agent控制的方式往往在一开始就限制死,正如游戏玩家无法决定DOTA有多少种基本操作,使用者也无法改变一个机器人的关节数量和各自的活动范围。但当有机会让算法工程师进行一定程度自由设计的时候必须足够重视,因为这里大有可为。一方面经过精心设计的动作空间能够显著提升DRL算法的探索效率和性能。对于特定任务而言,动作空间在事实上决定了算法所能达到的性能上限;另一方面,在DRL落地中,动作空间、状态空间和回报函数三者之间常常需要一定程度的设计工作。
- 对于初学者来说,动作空间的设计最容易忽略,很多刚接触RL就去做落地项目的朋友,一般问清楚可以控制的参数有哪些就差不多了,在项目测试阶段往往会出很多问题,所以弄明白这套动作空间设计框架还是十分有必要的。
2.1.2 动作空间的常见类型
动作空间主要包括离散式和连续式两种类型,具体采用哪种类型与目标任务自身的控制方式息息相关。离散动作空间由有限数量的动作组成,一般包含特定任务中所有可用的控制指令。离散动作空间通常采用下图(b)所示的One-Hot向量编码,每个编码位置对应一个动作,并且是完全互斥关系;有时为了压缩动作维度,还可以为各编码位置赋予不同层级的逻辑意义,如下图©所示,下图(a)中的二进制编码可以被看作一种特殊形式。在某些情况下,离散动作集合下具有显著的空间排布特征,如下图(d)所示,此时也可以采用二维或更高维的空间编码形式。