写在前面
多核处理器和中断程序,使得不同的进程间可以并发的执行、访问计算机系统的资源。当不同的进程需要访问同一个共享资源(比如同时访问内存块)时,进程间会形成竞态,当出现这种情况时,可能会导致数据丢失或者错误。锁的出现,保证了临界区在某一时刻只有一个进程能够访问,而其余的进程若要访问临界区,只能等待在临界区内的进程释放锁,从而实现进程间的互斥。另一方面,锁使得进程间只能够串行地执行代码,降低了系统的效率。
锁会带来的另外一个问题是死锁。对于两个进程A和B,两个锁C和D,若进程A持有锁C,进程B持有锁D,此时进程A需要获取锁D,而进程B需要获得锁C才能够继续执行下去,但是这两把锁目前被对方拥有,这两个进程同时等待对方释放锁,两个进程形成了互相等待的局面而导致无法继续执行,这种现象称为死锁。为了解决死锁的问题,一个办法是对获取锁的顺序进行规定,所有的进程都必须按照既定的顺序获取锁。
此次实验是对系统进行优化,从而减少对锁的竞争,以提高系统的效率。
实验部分
一 Memory allocator
xv6中,用了一个链表将空闲的内存页面串起来,对不同的CPU,都需要互斥地访问该链表。此实验是希望对每一个CPU都分配一个memory allocator,只有当该CPU的memory allocator没有多余的内存页面时,再去获取别的CPU的内存页面。
1 将结构体变量改为结构体数组,数组长度为NCPU。
struct {
struct spinlock lock;
struct run *freelist;
} kmem[NCPU];2 在初始化的过程中,需要将从end到PHYSTOP内存地址进行平均划分,分给不同的CPU。其中freerange函数中要增加一个参数,表明cpuid。
void
kinit()
{
for(int i=0;i<NCPU;i++){
initlock(&kmem[i].lock, "kmem");
uint64 start_page,end_page;
start_page=(uint64)end+(PHYSTOP-(uint64)end)/NCPU*i;
end_page=start_page+(PHYSTOP-(uint64)end)/NCPU;
freerange((void*)start_page,(void*)end_page,i);
}
}
void
freerange(void *pa_start, void *pa_end,int i)
{
char *p;
p = (char*)PGROUNDUP((uint64)pa_start);
for(; p + PGSIZE <= (char*)pa_end; p += PGSIZE)
kfree_init(p,i);
}
void
kfree_init(void *pa,int i){
struct run *r;
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
// Fill with junk to catch dangling refs.
memset(pa, 1, PGSIZE);
r = (struct run*)pa;
acquire(&kmem[i].lock);
r->next = kmem[i].freelist;
kmem[i].freelist = r;
release(&kmem[i].lock);
} 3 调用kfree和kalloc时,需要获取cpuid,从而可以得到该cpu对应的memory allocator。对于kalloc,当某个cpu没有多余的空闲内存页面时,需要从别的cpu的空闲页面链表中获取。
int getcpuid(){
int cpu;
push_off();
cpu=cpuid();
pop_off();
return cpu;
}
void
kfree(void *pa)
{
struct run *r;
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
// Fill with junk to catch dangling refs.
