hadoop集群数据存储
Stepping into the world of Big Data and Distributed Computing
进入大数据和分布式计算世界
Recently, I started my journey as the
ARTH Learner
in the program
“ARTH -2020”
under the guidance of ‘The World Record Holder
Mr. Vimal Daga
Sir
’. As it is just the starting phase of my journey as the ARTH learner, here I’m sharing some learnings.最近,在
“
世界纪录保持者
Vimal Daga
Sir先生
”的指导下,我以
“ ARTH -2020”
计划的
身份
开始了
ARTH学习者的
旅程。 因为这只是我作为ARTH学习者的旅程的开始,所以我在这里分享一些学习经验。
每天在互联网上创建多少数据?
(
How much data is created on the Internet each day ?
)
Ever thought about how much data is created every day? So how much data is produced every day in this techie world? Before getting into the depth of it, here is a overview.
有没有想过每天创建多少数据? 那么,在这个技术世界中每天产生多少数据? 在深入探讨之前,这里有一个概述。

大数据增长统计
(
Big Data Growth Statistics
)
The stats of data growth in 2020 tell us that big data is rapidly growing and the amount of data generated each day is increasing at an unprecedented rate. The majority of the world’s data has emerge about in only last few years. If you’ve wondered how much data the average person uses per month, you can start by looking at how much data is created every day in 2020 by the average person. This currently stands at
2.5 quintillion bytes per person, per day
(there are 18 zeroes in a quintillion. Just for your information).
2020年的数据增长统计数据告诉我们,大数据正在快速增长,每天生成的数据量正以前所未有的速度增长。 世界上大多数数据仅在最近几年才出现。 如果您想知道普通人每月使用多少数据,可以先查看2020年普通人每天创建多少数据。 目前
,
这是
每人每天2.5亿字节(每100亿中
有18个零。仅供参考)。

In the last two years alone, around 90% of the world’s data has been created. By the end of 2020, around
44 zettabytes
will make up the entire digital universe. Furthermore, it is estimated that around
463 exabytes of data will be generated each day by humans as of 2025.
These impressive technology growth stats for big data show no sign of slowing down. Thus, Big Data is the future of the world.
仅在过去的两年中,就创建了大约90%的世界数据。 到2020年底,整个数字世界将构成约
44 ZB
。 此外,据估计,到
2025年,人类每天将产生
大约
463艾字节的数据。
这些令人印象深刻的大数据技术增长统计数据没有放缓的迹象。 因此,大数据是世界的未来。
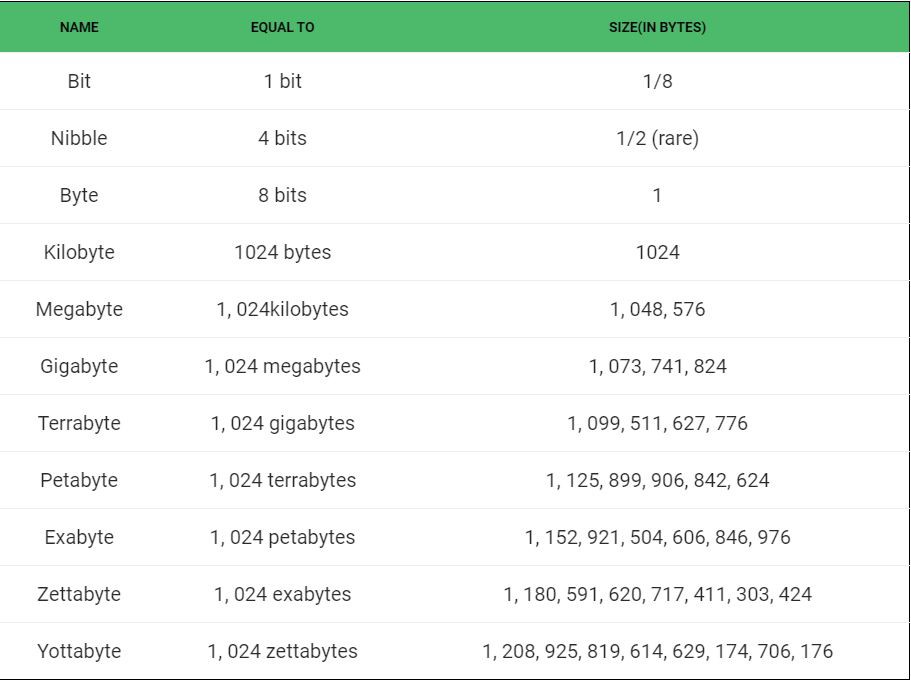
Tabular Representation of various Memory Sizes
各种内存大小的表格表示
这是大公司管理的数据量
(
Here’s How Much Data Big Companies Manage
)
It makes us to wonder, just how much data is the tech giants companies like Google and Facebook are generating? What does that hugedata look like, and is it comparable to any such? Here are the stats from four of the biggest tech companies out there right now.
