1.Page–页
为了避免一条一条读取磁盘数据,
InnoDB采取了Page(页)的方式
作为磁盘和内存之间交互的基本单位
一页的大小一般是
16KB
那么我们来看看Page的结构
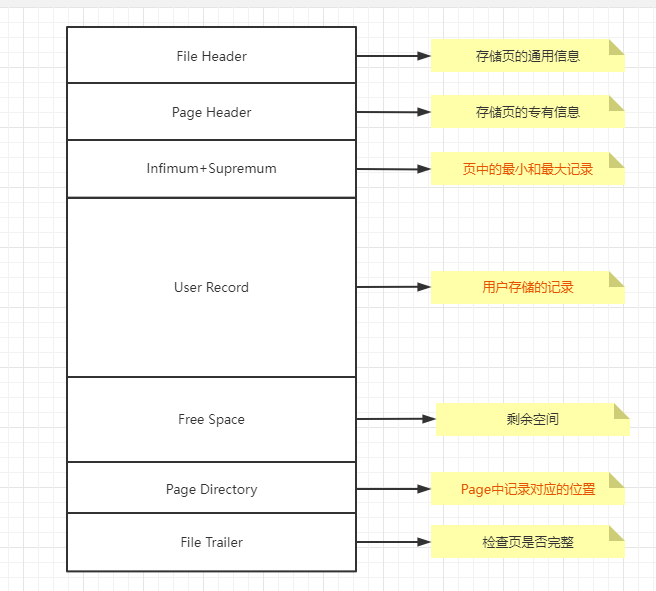
以上就是Page的基本结构,可以看出我们目前最关心的
User Record(我们insert的记录)
在page中是什么方式存储的
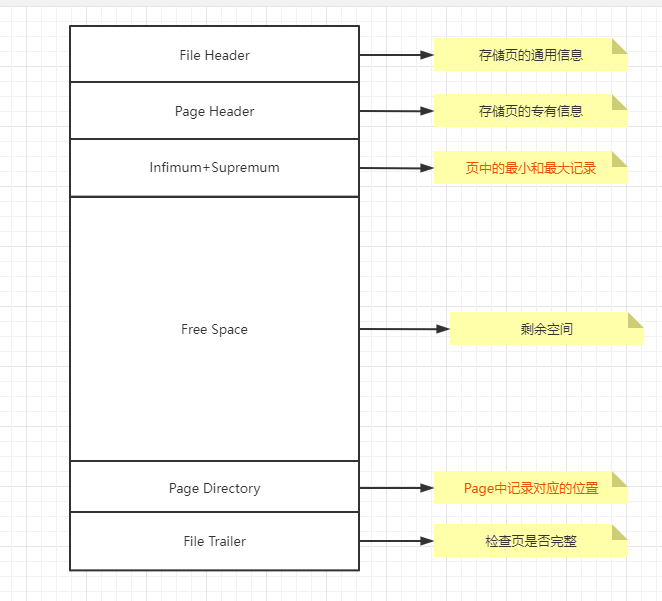
首先我们会申请一个Page的空间内存,那么我们User Record肯定为空,然后所有的都是Free Space,以下就是默认申请的一个Page空间
比如如果我们Page刚好塞满了记录,那么我们Free Space自然就没有,所有的都在User Record中存储,见下图
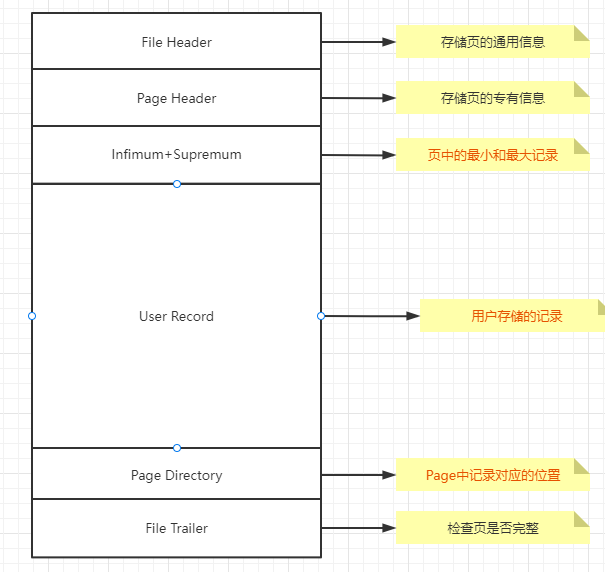
从以上可以总结出,接下来我们就引出了
User Record中记录的概念
,我们再来看看Record又有哪些结构呢
2.Record
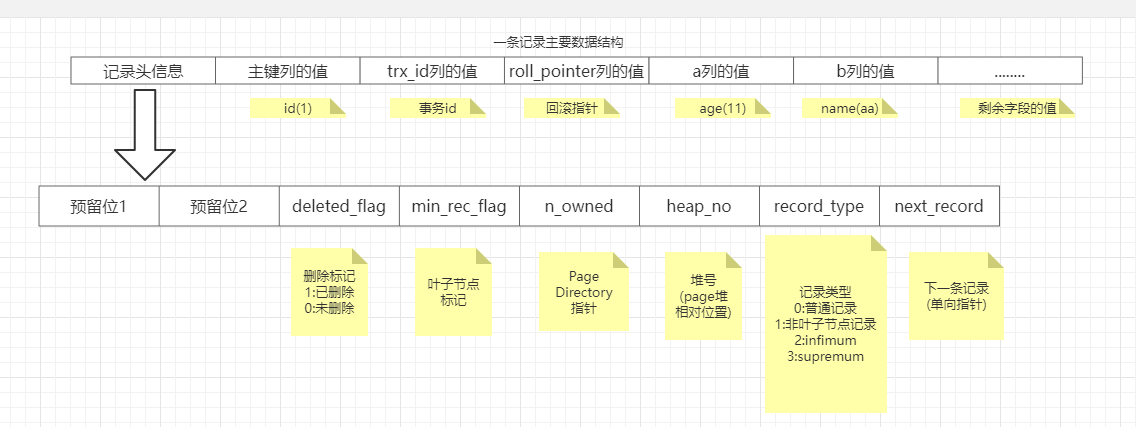
以上就是Record中基本结构,那我们演示下insert记录之后,UserRecord是怎么记录的呢

以上就是insert记录的时候,page页存储记录的方式
(默认主键正序排序方式)
,那么如果删除其中一条记录会有什么变化呢
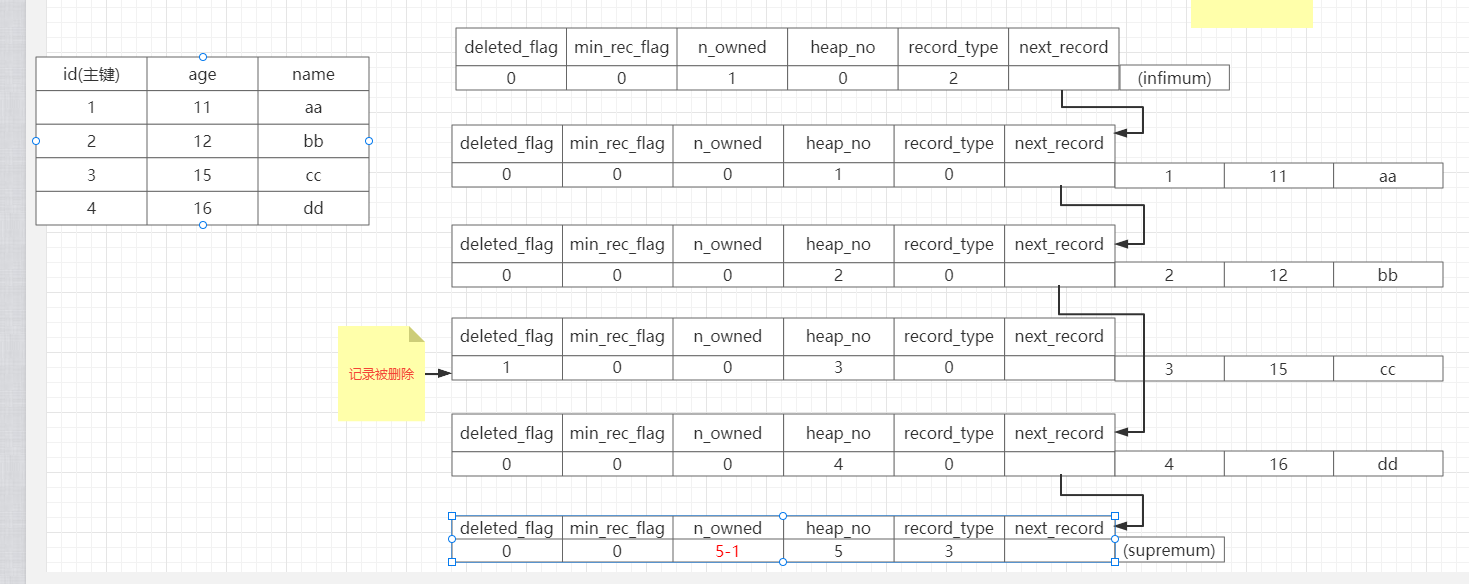
直接将需要删除的记录
delete_flag置位1