图(e)展示了连续动作空间编码方式,两个维度分别代表方向盘转角(左正右负)和时速控制,根据标准区间[-1,1]内各自的取值,它们分别对应于右转120°和时速24km/h。
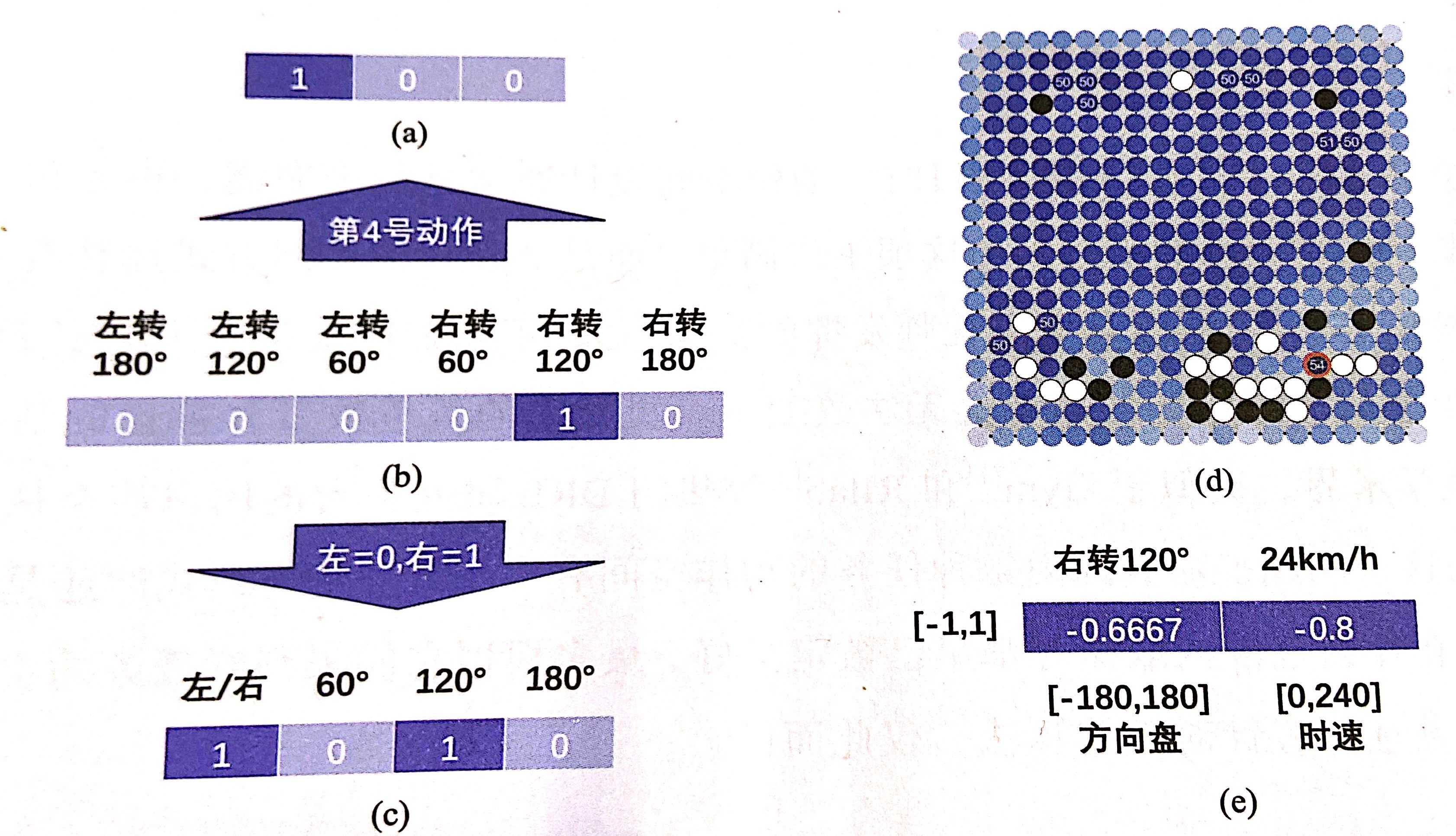
连续动作空间在大多数时候都采用多维向量式动作编码,所不同的是每个编码位置都代表一个独立控制的参数,如位置、速度等。每个控制参数一般都会根据实际情况预先定义合理的取值范围,考虑到这些范围在绝对值上往往存在巨大差异,因此通常利用线性变换将它们统一缩放至标准区间[-1,1]内,而策略网络的输出动作则可以通过逆向变换转化为一组真实的控制参数。
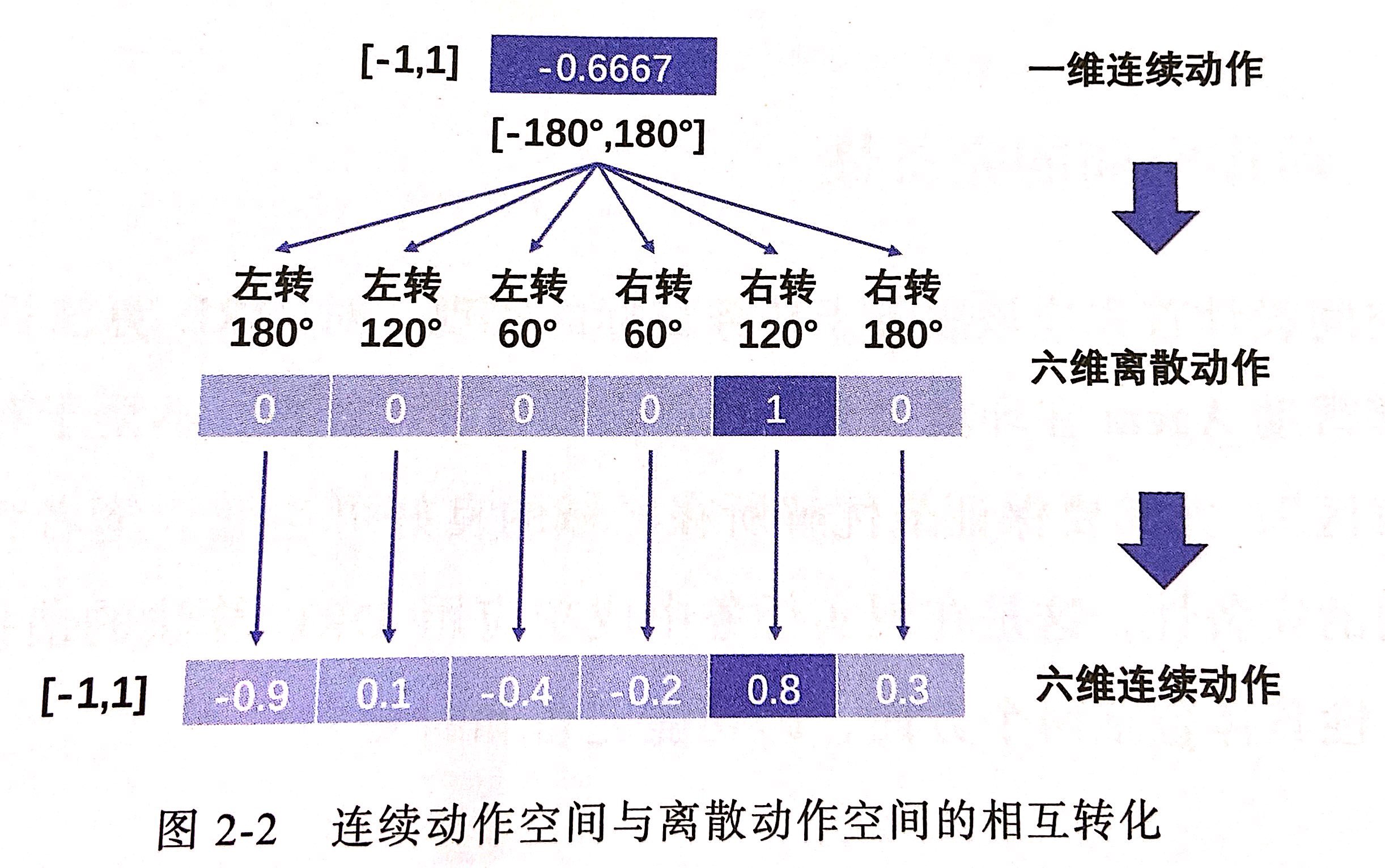
在实际任务中可能同时存在离散和连续两种控制方式的动作指令。如汽车方向盘采用连续控制方式,而转向灯则为离散档位控制。在这种情况下可以使用混合型动作空间,但需要对标准的DRL算法进行相应定制化,作者推荐尽量避免这样做。如果是任务需要,可以将混合空间先变为纯离散空间或纯连续空间。一方面连续动作可以按照适当粒度进行离散化;另一方面离散动作也能够以类似于连续动作的方式进行表征。
2.1.3 动作空间设计的基本原则
- 动作空间设计的基本原则包括三个:完备性、高效性和合法性,其中完备性分为功能完备性和时效完备性。
