RDD 算子
其实就是rdd方法,和scala方法区分开来
分为两种 转换算子 和行动算子
转换算子
功能的补充封装 将旧的RDD包装成新的RDD
比如 map flatmap
整体上分为Value类型、双Value类型和Key-Value类型
Value类型
map算子
每次处理一条数据,对数据或数据类型进行转换
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("map")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(1,2,3,4))
def mapFunction (num:Int) ={
num * 2
}
//map 算子
rdd.map(mapFunction)
//用匿名函数简化上述代码
rdd.map((num:Int)=>{num*2})
//函数只有一行代码 所以{} 可省略
rdd.map((num:Int)=>num*2)
//函数只有一个参数 所以()也可省略 函数参数类型可以自动推断 类型可以省略
rdd.map(num=>num*2)
//num也可以简化
val res = rdd.map(_*2)
res.collect().foreach(println)
}
RDD的计算 一个分区内的数据是一个一个执行逻辑
只有前面一个数据全部的逻辑执行完后,才会执行下一个数据。
分区内数据的执行顺序是有序的。
不同分区之间是无序的
val rdd2= sc.makeRDD(List(1,2,3,4),1) //指定分区数为1
val mapRDD2 = rdd2.map(
line =>{
println(">>>>>>>>>>>"+line)
line
}
)
val mapRDD3= mapRDD2.map(
line =>{
println("$$$$$$$$$$"+line)
line
}
)
mapRDD3.collect()
打印结果:

分区内数据的执行顺序是有序的。只有前面一个数据全部的逻辑执行完后,才会执行下一个数据。
在上述代码中 List(1,2,3,4) 所以先执行数据1的逻辑 再执行2的逻辑…
mapPartiotions 算子
每次处理一个分区的数据,
但是会将整个分区的数据加载到内存进行引用,如果整个分区没有处理完是不会被释放的
在内存较小,数据量较大的场合下,容易出现内存溢出。
val sparkConf = new SparkConf().setAppName("mapPartition").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
val mapRdd = sc.makeRDD(List(1,2,3,4),2) //指定分区数为2
val res = mapRdd.mapPartitions(
datas => {
println(">>>>>>") //两个分区 处理两次 会打印两次
datas.filter(_%2==0)
}
)
res.collect().foreach(println)
mapParititionsWithIndex 算子
附带分区号,可具体获取某个分区的数据
val mapRdd = sc.makeRDD(List(1,2,3,4),2)
//获取第二个分区的数据
val res = mapRdd.mapPartitionsWithIndex(
(index,iter)=>{
if(index ==1) iter else Nil.iterator
}
)
res.collect().foreach(println)
flatMap
将多个集合的数据扁平化 为一个集合
//flatMap 将多个集合的数据扁平化 为一个集合
val rdd = sc.makeRDD(List(2,List(1,2,3,4),8,List(1,2,3,4)))
val flatmapRDD = rdd.flatMap(
data => {
data match {
case list:List[_] => list
case dat => List(dat)
}
}
)
flatmapRDD.collect().foreach(println)
glom
每个分区的数据 都转换为相同类型的内存数组 分区数/分区内数据不变
//glom 将同一个分区的数据 直接转换为相同类型的内存数组进行处理,分区不变
val rdd = sc.makeRDD(List(1,2,3,4),2)
//两个分区 [1,2] [3,4]
val glomRdd: RDD[Array[Int]] = rdd.glom()
//[2] [4]
val maxRdd: RDD[Int] = glomRdd.map(
arr => arr.max
)
//6
println(maxRdd.collect().sum)
groupBy
将数据按照指定规则进行分组,分区默认不变,但是数据会打乱重新组合,这种操作称为shuffle
val rdd = sc.makeRDD(List(1,2,3,4),2)
//偶数为一组 奇数为一组
val groupRdd = rdd.groupBy(_ % 2 == 0)
groupRdd.collect().foreach(println)
由于上述例子中,有两个分区,分区数据可能如下图,
那么要分组,就需要打乱重新组合

sample
根据指定的规则从数据集中抽取数据
应用场景:
在实际开发过程中,往往会出现数据倾斜的情况。那么可以从数据倾斜的分区中抽取数据,查看数据的规则。分析后,可以进行改善处理,让数据更加均匀。
val dataRDD = sparkContext.makeRDD(List(
1,2,3,4
),1)
// 第一个参数:抽取的数据是否放回,false:不放回 true:放回
// 第二个参数:抽取的几率,范围在[0,1]之间,0:全不取;1:全取;
// 第三个参数:随机数种子 如果不传递该参数,默认使用当前时间
val dataRDD1 = dataRDD.sample(false, 0.5,1)
// 抽取数据不放回(伯努利算法)
// 伯努利算法:又叫0、1分布。例如扔硬币,要么正面,要么反面。
// 具体实现:根据种子和随机算法算出一个数和第二个参数设置几率比较,小于第二个参数要,大于不要
distinct
去重
val rdd = sc.makeRDD(List(1,2,3,4,1,2,3,4))
val disRdd = rdd.distinct()
/**
* 底层源码:
* def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
* map(x => (x, null)).reduceByKey((x, y) => x, numPartitions).map(_._1)
* }
*
*map (1,null)(1,null) => reduceByKey (1, (null,null))=>(1,null) => map 1
*/
println(disRdd.collect().mkString(","))
coalesce
一般用来缩减分区,用于大数据集过滤后,提高小数据集的执行效率.