memset(pa, 1, PGSIZE);
r = (struct run*)pa;
int cpuid=getcpuid();
acquire(&kmem[cpuid].lock);
r->next = kmem[cpuid].freelist;
kmem[cpuid].freelist = r;
release(&kmem[cpuid].lock);
}
void *
kalloc(void)
{
struct run *r;
int cpuid=getcpuid();
acquire(&kmem[cpuid].lock);
r = kmem[cpuid].freelist;
if(r)
kmem[cpuid].freelist = r->next;
else{
for(int i=0;i<NCPU;i++){
if(kmem[i].freelist){
acquire(&kmem[i].lock);
r=kmem[i].freelist;
kmem[i].freelist=r->next;
release(&kmem[i].lock);
break;
}
}
}
release(&kmem[cpuid].lock);
if(r)
memset((char*)r, 5, PGSIZE); // fill with junk
return (void*)r;
}二 Buffer cache
当进程需要访问文件时,需要从磁盘读取文件对应的磁盘块,磁盘的操作非常耗时,如果需要反复访问同一个磁盘块,每次都需要从磁盘中进行调用,这会极大地降低系统的效率。一种办法是将磁盘块进行缓存,每次需要调用一个磁盘块时,优先查看缓存中是否存在该磁盘块,如果存在则直接从缓存中读取,效率会提高,只有当缓存中不存在相应的磁盘块,再从磁盘中调用到缓存中。
文件系统不同于内存,不同的进程可能会同时访问同一个文件,需要读取同一个磁盘块,因此不能够为每一个CPU分配一个缓存。为了减少由于竞态导致的竞争,可以将缓存设置为哈希表,磁盘块根据磁盘块编号映射到哈希表中,哈希表中根据键值设置哈希桶,并为每一个哈希桶配置一个锁。这样一来,如果不同的进程访问的磁盘块的键值不同,就可以同时访问缓存,减少了竞态,提高了系统的效率。
1 将缓存设置为长度为13的哈希表,并为每一个哈希表的键值设置一个哈希桶,且为每一个哈希桶设置一个锁。
struct {
struct spinlock lock;
struct buf buf[NBUF];
struct spinlock bucketlock[13];
// Linked list of all buffers, through prev/next.
// Sorted by how recently the buffer was used.
// head.next is most recent, head.prev is least.
struct buf bucket[13];
} bcache;2 初始化缓存时,将每一个桶的锁以及整一个缓存的锁都进行初始化。同时为每一个桶平均分配缓存,每一个桶都是一个循环双链表,块越在桶的前面表示块最近被使用过。
void
binit(void)
{
struct buf *b;
initlock(&bcache.lock, "bcache");
for(int i=0;i<13;i++){
initlock(&bcache.bucketlock[i],"bcache");
bcache.bucket[i].next=&bcache.bucket[i];
bcache.bucket[i].prev=&bcache.bucket[i];
for(b=bcache.buf+NBUF/13*i;b!=bcache.buf+NBUF/13*(i+1);b++){
b->next=bcache.bucket[i].next;
b->next->prev=b;
b->prev=&bcache.bucket[i];
bcache.bucket[i].next=b;
}
}
}3 在得到块时,如果缓存中有块,则直接获得该块。如果缓存中没有块,但是对应的哈希桶存在空闲的最久未使用的缓存块,则直接设置该缓存块。否则从其他的哈希桶中找出空闲的最久未使用的缓存块。
static struct buf*
bget(uint dev, uint blockno)
{
struct buf *b;
int index=blockno%13;
acquire(&bcache.bucketlock[index]);
// Is the block already cached?
for(b = bcache.bucket[index].next; b != &bcache.bucket[index]; b = b->next){
if(b->dev == dev && b->blockno == blockno){
b->refcnt++;
release(&bcache.bucketlock[index]);
acquiresleep(&b->lock);
return b;
}
}
// Not cached.
// Recycle the least recently used (LRU) unused buffer.