2.2动作空间的完备性
2.2.1 功能完备性
- 功能完备指的就是确保动作空间中包含具有完成目标任务的全部能力(动作)。比如对开车这个任务,设计的动作空间就至少需要包括方向盘、刹车、油门、换挡杆、转向灯、雨刷,同时应该“满量程”地利用他,只有这样才能应对各种复杂的地形、路况和天气。这里还要注意一点,前面提过连续动作空间可以转换为离散动作空间,但如果这个转换的精度比较粗糙,就满足不了“满量程”的要求了。比如当你将方向盘的[-180°,-180°]的连续范围转换为-180°,0°,180°三个离散值,这样的转换显然没办法满足真实开车场景的需要。
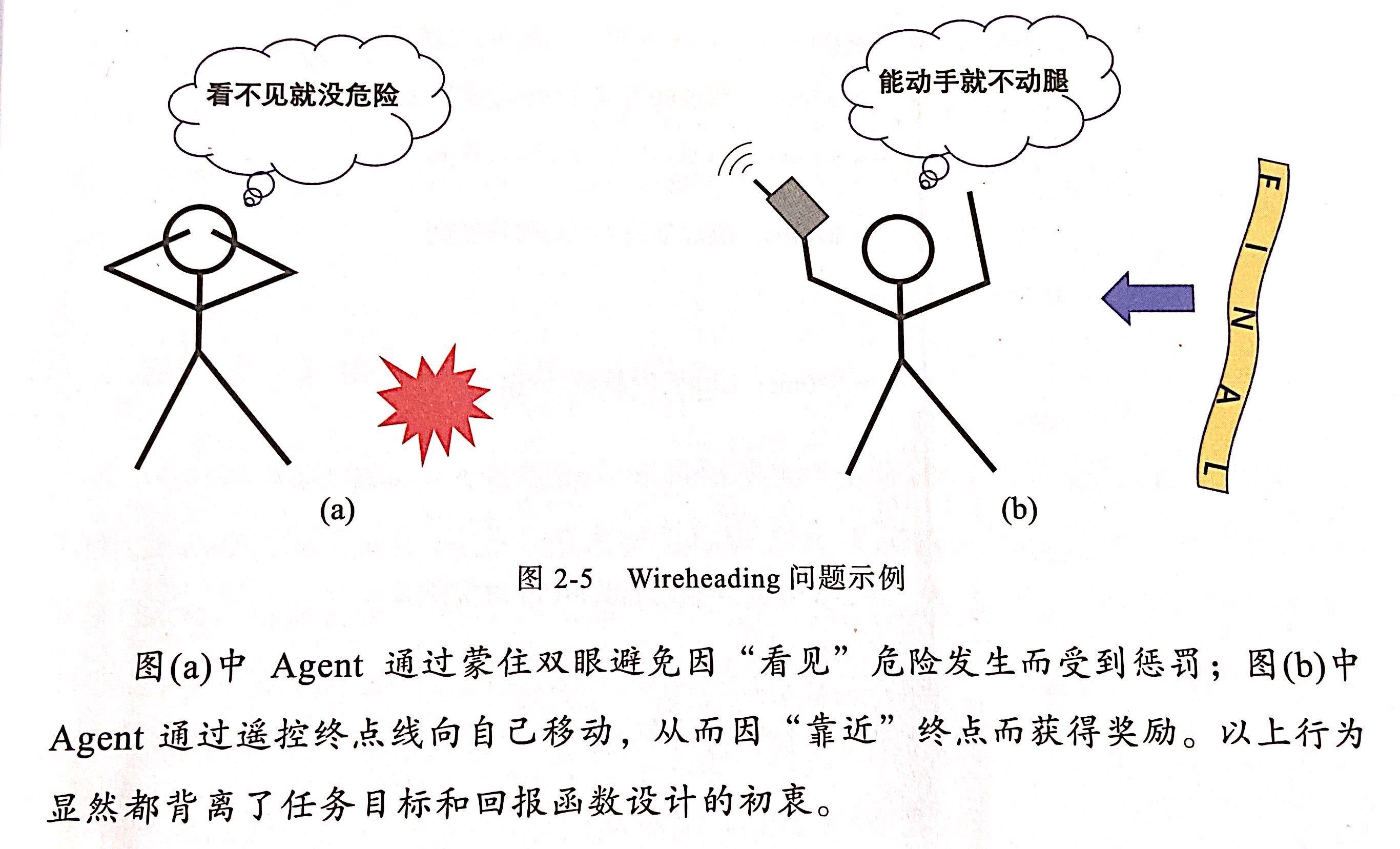
还有一点注意,即应避免赋予Agent篡改回报函数的能力。在强化学习任务中,回报函数的计算通常都基于环境信息的感知和加工,如果智能体可以通过动作空间投机地学会某种策略,就可以通过操纵回报函数来持续获得高回报,这个现象就叫做WireHeading。
2.2.2 时效完备
- 动作空间的设计不仅仅是堆砌可用指令,还包括为这些指令选择合理的决策周期,因为同样的动作在不同时间分辨率下的执行效果可能存在天壤之别。比如现在大家熟知的高频量化交易领域,同样的一步决策,如果有百分之一毫秒级的速度优势,也可能带来巨大的收益。所以动作空间的决策周期应该满足完成特定任务所需的最低时间分辨率来保证动作空间的时效完备性。
