目录
Apache Hadoop生态-目录汇总-持续更新
系统环境:centos7
Java环境:Java8
1:直接命令行启动(开发环境使用)
1.1:创建topic(可忽略,默认会自动创建)
如果kafka的topic不存在,
会自动创建单并行度topic
手动创建topic命令
kafka-topics.sh --zookeeper node100:2181/kafka --create --replication-factor 1 --partitions 1 --topic test_topic_db
查看topic
kafka-topics.sh --zookeeper node100:2181/kafka --list
1.2:命令行方式启动maxwell采集通道
cd /usr/local/maxwell-1.29.2
[root@node01 maxwell-1.29.2]# bin/maxwell --user='maxwell' --password='pw_maxwell' --host='192.168.1.100' --producer=kafka --kafka.bootstrap.servers=192.168.1.100:9092 --kafka_topic=test_topic_db
参数:
--kafka.bootstrap.servers=部署zk的节点,多个以,隔开
--kafka.bootstrap.servers=192.168.1.104:9092,192.168.1.102:9092
--filter 'exclude: *.*, include:test_maxwell.test'
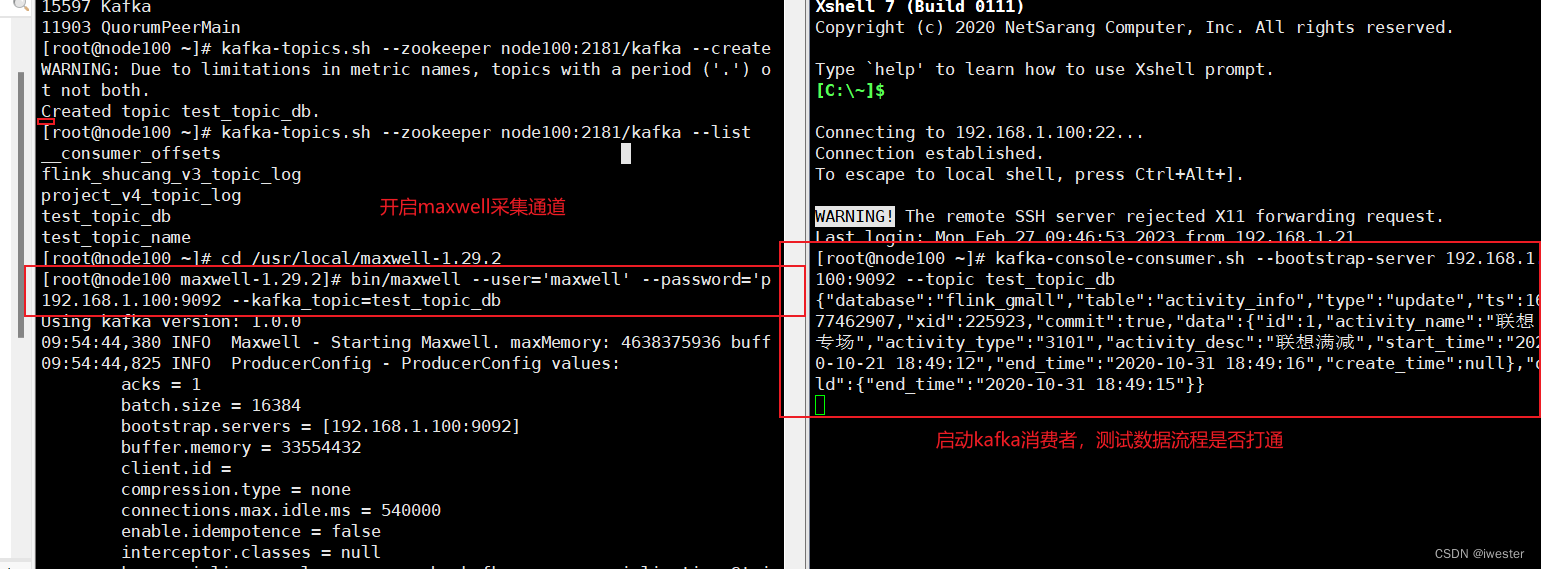
1.3:测试流程
打开 kafka 的控制台的消费者消费 maxwell通道数据
kafka-console-consumer.sh --bootstrap-server 192.168.1.100:9092 --topic test_topic_db修改开启binlog的数据库数据
2:通过配置文件启动maxwell(生产环境使用)
通过配置文件,方便管理
[root@node100 ~]# cd /usr/local/maxwell-1.29.2
[root@node100 ~]# sudo mkdir project_v3
[root@node100 ~]# sudo cp config.properties.example project_v3/kafka_config.properties
[root@node100 ~]# sudo vim project_v3/kafka_config.properties
log_level=info
# *** kafka ***
producer=kafka
# list of kafka brokers
kafka.bootstrap.servers=192.168.1.100:9092
# kafka.bootstrap.servers=hosta:9092,hostb:9092 多个的写法
# 控制入kafka的过滤条件
# filter= exclude: *.*, include: flink_gmall.test_table # 排除所有,只采集flink_gmall.test_table表的数据
kafka_topic=test_topic_db_02
# 控制数据分区模式-表 [database, table,primary_key, transaction_id, column]
producer_partition_by=table # 同一张表的数据,进入同一个分区
# mysql配置
host=192.168.1.100
user=maxwell
password=pw_maxwell
jdbc_options=useSSL=false&serverTimezone=Asia/Shanghai
2.1:kafka的分区控制
我们一般都会用maxwell监控多个mysql库的数据,然后将这些数据发往kafka的一个主题 Topic,并且这个主题也肯定是多分区的,为了提高并发度。
producer_partition_by=database # 同一个数据库数据,进入同一个分区
手动创建topic命令
kafka-topics.sh --zookeeper node100:2181/kafka --create --replication-factor 1 --partitions 3 --topic test_topic_db[root@node100 ~]# sudo vim project_v3/kafka_config.properties
# *** kafka ***
kafka_topic=test_topic_db_02
# 控制数据分区模式,可选模式有 库名,表名,主键,列名
#producer_partition_by=database # [database, table,primary_key, transaction_id, column]
producer_partition_by=database # 同一个数据库数据,进入同一个分区
# 如果根据字段自动分区,需要指定字段,这个字段名必须存在
producer_partition_by=column
producer_partition_columns=name # 这里写字段名
2.2:启动maxwell采集通道
cd /usr/local/maxwell-1.29.2
bin/maxwell --config ./project_v3/kafka_config.properties
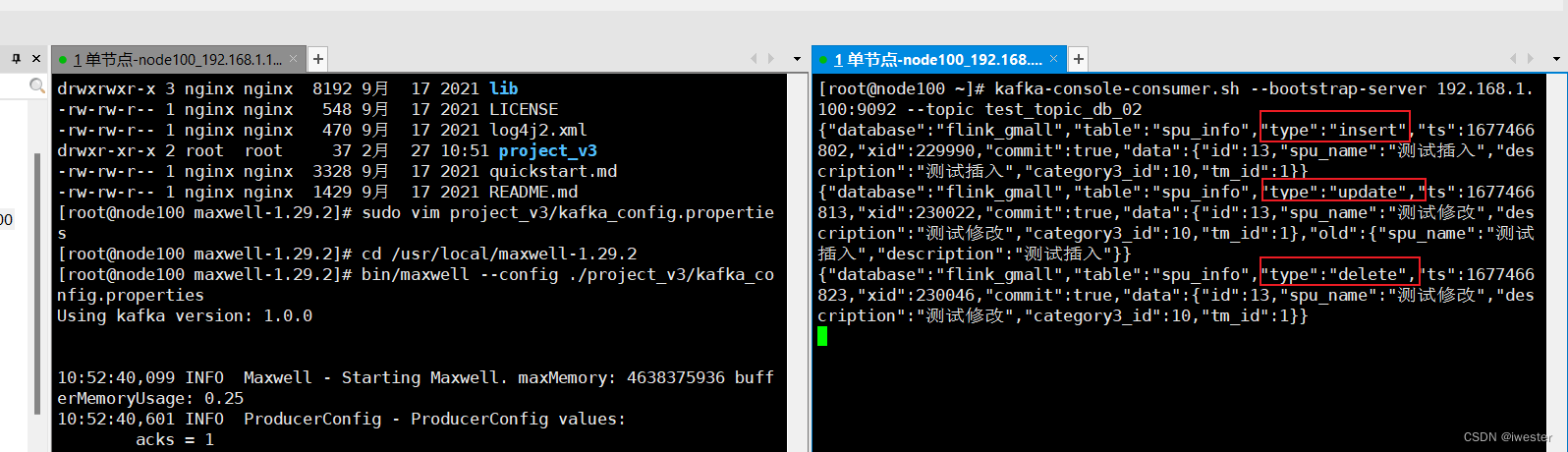
2.3:测试流程
打开 kafka 的控制台的消费者消费 maxwell通道数据
kafka-console-consumer.sh --bootstrap-server 192.168.1.100:9092 --topic test_topic_db_02修改开启binlog的数据库数据
版权声明:本文为web_snail原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。