当spark程序中,存在过多的小任务的时候,可以通过coalesce方法,收缩合并分区,减少分区的个数,减小任务调度成本
val rdd = sc.makeRDD(List(1,2,3,4,5,6),3)
val colRdd = rdd.coalesce(2)
/**
* 原来是三个分区 数据分配是 partition1【1,2】 partition2【3,4】 partition3【5,6】
* 现在是两个分区 数据分配变成 partition1【1,2】 partition2【3,4,5,6】
*/
colRdd.saveAsTextFile("output/coalesce")
为啥不是 【1,2,3】 【4,5,6】?
因为coalesce默认情况不会打乱分区重新组合

这种情况下的缩减分区可能会导致数据不均衡,出现数据倾斜
如果想要数据均衡,可以进行shuffle处理(将coalesce的第二个参数设为true)

此时就会将数据打乱重新组合,如下图

repartition
一般用来扩大分区,将分区数少的RDD转换为分区数多的RDD
底层源码:就是调用的coalesce,固定shuffle = true
因为如果不打乱分区重新组合,原来同一个分区的数据还是会放到一个分区,扩大分区没有意义
所以一定要进行shuffle操作
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
coalesce(numPartitions, shuffle = true)
}
sortBy
排序,默认为正序排列。排序后新产生的RDD的分区数与原RDD的分区数一致。
val dataRDD = sparkContext.makeRDD(List(
1,2,3,4,1,2
),2)
//第一个参数为排序的字段
//第二个参数为排序方式,默认为升序,可调整为降序
val dataRDD1 = dataRDD.sortBy(num=>num, false)
双value类型
交集并集差集要求两个数据源类型保持一致
拉链操作两个数据源类型可以不一致,但是分区数量和分区中数据数量要保持一致
val rdd1= sc.makeRDD(List(1,2,3,4))
val rdd2 = sc.makeRDD(List(3,4,5,6))
//交集 【3,4】
println(rdd1.intersection(rdd2).collect().mkString(","))
//并集 【1,2,3,4,3,4,5,6】
println(rdd1.union(rdd2).collect().mkString(","))
//差集 【1,2】
println(rdd1.subtract(rdd2).collect().mkString(","))
//拉链 【(1,3),(2,4),(3,5),(4,6)】
println(rdd1.zip(rdd2).collect().mkString(","))
key-value类型
partitionBy
将数据按照指定Partitioner重新进行分区。Spark默认的分区器是HashPartitioner
//对数据进行重分区
val rdd1= sc.makeRDD(List(1,2,3,4),2)
val tupleRdd = rdd1.map((_,1))
tupleRdd.partitionBy(new HashPartitioner(2))
.saveAsTextFile("output/partitionBy")
如果多次重分区使用的分区器相同(类型,数量),不会再次重分区,因为没有意义。
reduceByKey
对相同key的数据进行value的聚合操作
//对相同key的数据进行两两聚合操作
val dataRDD1 = sc.makeRDD(List(("a",1),("a",2),("c",3)))
//如果key的数据只有一个,是不会参与两两计算的
dataRDD1.reduceByKey(
(x:Int,y:Int)=>{
println(s"x=${x},y=${y}")
x+y
}
).collect().foreach(println)
/**
* 打印结果如下: key为“c"时 只有一个数据 不参与两两计算
* x=1,y=2
* (a,3)
* (c,3)
*/
groupByKey
对相同key的数据进行分组
val dataRDD1 = sc.makeRDD(List(("a",1),("a",2),("c",3)))
//元组中的第一个元素就是key ,相同key的元素分在一个组中
val groupRdd: RDD[(String, Iterable[Int])] = dataRDD1.groupByKey()
groupRdd.collect().foreach(println)
/**
* 打印结果如下:
* (a,CompactBuffer(1, 2))
* (c,CompactBuffer(3))
*/
reduceByKey VS groupByKey
两个算子没有使用上的区别。所以使用的时候需要根据应用场景来选择。
从性能上考虑,reduceByKey存在预聚合功能,这样,在shuffle的过程中,落盘的数据量会变少,所以读写磁盘的速度会变快。性能更高


aggregateByKey