for(b = bcache.bucket[index].prev; b != &bcache.bucket[index]; b = b->prev){
if(b->refcnt == 0) {
b->dev = dev;
b->blockno = blockno;
b->valid = 0;
b->refcnt = 1;
release(&bcache.bucketlock[index]);
acquiresleep(&b->lock);
return b;
}
}
release(&bcache.bucketlock[index]);
acquire(&bcache.lock);
for(int i=0;i<13;i++){
if(i==index) continue;
acquire(&bcache.bucketlock[i]);
for(b = bcache.bucket[i].prev; b != &bcache.bucket[i]; b = b->prev){
if(b->refcnt == 0) {
acquire(&bcache.bucketlock[index]);
b->dev = dev;
b->blockno = blockno;
b->valid = 0;
b->refcnt = 1;
b->next->prev=b->prev;
b->prev->next=b->next;
release(&bcache.bucketlock[i]);
b->next=&bcache.bucket[index];
bcache.bucket[index].prev->next=b;
b->prev=bcache.bucket[index].prev;
bcache.bucket[index].prev=b;
release(&bcache.bucketlock[index]);
release(&bcache.lock);
acquiresleep(&b->lock);
return b;
}
}
release(&bcache.bucketlock[i]);
}
release(&bcache.lock);
panic("bget: no buffers");
}4 释放某个块时,只要获取对应哈希桶的锁即可
void
brelse(struct buf *b)
{
if(!holdingsleep(&b->lock))
panic("brelse");
releasesleep(&b->lock);
int index=b->blockno%13;
acquire(&bcache.bucketlock[index]);
b->refcnt--;
if (b->refcnt == 0) {
// no one is waiting for it.
b->next->prev = b->prev;
b->prev->next = b->next;
b->next = bcache.bucket[index].next;
b->prev = &bcache.bucket[index];
bcache.bucket[index].next->prev = b;
bcache.bucket[index].next = b;
}
release(&bcache.bucketlock[index]);
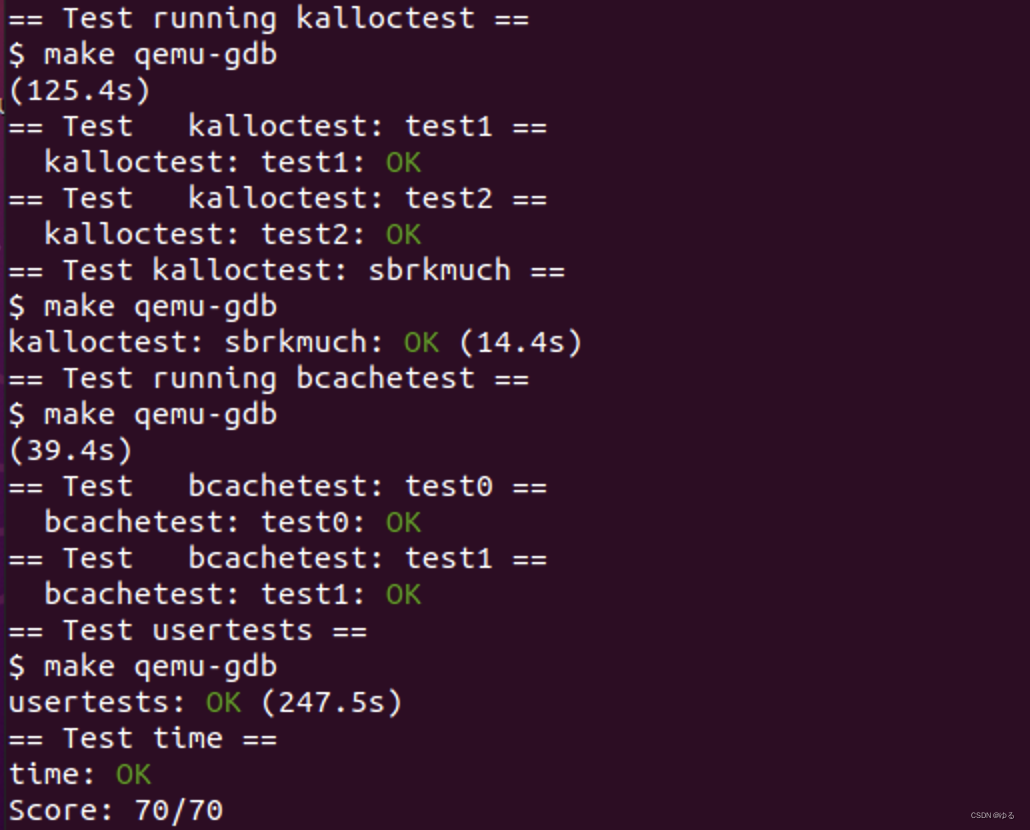
}三 实验结果