,next_record置位下一位record,同时将最大的
n_owner-1
以上来看,我们往Page(16KB)里面插入record的时候,可能插入的record已经上万,而且
记录都是单向指针的方式
,那么我们如果查询的
记录刚好就是最后一条
,那我们是不是需要从第一条记录遍
历查询到最后一条再返回
?基于这个问题,Page Directory就出现了
3.Page Directory
主要是为了帮助我们查询的时候能够
迅速定位到记录的位置
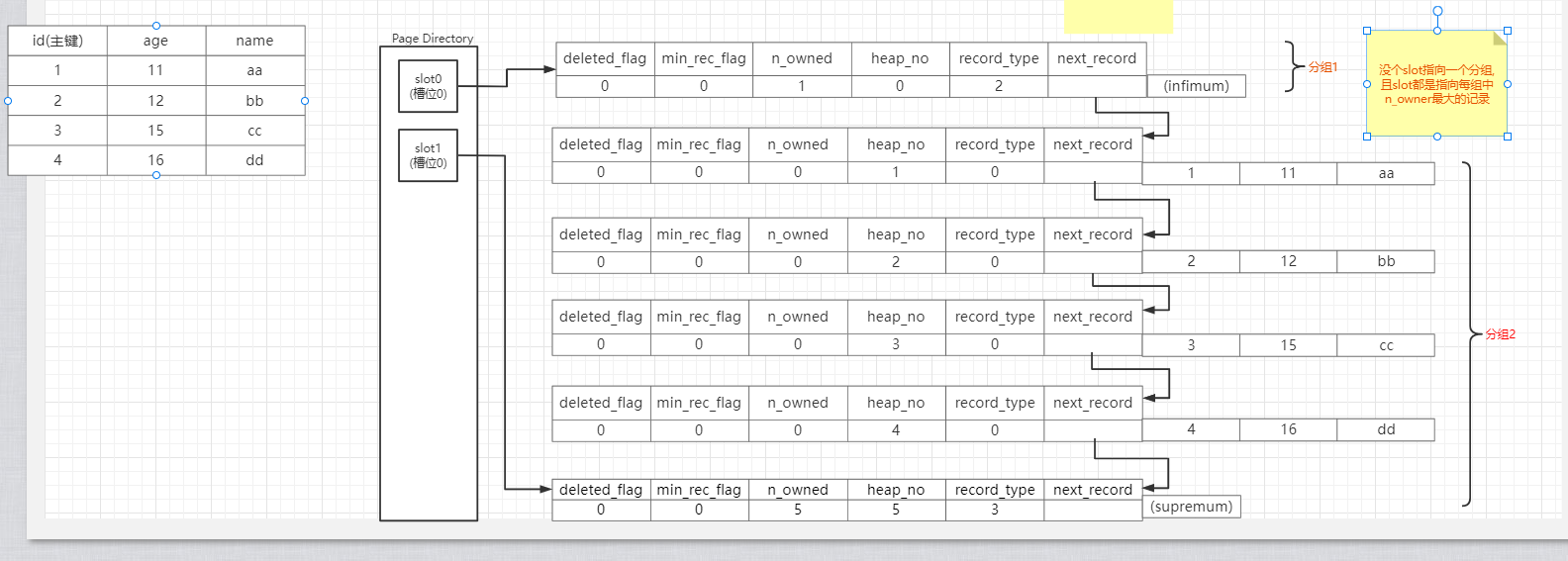
基于Page Directory之后,记录存储的数据格式,一般每组的记录
1-8条,
那么我们再来模拟分组2已经满了的情况
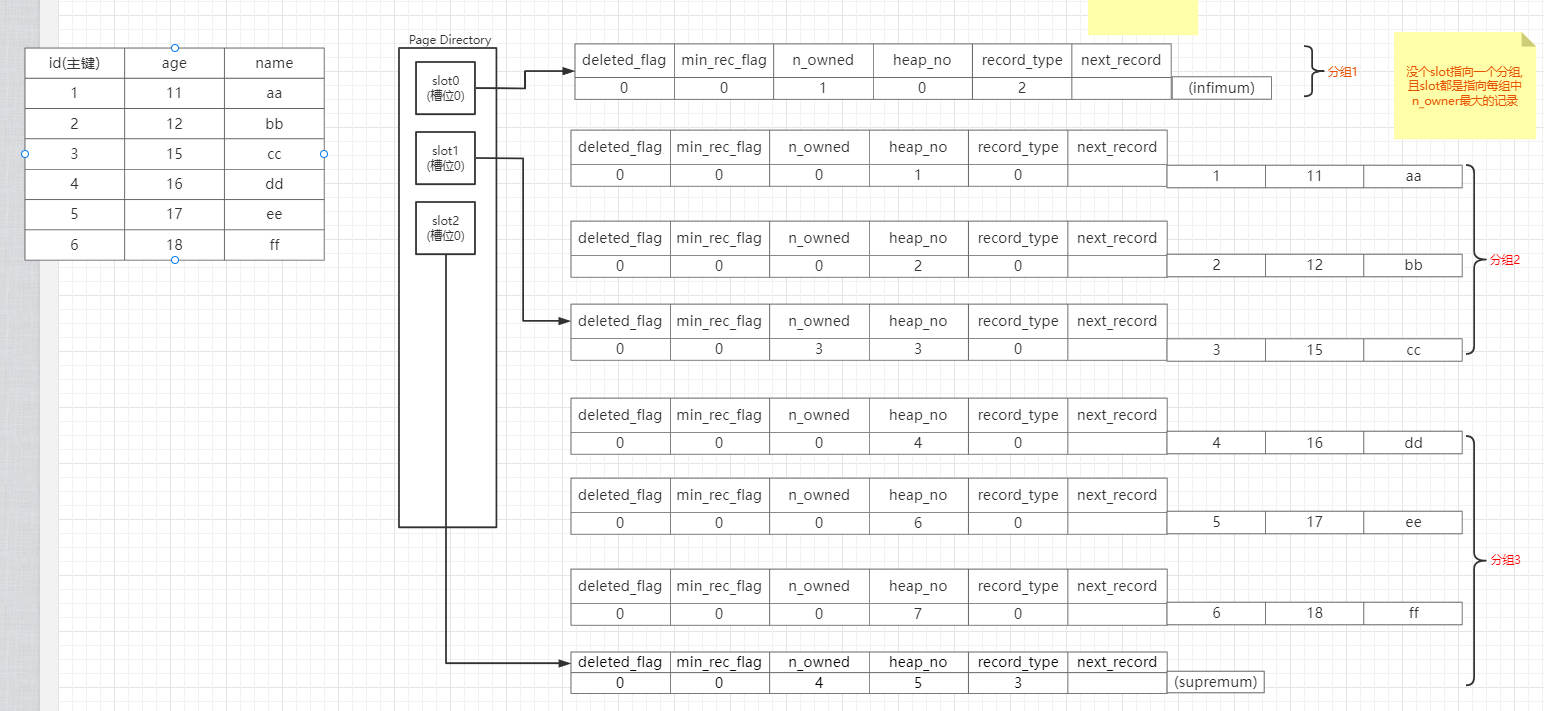
现在看来我们已经有个对个slot,这样查找的时候,我们就可以
通过page_directory二分查找定位slot
,再进入没个分组中,循环遍历查找效率就快多了
(每组中的记录一般1-8条)
InnoDB基于Page查找记录的方式:
- 通过二分法确定槽
- 通过记录的next_record属性遍历该槽所在的组中的各个记录
那么接下来又引出新的问题,我们Page(16KB)大小,总有
存满的时候,这个时候就会申请新的Page
,那么我们现在就有了
多个Page
,那么我们又要怎么来定位到具体的记录呢,接下来引出Index索引的概念来解决以上问题
4.Index
以上总结到我们的记录都是
存储在Page上且记录都是min_rec_flag叶子节点
,那我们是不是就可以使用
非叶子结点来存储索引
来指向具体的Page(叶子节点)
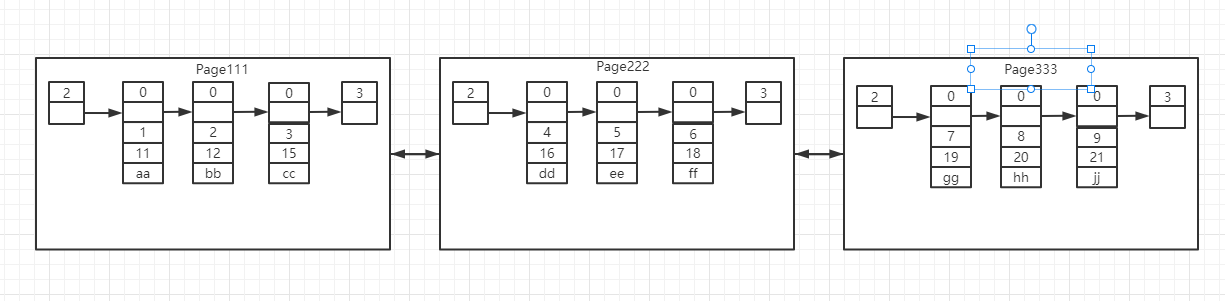
以上正常来讲就是多个Page存储记录,看看InnoDB有哪些方式来解决呢
4.1主键索引

主要是建立
非叶子节点记录(索引)
来指向page号,同时非叶子节点的记录不需要存储太多的数据
(page中最小的主键和page号)
,所以来看
基于主键查询
,我们已经可以快递定位到记录的位置
4.2二级索引 — 非主键
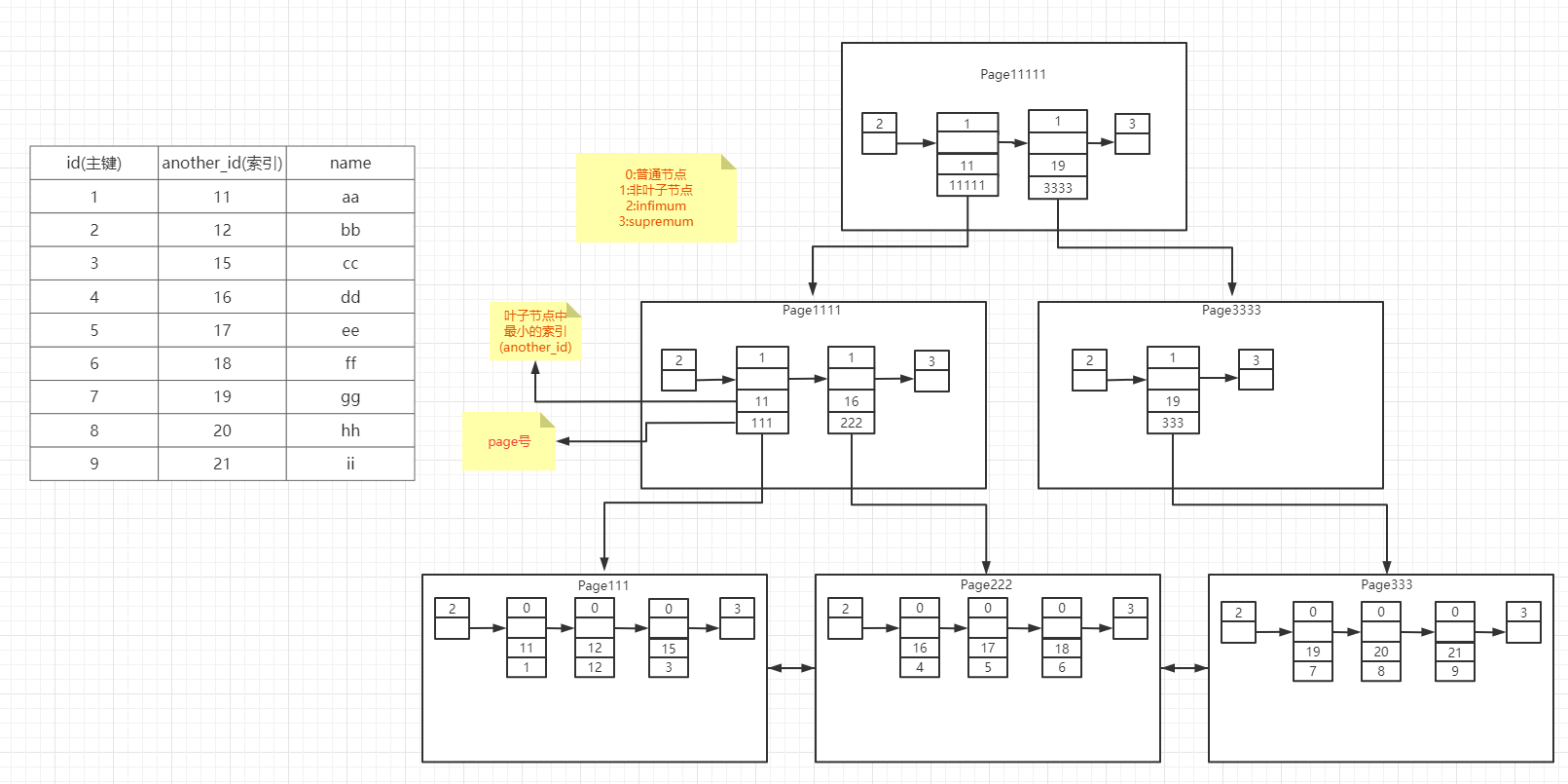
以上我们给
another_id创建了索引
(默认正序排序),那么我们基于another_id查询就可以快递定位到
记录中的主键
,同时我们就可以再
通过主键索引
可以快速定位到我们所需要的记录
4.3联合索引

通过
another_id和name
建立联合索引,这种情况InnoDB会
先左原则
排序,
通过another_id和name
来定位到
唯一的主键记录
如果我们
二级索引的值不唯一
的话,那么innoDB就无法定位唯一的主键记录,那么我们就需要保证记录的唯一性

我们以上就是通过
索引值+主键值+page号
来定位记录的唯一性
5.Buffer Pool(缓冲池)
目的: 由于数据页存储在表空间(磁盘文件),我们每次操作都需要涉及到一次IO操作,
为了减少IO操作
,我们会将数据页存储到Buffer Pool(缓冲池)中
基本结构:

Mysql启动的时候,自动为Buffer Pool申请一片连续的内存空间(链表结构),默认128Mb
磁盘数据加载到Buffer Pool流程:
1.从free链表中获取一个
空的控制块
2.通过控制块,找到对应的缓冲页,把对应的数据信息加载到缓冲页
3.把控制块从free链表中移除,并且count-1
5.1free链表
以上总结到磁盘数据加载到Buffer Pool需要通过free链表,那么free链表
目标:
存储Buffer Pool中所有的空的控制块以及数量
基本结构:

问题:
那么我们知道Buffer Pool中存储的都是缓存数据,如果我们对数据页进行修改操作,是不是导致Buffer Pool和磁盘数据不一致,那么接下来flush链表登场了
5.2flush链表
目的:
存储Buffer Pool中缓冲页修改后对应的控制块
基本结构:
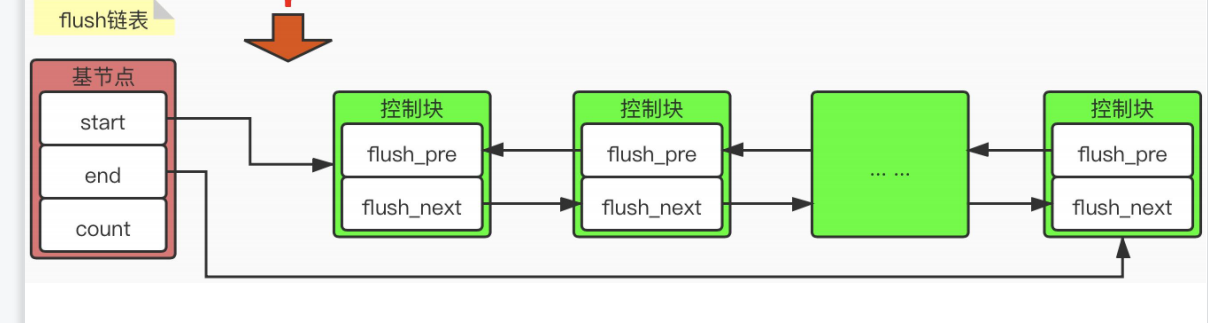
每次
修改缓冲页数据
的时候,Mysql会将对应的代码块加载到flush链表中,并且count+1
问题:
那么我们都知道Buffer Pool只要是为了避免IO操作,从而在缓冲中加载数据来提升效率,那么我们缓冲只有128Mb,
如果每次查询的数据在缓冲中都不存在
,这个时候Buffer Pool岂不是没有任何意义,所以我们
Buffer Pool需要存储一些常用的数据页
,这个就可以尽量避免这个问题了,这个时候LRU出现了
5.3BRU链表
目的:
存储最近最少被使用的缓冲页对应的代码块,
如果一条数据很少被访问,那么我们就可以将该数据刷新到磁盘中
基本结构:
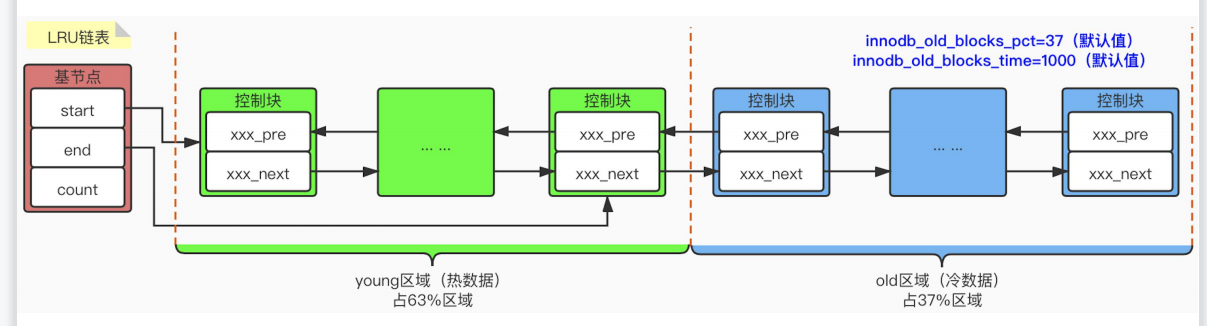
young区域: 最近访问的数据页
old区域: 最近很少被访问的代码块
问题:
1.当你顺序的访问了一个区中大于 innndb_read_ahead_threshold=56个数据页时,Mysql会自动的把下一个区所有的数据页加载到LRU链表
2.当Buffer Pool中存储着一个区中13个连续的数据页时,你再去这个区里面读取,MySQL就会将这个区里面所有的数据页都加载进Buffer Pool中的LRU链表
3.全表扫描,如果数据很多的话,那么这些数据页会全部加载到LRU链表,并且将常用的数据全部挤出去,这样LRU链表可能就不是常用的数据了
1.2问题解决:
预读主要涉及问题就是,每次加载的时候都会加载一堆我们不需要的数据,那么Mysql会自动将这些数据
加载到Old区域(冷数据区)
,对于整个young区域(热数据区)是没有影响的 ==
分区方式解决
3.问题解决
如果全表扫描数据的话,将一大批数据加载到old区域时,然后在
不到1s内
你又访问了它,那在这段时间内被访问的缓存页并不会被提升为热数据。 这个1s由参数innodb_old_blocks_time控制。
Buffer Pool刷新方式
1.从flush链表(Buffer Pool中被修改的数据页)刷新一部分数据到磁盘(定时)
2.从BRU链表的Old区域(冷数据区)中刷新一部分数据到磁盘(定时)
刷新完之后,我们Buffer Pool缓存的基本都是
最新且常用的数据页
6.undo log
目的: 为了保证
事务的原子性
,但是有些情况会造成异常事务回滚,所以Mysql为了解决
事务一致性问题
而记录的日志,称之为undo log
6.1事务id(
数据页中record的trx_id
)
事务id的分配
1.
只读的事务(不可见)
(临时表 ==> Mysq在处理事务的时候,需要建立临时表来处理,最后再将临时表删除)
2.
读写的事务
第一次对表记录记录增删改之后,才会分配事务id,
事务id默认0
事务的开启
1.只读事务
start transaction read
2.读写事务
start transaction write read = begin
6.2 insert操作对应的undo日志
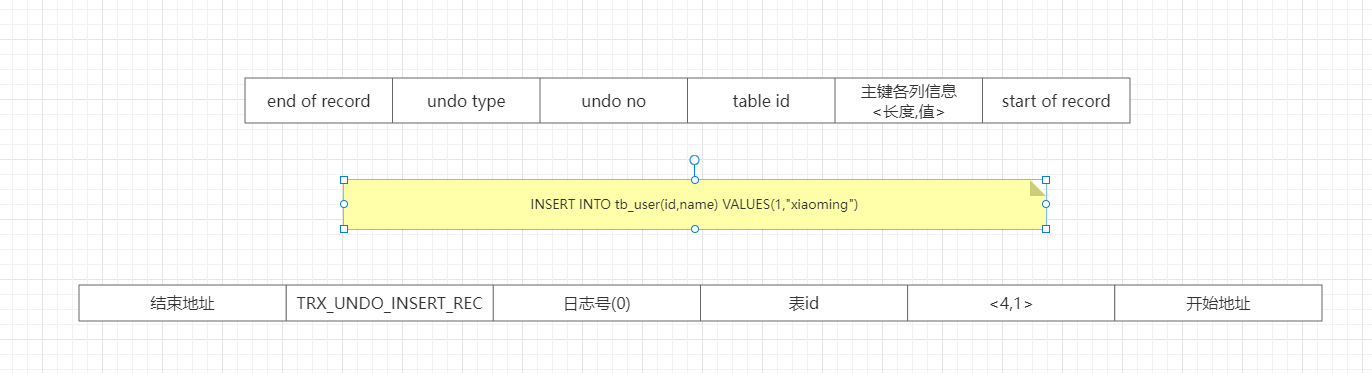
end of record: 本条undo log页面结束地址(下一条开始地址)
end of record: 本条undo log页面开始地址
undo type: 日志类型
TRX_UNDO_INSERT_REC 新增操作Undo 日志类型
TRX_UNDO_DEL_MARK_REC 删除操作Undo 日志类型
TRX_UNDO_UPD_EXIST_REC 更新操作Undo 日志类型
undo no: 日志编号(即表的主键)
table id: 表id(数据库表的唯一标识)
由于insert操作如果需要回滚的操作的话,就是把insert的记录根据主键删除即可,所以insert操作的时候,undo日志不需要存储太多的数据
6.3Delete操作对应的Undo日志
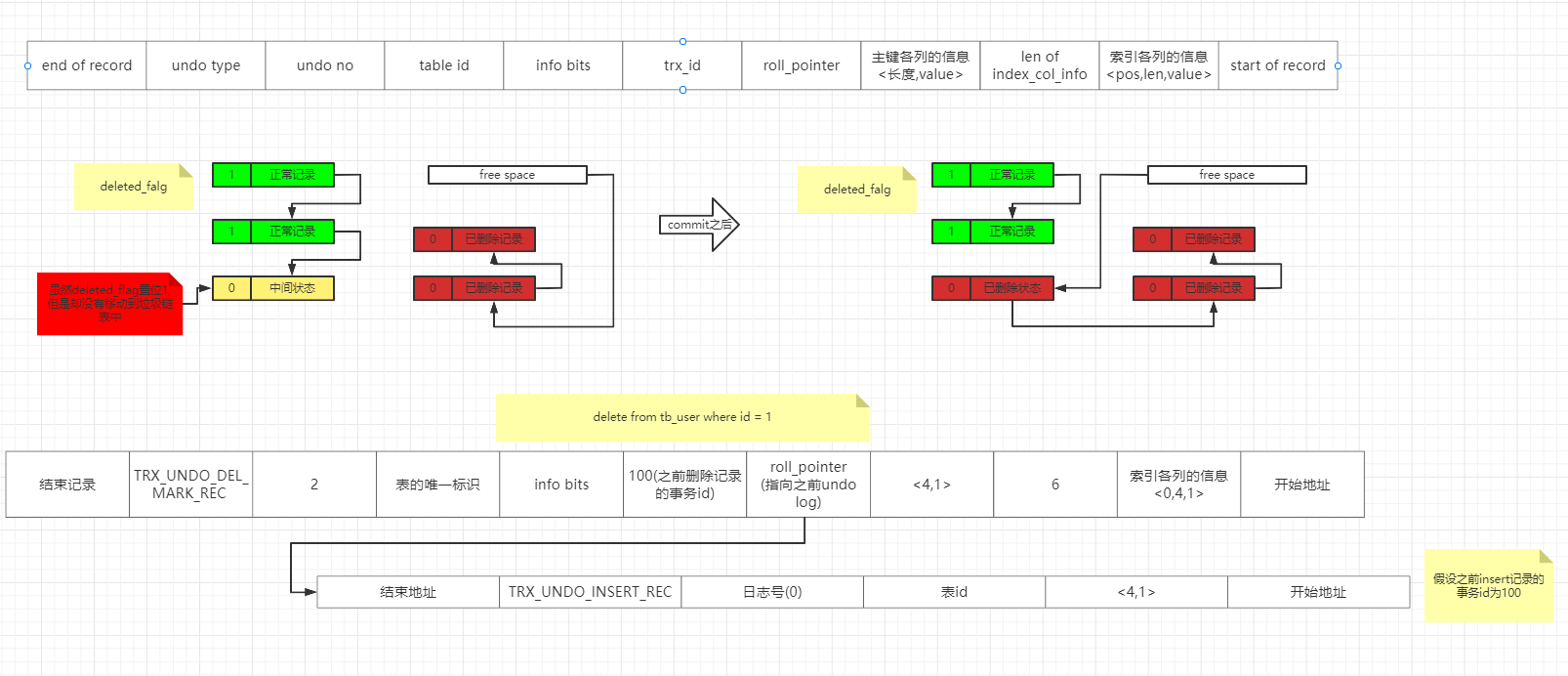
trx_id: 之前删除记录的事务id
roll_pointer: 指向之前记录的undo_log
6.4Update操作对应的Undo日志
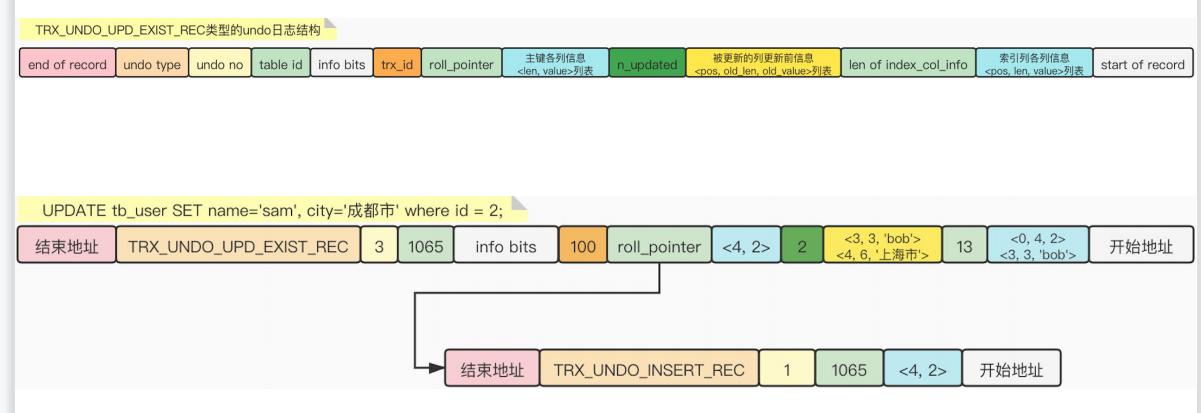
n_updated: 被更新的列的数量
以上是主键未更新的情况
主键更新:
1.通过delete mark删除之前的数据
2.根据更新后的记录,插入到主键索引中
7.事务
7.1ACID
Atomicity原子性:
某个操作,要么全执行,要么全回滚
Consistency一致性:
数据库数据符合一致性
Isolation隔离性:
多个事务访问相同数据,执行顺序有一定的规律,彼此不干涉
Durability:
对数据所做的修改都应该保存到磁盘
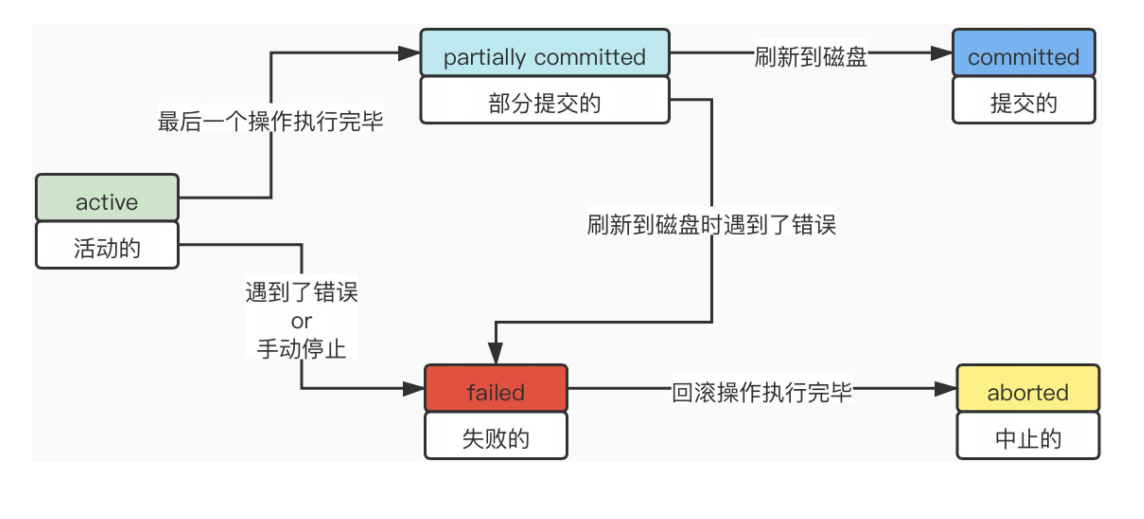
事务状态:
脏读: 读取到
另一个未提交
的事务
修改后
的数据
不可重复读: 修改了
另一个未提交
事务
读取的
数据
幻读: 如果一个事务
根据某些搜索条件
查询了一些记录,但
该事务未提交
,
另一个事务写入了符合搜索条件的数据,
此时就发生了幻读
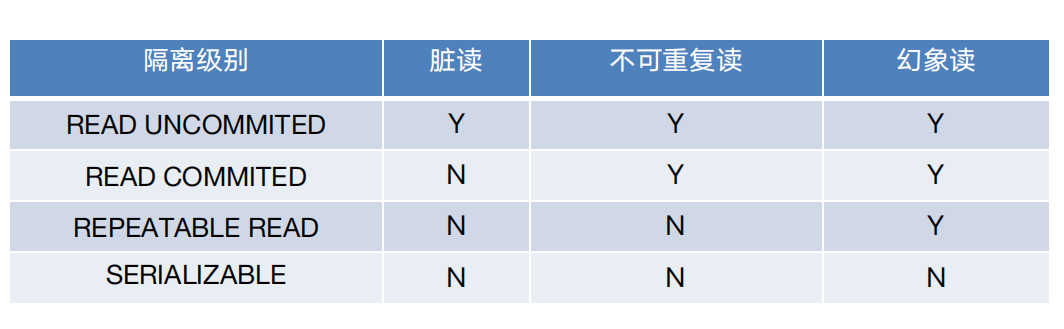
隔离级别:
8.MVCC(Muti-Version Concurrency Control)
多版本并发控制.利用记录的
版本链和Read View
,来控制并发事务访问相同记录时的行为
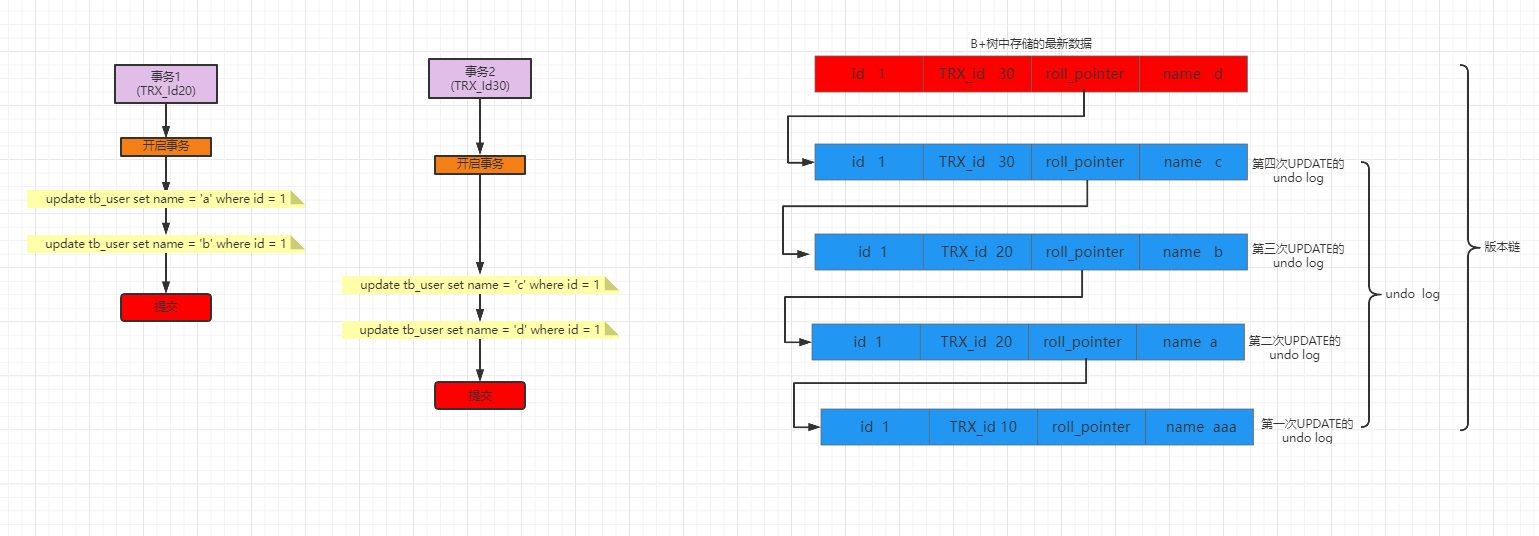
8.1版本链
在每次更新记录的时候,会将旧值放到undo log中,随着更新日志的增多,所有的版本都会被roll_pointer属性连接成一个链表,随之称为
版本链
流程图:
8.2 Read View
定义:
一致性视图,用来判断版本链中哪个版本是当前事务可见的
m_ids:
在生成Read View的时候,当前系统中
活跃的读写事务
的事务id列表
min_trx_id:
在生成Read View的时候,当前系统中活跃的读写事务中
最小的事务id,
也就是m_ids的最小值
max_trx_id:
在生成Read View的时候,系统应该分配
下一个事务的事务id
creator_trx_id:
生成该Read View
的事务的事务id
如何通过Read View来判断记录的某个版本是否可见呢
1.如果
trx_id = creator_trx_id
,说明当前事务
正在访问自己修改过的记录
,所以该版本可以被当前事务访问
2.如果
trx_id < min_trx_id
,说明
访问的事务在当前事务生成Read View之前已经提交了
,所以该版本可以被当前事务访问
3.如果
trx_id >= max_trx_id
,说明
访问的事务是在当前事务生成生成Read View之后才开启
,所以该版本不可以被当前事务访问
4.如果
trx_id in m_ids
,说明创建Read View时,该版本的事务还是活跃的,该版本不可访问
5.如果
trx_id not in m_ids
,说明创建Read View时,该版本的事务已经被提交了,该版本可以访问
如果某个版本的数据
对当前事务不可见
,那就顺着版本链找到
下一个版本的数据
,并且继续执行以上步骤来判断记录的可见性,直到版本链中的最后一个版本
Read View生成时机
Read COMMITED 和 REPEATABLE READ隔离级别之间一个非常大的区别就是—– 他们生成
Read View的时机不同
READ COMMITED: 在一个事务中,
每次读取记录
都会生成一个Read View

以上图可以看出,
READ COMMITED隔离级别解决脏读
(读未提交)
的问题
REPEATABLE READ: 在一个事务中,
只在第一次读取记录
的时候生成一个Read View

以上可以看出
REPEATABLE READ 隔离级别可以解决不可重复读
(修改了另一个未提交事务读取的数据)