val rdd = sc.makeRDD(List(("a",3),("a",2),("a",4),("a",5)),2)
/**aggregateByKey存在函数柯里化,有两个参数列表
* 第一个参数列表表示 初始值
* 主要用于当碰见第一个key时,和value进行分区内计算(两两进行迭代计算)
* 第二个参数列表需要传递两个参数
* 第一个参数表示 分区内计算规则
* 第二个参数表示 分区间计算规则
* 下面的例子,求每个分区内最大值 相加的结果
*/
//分区1 ("a",3),("a",2) 分区2 (("a",4),("a",5)
//分区内求最大值 分区1("a",3) 分区2 ("a",5)
//分区间求和 ("a",8)
val aggrRdd: RDD[(String, Int)] = rdd.aggregateByKey(0)(
(x, y) => math.max(x, y), //分区内求最大值
(x, y) => x + y //分区间求和
)
aggrRdd.collect().foreach(println)
小练习:求相同key的数据的平均值
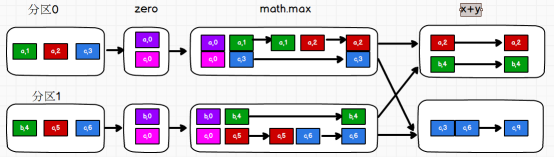
//求相同key的数据的平均值
val rdd1 = sc.makeRDD(List(
("a",3),("a",2),("b",4),
("b",5),("b",3),("a",4)
),2)
//要求平均值 需要计算 相同key中 value的和 / value的数量
//aggregateByKey 最终返回的结果 数据类型 和初始值 保持一致 所以下面代码返回tuple(value的和,value的数量)
val aggeRdd1 = rdd1.aggregateByKey((0, 0))(
(tuple, value) => {
(tuple._1 + value, tuple._2 + 1) //分区内 (value的和,value的数量)
},
(tuple1, tuple2) => { //分区间 两两tuple进行累加
(tuple1._1 + tuple2._1, tuple1._2 + tuple2._2)
}
)
aggeRdd1.mapValues{
case (sumValue,cntValue)=>{
sumValue/cntValue
}}.collect().foreach(println)
foldByKey
当aggregateByKey 分区内 和 分区间 规则一样时,spark提供了另外一个算子foldByKey简化
//当aggregateByKey 算子分区内 和 分区间 规则一样时
rdd.aggregateByKey(0)(
(x, y) => x+y, //分区内
(x, y) => x + y //分区间
)
//上述过程可简化为
rdd.aggregateByKey(0)(_+_,_+_)
//当分区内 和 分区间 规则一样时,spark提供了另外一个算子foldByKey简化
rdd.foldByKey(0)(_+_)
combineByKey
最通用的对key-value型rdd进行聚集操作的聚集函数(aggregation function)。类似于aggregate(),combineByKey()允许用户返回值的类型与输入不一致。
用这个函数求每个key的value平均值 ,对比 aggregateByKey 的用法,这个函数,没有初始值,但是可以对第一个value进行处理,再进行计算
计算(value的和,value的次数)两个算子的计算方法如下:
aggregateByKey 使用初始值(0,0)value => 累加 (0+value,0+1)
combineByKey 对第一个value进行处理 value1 转换=> (value1,1) =>(value1+value2,1+1)
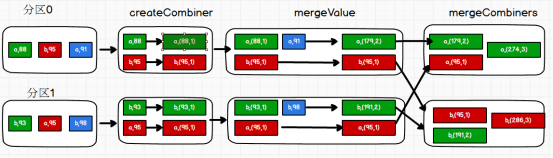
val rdd = sc.makeRDD(List(("a",3),("a",2),("b",4),("a",4),("b",8)),2)
val combineRdd: RDD[(String, (Int, Int))] = rdd.combineByKey(
v => (v, 1), //对第一个value进行处理 value1 => (value1, 1)
(tuple: (Int, Int), v) => { //分区内 ((value1,1),value2) => (value1+value2,1+1)
(tuple._1 + v, tuple._2 + 1)
},
(tuple1: (Int, Int), tuple2: (Int, Int)) => {
//分区间 ((valueSum1,valueCnt1),(valueSum2,valueCnt2)) =>
(tuple1._1 + tuple2._1, tuple1._2 + tuple2._2)
//(valueSum1+valueSum2,valueCnt1+valueCnt2)
}
)
val averageCnt: RDD[(String, Int)] = combineRdd.mapValues {
case (sum, cnt) => {