这让我们想知道,像Google和Facebook这样的科技巨头公司正在生成多少数据? 那巨大的数据看起来像什么,它可以与之媲美吗? 以下是目前四家最大的科技公司的统计数据。

Google:每秒40,000次Google Web搜索
(
Google: 40,000 Google Web Searches Per Second
)
Google revealed some huge, big stats on big data recently. Around more than 3.7 billion humans now have regular access to the internet. And, that results in approx 40,000 web searches per second on Google. This can only be understand by our habit : No one says “Let me check on the internet.” It’s always “Let me Google that.”.
Google最近透露了一些有关大数据的庞大统计数据。 现在,大约有37亿人可以正常访问互联网。 而且,这导致每秒在Google上大约进行40,000次网络搜索。 这只能由我们的习惯来理解:没有人说“让我上网检查”。 始终是“让我使用Google”。
Furthermore, over half of all those web searches are through the mobile devices. It is likely the web search totals will continue to grow as more and more people start using their mobile devices across the world.
此外,所有这些网络搜索中有一半以上是通过移动设备进行的。 随着全球越来越多的人开始使用其移动设备,网络搜索的总数可能会继续增长。
Facebook:每天4 PB的数据。
(
Facebook: 4 petabytes of data every day.
)
In the year 2012, this stats was something around
500 terabyte
, as revealed by Facebook. But, this huge amount of change is due to the amount of time users spend on
Facebook
, as reflected in the data growth statistics throughout 2020. In fact, people spend more time on Facebook than any other social network.
正如Facebook透露的那样,在2012年,这一数据约为
500 TB
。 但是,这一巨大的变化是由于用户在
Facebook上
花费的时间所致,这反映在整个2020年的数据增长统计数据中。实际上,人们在Facebook上花费的时间比任何其他社交网络都多。
Ever thought that how many photos are uploaded to Facebook every day? It is a huge number. Around
350 million photos are uploaded to Facebook each day.
有没有想过每天有多少照片上传到Facebook? 这是一个巨大的数字。
每天
大约有
3.5亿张照片上传到Facebook。
Another stat Facebook revealed in the year 2012 was that over
100 petabytes
of data are stored in a
single Hadoop disk cluster
Facebook在2012年披露的另一项统计数据是,
单个Hadoop磁盘集群
中存储了
100 PB
以上的数据
Twitter:每天12 TB
(
Twitter: 12 Terabytes Per Day
)
One can’t think that 140-character messages comprise large stores of data, but it turns out that the Twitter community generates
more than 12 terabytes of data per day
.
不能认为140个字符的消息包含大量数据,但事实证明,Twitter社区
每天
生成
的数据超过12 TB
。
That equals 84 terabytes per week and 4368 terabytes — or 4.3 petabytes — per year. That’s a huge data certainly for short, character-limited messages like those shared on the network. This is because there are around 330 million users active Twitter boasts
330 million monthly active users.
Of these, more than 40 percent, or more specifically, 145 million, use the service on a daily basis.
相当于每周84 TB,每年等于4368 TB,即4.3 PB。 对于像网络上共享的那些短而受字符限制的消息,这无疑是一个巨大的数据。 这是因为大约有
3.3亿活跃用户
Twitter拥有
每月3.3亿活跃用户。
在这些服务中,每天有超过40%(或更具体地为1.45亿)使用该服务。
亚马逊:
(
Amazon :
)
-
Amazon is dominating the marketplace — Amazon processes $373 MILLION in sales every day in 2017, compared to about 120 million amazon sales in 2014
亚马逊正在主导市场-2017年,亚马逊每天的销售额为3.73亿美元,而2014年亚马逊的销售额约为1.2亿美元
-
Each month more than around 206 million people around the world get on their devices and visit Amazon.com.
每个月,全球约有2.06亿人使用他们的设备并访问Amazon.com。
-
Amazon S3
— on top of everything else the company handles and offers a comprehensive cloud storage solution that naturally facilitates the transfer and storage of massive data troves. Because of this, it’s difficult to truly pinpoint just how much data Amazon is generating in total.
Amazon S3
—除公司处理的所有其他事物之外,
Amazon S3
还提供全面的云存储解决方案,从而自然地促进了海量数据仓库的传输和存储。 因此,很难准确查明亚马逊总共产生了多少数据。
大数据实际上意味着什么?
(
What Is Big Data actually means?
)
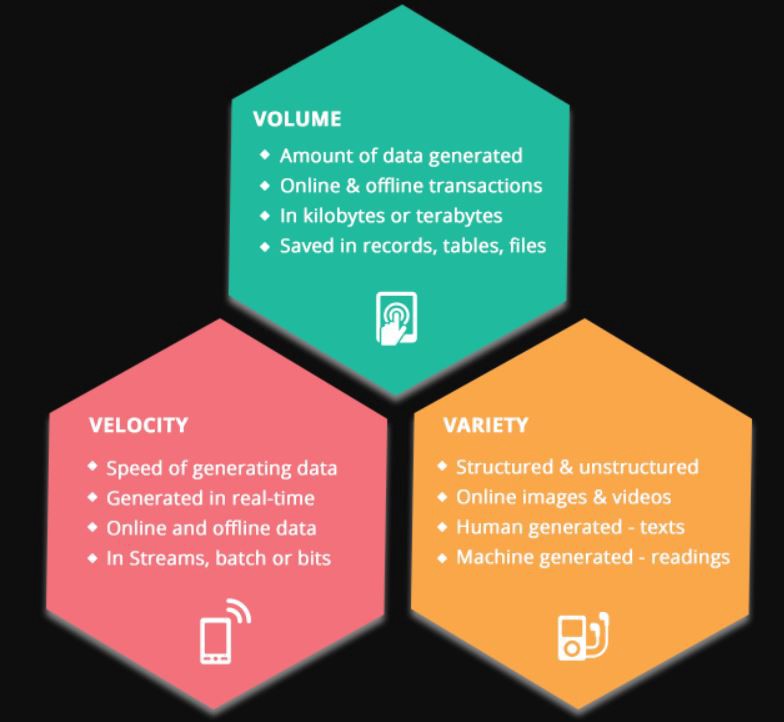
3 V’s Of BIG DATA
3 V的大数据
It is a combination of structured, semi-structured as well as unstructured data collected by different organizations that can be mined for useful information for predictive modeling and other advanced analytics applications.
它是由不同组织收集的结构化,半结构化和非结构化数据的组合,可以从中获取有用的信息以用于预测建模和其他高级分析应用程序。
In present tech-savvy world, Big data is often characterized by the 3Vs: the large
volume
of data, the wide
variety
of data types and the
velocity
at which the data is generated, collected and it’s processing is done.
在当今精通技术的世界中,大数据通常以3V为特征:大数据
量
,
多种
数据类型以及数据生成,收集和处理的
速度
。
大数据的重要性
(
Importance of Big Data
)
Many of the tech giant companies use the big data accumulated in their systems to improve operations, provide better customer service, develop personalized marketing campaigns based on specific customer preferences and, ultimately, increase profitability.
许多高科技巨头公司都使用其系统中积累的大数据来改善运营,提供更好的客户服务,根据特定的客户偏好制定个性化的营销活动,并最终提高盈利能力。
Companies which utilizes big data hold a potential over those that don’t since they’re able to make faster and more informed decisions, provided they use the data many time more effectively. Using customer data as an example, the different branches of analytics that can be done as —
Comparative analysis
: of customer-engagement,
Social media listening
: to know what their customer are saying about their products,
Marketing analysis :
to develop new ideas to make the promotion of their new products, and many more.
利用大数据的公司与未使用大数据的公司相比,具有更大的潜力,因为他们可以更快,更明智地做出决策,前提是他们可以更有效地多次使用数据。 以客户数据为例,可以将分析的不同分支进行如下操作-
比较分析
:客户参与度,
社交媒体监听
:了解客户对他们的产品的评价,
营销分析:
制定新的构想推广他们的新产品,等等。
大数据的存储和处理量
(
How big data is stored and processed
)
The need to handle big data have some unique demands in the computer infrastructure. The computing power required to access and process the huge volumes and varieties of data quickly can inundate a single server or server cluster. Companies must apply some adequate processing capacity to big data tasks in order to achieve the required velocity.
处理大数据的需求在计算机基础架构中有一些独特的需求。 快速访问和处理大量数据和各种数据所需的计算能力可能会淹没单个服务器或服务器群集。 公司必须对大数据任务应用适当的处理能力,以达到所需的速度。
This can potentially required some hundreds or thousands of servers that can distribute the processing work and operate in a combined way, often based on some technologies like Hadoop and Apache Spark.
这可能需要数百或数千台服务器,这些服务器通常可以基于Hadoop和Apache Spark等某些技术来分配处理工作并以组合方式运行。
分布式存储
(
Distributed Storage
)
There will be multiple machines and multiple processors. It holds a set of nodes called
‘Cluster’
(which basically means ‘Collection’). This system can scale linearly and if you double the number of nodes in your system, you’ll be getting double the storage. It also increases the speed of the machine to twice.
将有多台机器和多个处理器。 它拥有一组称为
“集群”
的节点(基本上意味着“集合”)。 该系统可以线性扩展,如果您将系统中的节点数增加一倍,则存储量将增加一倍。 它还将机器的速度提高了两倍。
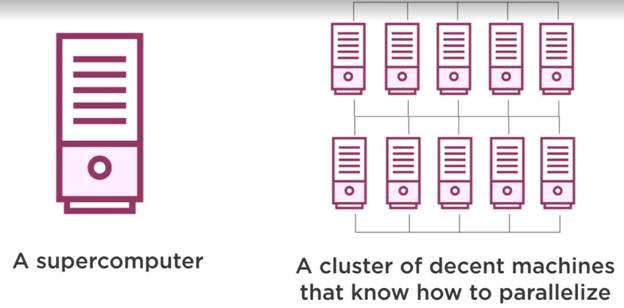
Distributed Storage
分布式存储
In present scenario, a wide set of systems and application, especially in high performance computing, depends on distributed environments to process and analyses huge amounts of data. As the amount of data is increasing at an unprecedented rate, and the main aim is to develop an efficient, reliable and scalable storage system. One of such system is
Distributed File Systems (DFSs)
.
It
used to develop a hierarchical and unified view of multiple file servers share over the network.
在当前情况下,尤其是在高性能计算中,广泛的系统和应用程序依赖于分布式环境来处理和分析大量数据。 随着数据量以前所未有的速度增长,其主要目标是开发高效,可靠和可扩展的存储系统。 这种系统之一是
分布式文件系统(DFS)
。
它
用于开发网络上共享的多个文件服务器的层次结构和统一视图。
Apache Hadoop作用
(
Role of Apache Hadoop
)

Hadoop
is an open-source framework that allows to store and process big data in a distributed environment across clusters of computers using simple programming models. It is designed to scale up from single servers to even thousands of machines, each offering local computation and storage.
Hadoop
是一个开放源代码框架,允许使用简单的编程模型在跨计算机集群的分布式环境中存储和处理大数据。 它旨在从单个服务器扩展到数千台机器,每台机器都提供本地计算和存储。
Hadoop集群
(
Hadoop Cluster
)
It is a cluster which is designed as such to perform Big-data computation efficiently and also to store and manage huge amounts of data. It is a collection of commodity hardware interconnected with each other and working together as a single unit.
它是一个集群,旨在高效地执行大数据计算以及存储和管理大量数据。 它是彼此互连并作为单个单元一起工作的商品硬件的集合。
Using the solution provided by Google,
Doug Cutting
and his team developed an Open Source Project called ‘
HADOOP’
. The entire
Hadoop
algorithm is coded in Java. It works in an environment that has
distributed storage
and computation capability across multiple clusters.
使用Google提供的解决方案,
Doug Cutting
及其团队开发了一个名为“
HADOOP”的
开源项目。 整个
Hadoop
算法使用Java编码。 它在具有跨多个群集的
分布式存储
和计算功能的环境中工作。
Hadoop runs applications using the
MapReduce algorithm
, where the data is processed in parallel with others. In short, Hadoop is used to develop applications that could perform complete statistical analysis on huge amounts of data.
Hadoop使用
MapReduce算法
运行应用程序,其中数据与其他数据并行处理。 简而言之,Hadoop用于开发可以对大量数据执行完整统计分析的应用程序。
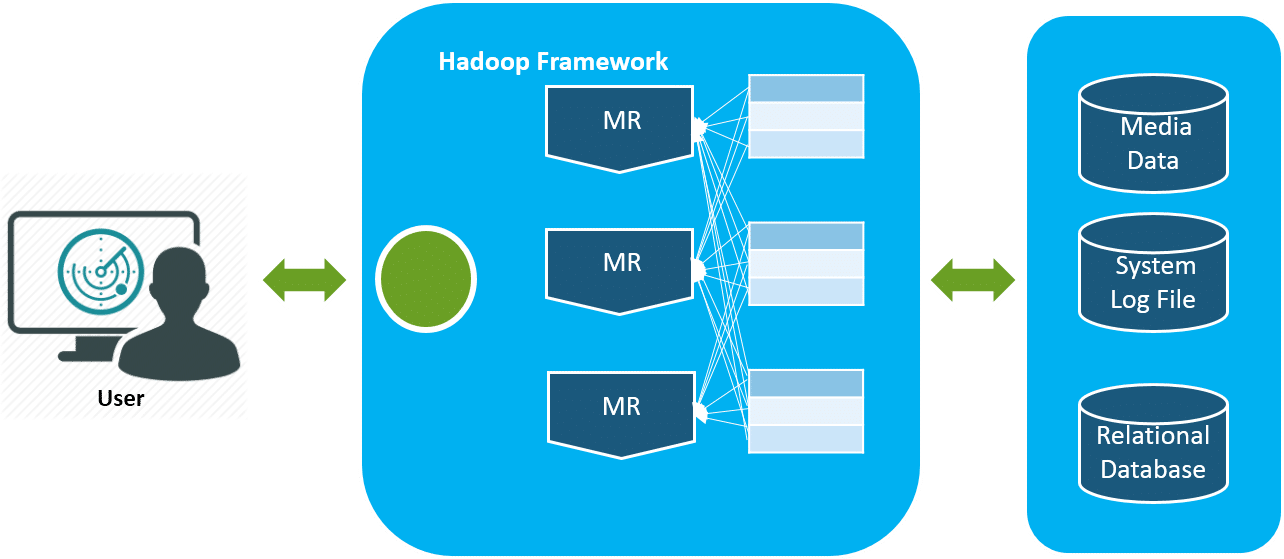
Hadoop Framework
Hadoop框架
MapReduce算法
(
MapReduce Algorithm
)
MapReduce
is a programming model which consists of writing
map
and
reduce
functions. Map accepts ‘key/value pairs’ and produces a sequence of key/value pairs. Then, the data is shuffled to group keys together. After that, we reduce the accepted values with the same key and produce a new key/value pair.
MapReduce
是一个编程模型,由编写
map
和
reduce
函数组成。 Map接受“键/值对”并生成一系列键/值对。 然后,将数据混洗以将密钥分组在一起。 之后,我们使用相同的键来减少可接受的值,并产生一个新的键/值对。
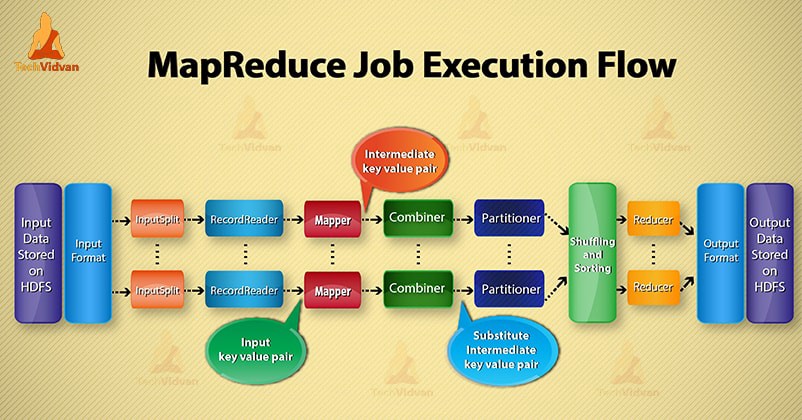
How MapReduce Works?
MapReduce如何工作?
Hadoop分布式文件系统
(
Hadoop Distributed File System
)
The
Hadoop Distributed File System
(HDFS) is a distributed file system designed to run on commodity hardware. The differences from other distributed file systems are significant. HDFS is highly fault-tolerant and is designed to be deployed on low-cost hardware. HDFS provides high throughput access to application data and is suitable for applications that have large data sets. In fact, deployments of more than thousand of nodes in HDFS exist.
Hadoop分布式文件系统
(HDFS)是一种旨在在商品硬件上运行的分布式文件系统。 与其他分布式文件系统的区别非常明显。 HDFS具有高度的容错能力,旨在部署在低成本硬件上。 HDFS提供对应用程序数据的高吞吐量访问,并且适用于具有大数据集的应用程序。 实际上,存在HDFS中数千个节点的部署。
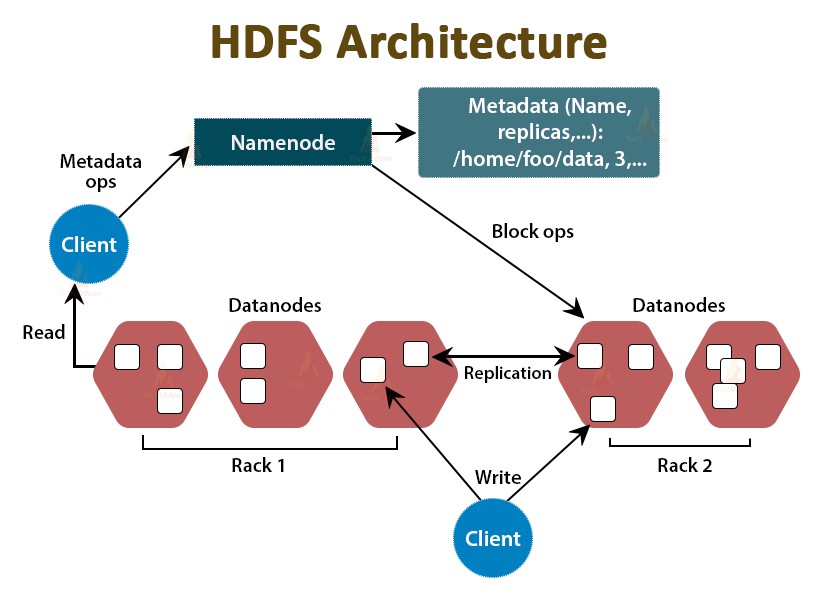
In HDFS, files are divided into blocks, and file access follows single-writer and multi-reader semantics. To meet the fault-tolerance requirement, multiple replicas of a block are stored on different DataNodes. The number of replicas is called the
replication factor.
This framework also includes the following two modules which are as−
在HDFS中,文件分为多个块,文件访问遵循单写和多读语义。 为了满足容错要求,一个块的多个副本存储在不同的DataNode上。 副本数称为
复制因子。
该框架还包括以下两个模块,分别是:
-
Hadoop YARN
− This is a framework which is used for job scheduling and cluster resource management.
Hadoop YARN-
这是一个用于作业调度和群集资源管理的框架。 -
Hadoop Common
− These are Java libraries and the utilities required by other Hadoop modules.
Hadoop Common-
这些是Java库以及其他Hadoop模块所需的实用程序。
名称节点
(
NameNode
)
It is the
master node
in the Apache Hadoop HDFS Architecture that maintains and manages the blocks present on the DataNodes (slave nodes).
它是Apache Hadoop HDFS架构中的
主节点
,用于维护和管理DataNode(从节点)上存在的块。
数据节点
(
DataNode
)
These are the
slave nodes
in HDFS. Unlike NameNode, DataNode is a commodity hardware, that is, a non-expensive system which is not of high quality or high-availability. The DataNode is a block server that stores the data in the local file
这些是HDFS中的
从节点
。 与NameNode不同,DataNode是一种商品硬件,即不是高质量或高可用性的非昂贵系统。 DataNode是将数据存储在本地文件中的块服务器
Facebook如何部署大数据?
(
How Is Facebook Deploying Big Data?
)
As the enormous data generated by Facebook each day as it has around
2.38 Billion
number of active users, It is one the biggest user of Hadoop Cluster. And thus, It is known as the
Robust user of Hadoop cluster.
由于Facebook每天产生的庞大数据,拥有大约
23.8亿
活跃用户,因此它是Hadoop Cluster的最大用户之一。 因此,它被称为
Hadoop集群
的
强大用户。
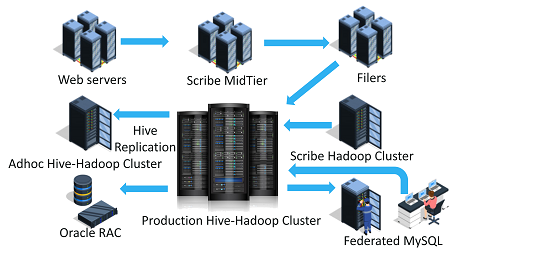
Facebook’s Hadoop Cluster
Facebook的Hadoop集群
Basically, Facebook runs the biggest Hadoop cluster that goes beyond
4,000 machines
and storing more than
hundreds of millions of gigabytes.
Hadoop provides a common infrastructure for Facebook with efficiency and reliability.
基本上,Facebook运行着最大的Hadoop群集,该群集超过
4,000台计算机,
并存储
了数亿千兆字节。
Hadoop为Facebook提供了高效且可靠的通用基础架构。
Facebook
developed its first user-facing application, Facebook Messenger, based on Hadoop database, i.e., Apache HBase, which has a kind of layered architecture that supports abundance of messages in a single day.
Facebook
开发了第一个基于Hadoop数据库的面向用户的应用程序Facebook Messenger,即Apache HBase,它具有一种分层的体系结构,可在一天之内支持大量消息。
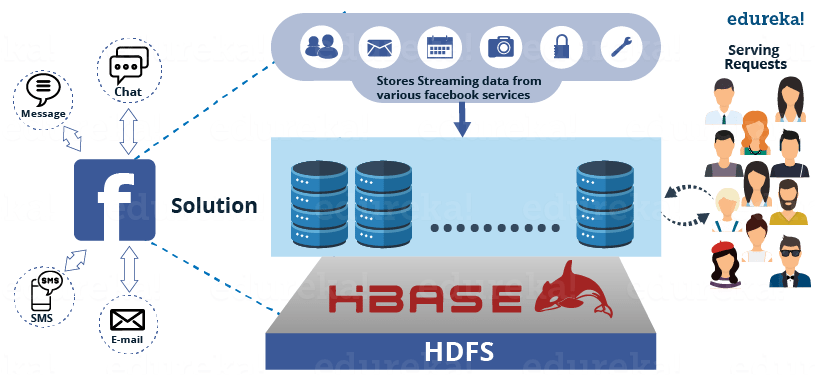
Facebook’s HDFS
Facebook的HDFS
Facebook
stores much of the data on its massive
Hadoop cluster
, which has grown exponentially in recent years. Today the
cluster
holds a staggering 30 petabytes of data.
Facebook
将许多数据存储在其庞大的
Hadoop集群中
,该
集群
近年来呈指数增长。 如今,该
集群
拥有惊人的30 PB数据。
结论
(
Conclusion
)
The availability of Big Data, low-cost commodity hardware, and new information management and analytic software have produced a unique moment in the history of data analysis. Hadoop is one of the framework that makes us able to work on large datasets. Distributed Storage and thus computing will have a vast scope and need in upcoming future.
大数据的可用性,低成本的商品硬件以及新的信息管理和分析软件已经在数据分析的历史上产生了独特的时刻。 Hadoop是使我们能够处理大型数据集的框架之一。 分布式存储以及由此而来的计算将在不久的将来具有广阔的范围和需求。
“The future belongs to those who prepare for it. So get ready for the enthralling journey of Distributed Computing.”
“未来属于为未来做好准备的人。
因此,为分布式计算这个令人着迷的旅程做好准备。”
#bigdata #hadoop #bigdatamanagement #arthbylw #vimaldaga #righteducation #educationredefine #rightmentor #worldrecordholder #ARTH #linuxworld #makingindiafutureready #righeudcation
#bigdata #hadoop #bigdatamanagement #arthbylw #vimaldaga #righteducation #educationdefine #rightmentor #worldrecordholder #ARTH #linuxworld #makingindiafutureready #righeudcation
hadoop集群数据存储