现实中,最低时间分辨率与理论最高分辨率之间往往存在一个时效完备区间,在这个区间可以根据灵活选择决策周期。一般而言,较短的决策周期能够提升智能体的灵活性和机动性从而有助于其处理对反应速度要求较高的场景。
2.3 动作空间的高效性
2.3.1 化整为零:以精度换效率
对于DRL算法,任务的解空间可以表示为
S×
A
S × A
S
×
A
,其复杂度由状态空间
SS
S
和动作空间
AA
A
共同决定。为了改善连续动作空间构成的巨大解空间,可以将连续动作空间离散化,通过牺牲一部分的控制精度换取解空间维度的大幅压缩以及探索效率的显著提升。
- 与时效完备区间类似,动作空间离散化的粒度也存在一个功能完备区间,其粒度上限是原有连续动作空间,下限则对应维持功能完备性所需的最低控制精度。功能完备区间也对应着一个在动作空间完备性和高效性之间的黄金区域,使得探索效率改善带来的收益超过控制精度下降带来的损失。
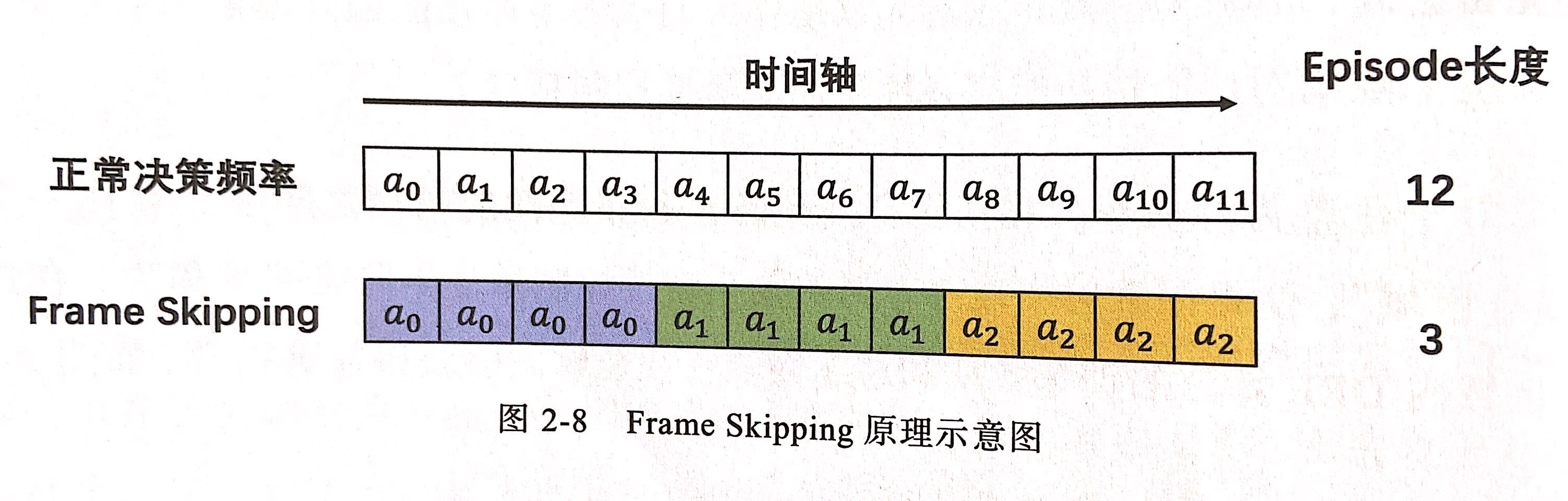
在广义动作空间的时间维度上也存在一种特殊的离散化操作——Frame Skipping(跳帧)。该技术的出发点是,过短的决策周期会显著增加Episode(Trajectory)的长度,迫使Agent不得不向前考虑更多的步骤,这不利于在长时间跨度下建立决策相关性,算法的训练难度也随之提高。如下图所示,Frame Skipping通过在时效完备区间内刻意降低决策频率,并在相邻两次决策之间重复上一次的动作,从而大幅缩短Episode长度。Frame skipping也可以采用自适应跳帧步长,即在不同状态下采取不同步数的动作重复策略,实现只在需要时做决策的效果。
2.3.2 有机组合:尺度很重要
- 除了化整为零,设计高效动作空间的另一种方式是对基本控制手段的有机组合。比如玩实况的时候,踩单车、油炸丸子这类符合的动作会对球员过人有明显的帮助。这种复合动作就被称为宏动作(Macro Action)。虽然宏动作看起来都是由基本动作组成,但在缺乏针对性汇报函数设计的情况下智能体很难稳定高效地学习到这些策略。所以如果在设计动作空间时直接将这些复合动作作为常备选项,并由DRL算法学习如何在基础动作以外恰当地运用,那么智能体的探索效率将明显得到改善,收敛速度和性能也能得到提升。这里要注意,复合动作不一定都只是机械的组合,也可以是一个函数、一套规则甚至一种算法。在落地的时候可以多和业界工程师沟通,把他们多年的工程经验融合进动作空间的设计当中,在实际应用中效果很好。
除了手工设计,宏动作也可以由算法自动学习,强化学习领域的热门分支之一——层级强化学习(Hierarchical Reinforcement Learning,HRL)就是专门研究这个方向。在HRL中通常包含高层级和底层级两种学习器,前者负责发现和切换宏动作(option),后者负责执行
2.4 动作空间的合法性
2.4.1 非法动作屏蔽机制
非法动作屏蔽机制同样属于动作空间设计不可或缺的一部分。对于离散动作空间,常规做法是忽略特定状态下的所有非法动作,并将剩余合法动作的Q值或策略响应重新归一化,然后再按照正常方式进行采样(训练阶段),或者直接输出最优动作(部署阶段);对策略输出做截断处理。
- 在真实DRL落地,非法动作屏蔽机制非常重要,因为在真实的工业落地场景,很多时候是没有模拟器给你试错的,可能智能体一个不小心就造成了成百上千万的损失。所以在一开始设计动作空间的时候,就要不断跟工程师沟通,把所有可能出现的意外特殊情况全部沟通清楚并设计好非法动作屏蔽机制避免意外。这里还有一点需要注意,跟工程师沟通的时候除了要考虑智能体下发的指令是否会在异常情况下造成损失,还要确保指令能完全正确下发,举个例子:智能体现在让空调压缩机转速调高1.11%,在测试阶段就得检查是否正确下发了这个指令,还要注意下发指令的精度是否完全一致,笔者就被这个点坑过。
2.4.2 Agent的知情权
-
虽然通过非法动作屏蔽机制可以让DRL算法不输出非法动作,但相关规则也是环境中的一部分,所以仍应该让DRL学会主动识别和遵守规则。最有效的方式是借助状态空间和回报函数的配合,尤其是状态空间的针对性设计。简单来说就是将规则以一种特殊的方式加入到状态信息当中,下图展示了一种用二进制编码表示当前可用合法动作的状态信息设计案例。
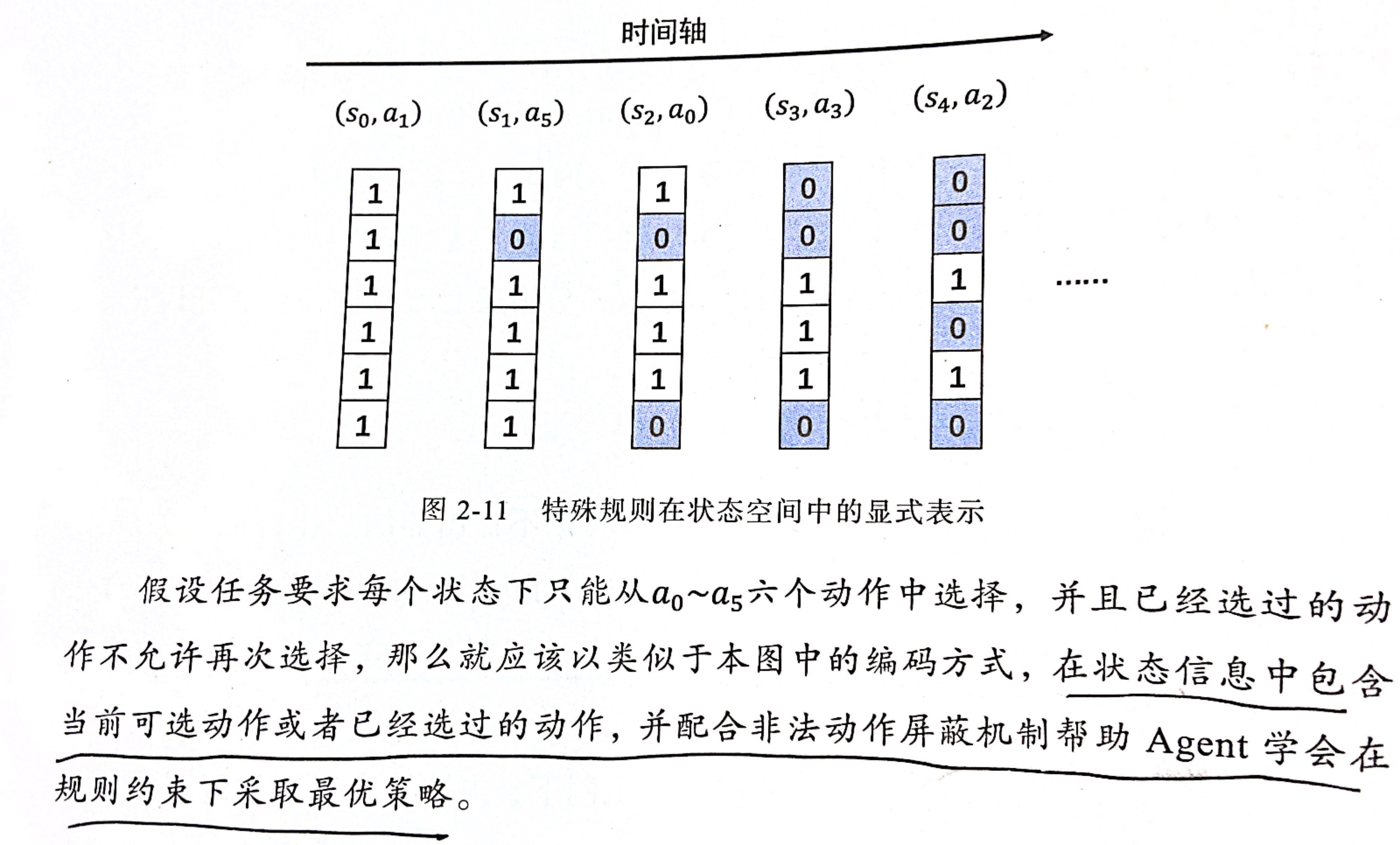
此外还可以在回报函数中增加针对非法动作的惩罚项,从而帮助Agent更直观地捕捉到非法动作与优化目标之间的负向相关性。
- 这一点需要补充说明一下,因为在工业场景中工程师平时做的更多的是重复机械型工作,所以很多非法情况并不能完全在非法动作屏蔽机制中进行屏蔽(当然一般都是没那么严重的非法动作),所以在回报函数中针对一些特殊指标进行惩罚还是非常有必要的。
将当前可用的合法动作编码进状态信息中的做法并非使DRL算法主动遵守特殊规则的唯一方案。还有一种方案是利用LSTM和GRU等拥有记忆功能的RNN结构,将同一段Episode内的历史决策和对应回报依次输入进来,由神经网络自动发现非法动作和即时负反馈,以及它们与相应状态的联系,从而避免在接下来的决策中输出非法动作。这种方案借鉴了元强化学习(Meta Reinforcement Learning)的思路,后者致力于学习一类相似任务的通用知识,并在同分布内的陌生任务中通过少量环境交互即可快速适应。