sum / cnt
}
}
averageCnt.collect().foreach(println)
reduceByKey、foldByKey、aggregateByKey、combineByKey的共同点和区别?
val rdd = sc.makeRDD(List("apple","boy","apple","cool","boy","apple","cool"),2)
val mapRdd = rdd.map(x=>(x,1))
//都能实现wordCount
mapRdd.reduceByKey(_+_)
mapRdd.aggregateByKey(0)(_+_,_+_)
mapRdd.foldByKey(0)(_+_)
mapRdd.combineByKey(v=>v,(v1:Int,v2)=>v1+v2,(v1:Int,v2:Int)=>v1+v2)
/**
reduceByKey底层核心源码:
combineByKeyWithClassTag[V](
(v: V) => v, //第一个值不变
func, //分区内计算规则
func, //分间内计算规则 和 分区内计算规则相同
partitioner
)
aggregateByKey底层核心源码:
combineByKeyWithClassTag[U](
(v: V) => cleanedSeqOp(createZero(), v), //设定初始值 和 key的第一个value做计算
cleanedSeqOp, //分区内计算规则
combOp, //分间内计算规则
partitioner)
foldByKey底层核心源码:
combineByKeyWithClassTag[V](
(v: V) => cleanedFunc(createZero(), v), //设定初始值 和 key的第一个value做计算
cleanedFunc, //分区内计算规则
cleanedFunc, //分间内计算规则 和 分区内计算规则相同
partitioner)
combineByKey底层核心源码:
combineByKeyWithClassTag(
createCombiner, //对key的第一个value做操作
mergeValue, //分区内计算规则
mergeCombiners, //分间内计算规则
defaultPartitioner(self))
*/
reduceByKey、foldByKey、aggregateByKey、combineByKey 底层都是 combineByKeyWithClassTag 方法
不同的是 输入参数不同
reduceByKey 对第一个值不做处理,分区内和分区间的计算规则相同
aggregateByKey 加入初始值,将初始值与key的第一个value 做计算,分区内和分区间的计算规则不同
foldByKey 加入初始值,将初始值与key的第一个value 做计算,分区内和分区间的计算规则相同
combineByKey 对key的第一个value做转换处理,分区内和分区间的计算规则不同
join & leftOuterJoin & rightOuterJoin
在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素连接在一起的(K,(V,W))的RDD
val rdd1 = sc.makeRDD(List(("a",3),("b",4),("c",8)))
val rdd2 = sc.makeRDD(List(("a",3),("b",4),("a",4)))
rdd1.join(rdd2).collect().foreach(println)
/**
* 类似于sql中的内连接,结果:
* (a,(3,3))
* (a,(3,4))
* (b,(4,4))
*/
rdd1.leftOuterJoin(rdd2).collect().foreach(println)
/**
* 类似于sql中的左连接,结果:
* (a,(3,Some(3)))
* (a,(3,Some(4)))
* (b,(4,Some(4)))
* (c,(8,None))
*/
rdd1.rightOuterJoin(rdd2).collect().foreach(println)
/**
* 类似于sql中的右连接,结果:
* (a,(Some(3),3))
* (a,(Some(3),4))
* (b,(Some(4),4))
*/
两个rdd按照相同的key进行匹配,
- 如果没有相同key,就匹配不上,比如”c”
- 如果key有重复的,那么数据会多次连接,比如”a”,
- 使用join时,如果两个rdd中key有多个重复,可能会出现笛卡尔积,数据量会几何形增长,导致性能降低。需谨慎使用。
cogroup
connect+group 分组连接。
把相同key的连接在一起,同一个rdd中的也进行连接
val rdd1 = sc.makeRDD(List(("a",3),("b",4),("c",8)))
val rdd2 = sc.makeRDD(List(("a",3),("b",4),("a",4)))
rdd1.cogroup(rdd2).collect().foreach(println)
结果:
(a,(CompactBuffer(3),CompactBuffer(3, 4)))
(b,(CompactBuffer(4),CompactBuffer(4)))
(c,(CompactBuffer(8),CompactBuffer()))
行动算子
触发任务的调度和作业(Job)的执行
转换算子的输出结果还是RDD,需要调用行动算子,才可以执行打印
行动算子的输出结果是 普通数据类型 如:Int 可以直接打印
collect
底层代码 调用的是环境对象的runjob方法
底层代码中会创建ActiveJob,并提交执行
val rdd = sc.makeRDD(List(1,2,3,4,1,2,3,4))
val array: Array[String] = rdd.collect()
reduce
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
// 聚合数据
val reduceResult: Int = rdd.reduce(_+_)
count
返回RDD中元素的个数
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
// 返回RDD中元素的个数
val countResult: Long = rdd.count()
first
返回RDD中的第一个元素
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
val firstResult: Int = rdd.first()
println(firstResult)
take
返回一个由RDD的前n个元素组成的数组
vval rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
// 返回RDD中元素的个数
val takeResult: Array[Int] = rdd.take(2)
println(takeResult.mkString(","))
takeOrdered
返回该RDD排序后的前n个元素组成的数组
val rdd: RDD[Int] = sc.makeRDD(List(1,3,2,4))
// 返回RDD中元素的个数
val result: Array[Int] = rdd.takeOrdered(2)
aggregate
分区的数据通过初始值和分区内的数据进行聚合,然后再和初始值进行分区间的数据聚合
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 8)
// 将该RDD所有元素相加得到结果
//val result: Int = rdd.aggregate(0)(_ + _, _ + _)
val result: Int = rdd.aggregate(10)(_ + _, _ + _)
fold
折叠操作,aggregate的简化版操作
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
val foldResult: Int = rdd.fold(0)(_+_)
countByKey && countByValue
val rdd: RDD[(Int, String)] = sc.makeRDD(List((1, "a"), (1, "a"), (1, "a"), (2, "b"), (3, "c"), (3, "c")))
// 统计每种key的个数
val result: collection.Map[Int, Long] = rdd.countByKey()
result.foreach(println) //(1,3)(2,1)(3,2)
//countByValue
val rdd = sc.makeRDD(List(1,1,2,4))
val cnt: collection.Map[Int, Long] = rdd.countByValue()
cnt.foreach(print) //(1,2)(2,1)(4,1)
save相关算子
将数据保存到不同格式的文件中
// 保存成Text文件
rdd.saveAsTextFile("output")
// 序列化成对象保存到文件
rdd.saveAsObjectFile("output1")
// 保存成Sequencefile文件
rdd.map((_,1)).saveAsSequenceFile("output2")
foreach
分布式遍历RDD中的每一个元素,调用指定函数
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
// 收集后打印,是Driver端内存集合的循环遍历方法,
//会按照分区收集打印,分区内有序 ,如图2
rdd.collect().foreach(println)
println("****************")
// 分布式打印,在executor端内存数据打印
rdd.foreach(println)
分布式打印,在executor端内存数据打印,
打印的数据顺序不确定,受节点的资源等影响
rdd.foreach(println) 过程如图:

按照分区收集打印,分区内有序
rdd.collect().foreach(println) 过程如图:

