世界幸福指数报告可视化
数据集描述
Kaggle提供的数据集包括2015、2016、2017的报告。每年的报告的形式为CSV文件:2015.csv, 2016.csv。由于2017报告的格式与之前两年的不同,本次项目中只对2015和2016年的报告进行分析。
数据详细情况
-
Country
: 国家名称,字符串 -
Region
: 所属区域,字符串 -
Happiness Rank
: 排名,整型 -
Happiness Score
: 幸福指数(0~10),浮点型。由以下6个因素计算得出。 -
1. Economy (GDP per Capita)
: 人均GDP,浮点型 -
2. Family
: 社会支援(social support),浮点型 -
3. Health (Life Expectancy)
: 预期健康寿命,浮点型 -
4. Freedom
: 人生抉择自由,浮点型 -
5. Trust (Government Corruption)
: 免于贪腐自由,浮点型 -
6. Generosity
: 慷慨,浮点型
数据可视化框架
项目步骤
- 查看所有数据信息
- 区域内的平均幸福指数可视化
- 区域内的人均GDP分部、社会支援信息,预期健康寿命信息,人生抉择自由信息,免于贪腐自由信息,慷慨信息,可视化
- 全世界区域内国家数量分布情况
- 所有国家在不同区域内的分部
- 排名前/后5个国家的幸福指数情况
- 三年内幸福指数变化情况
项目实现
-
引入所有包,读入数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
dataset_path = "./data/"
data_2015 = pd.read_csv(dataset_path+'2015.csv')
data_2016 = pd.read_csv(dataset_path+'2016.csv')
-
查看数据信息
def data_info():
print(data_2015.info())
print(data_2015.describe())
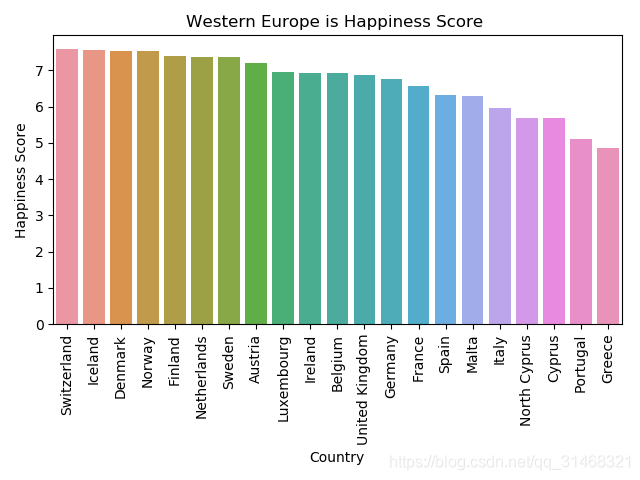
- 区域内的平均幸福指数可视化
def country_score_of_every_region():
#设置需要提取的数据的列名
plt_cols = ['Region', 'Happiness Score', 'Country']
plt_da = data_2015[plt_cols]#提取数据
print(type(plt_da))
regions = set(plt_da['Region'])#获取所有区域名称
for item in regions:#分别获取一个区域内的所有国家信息
plt.figure()#画图
data = plt_da[plt_da['Region'] == item]
print("{}.dataset is :".format(item))
#plt.bar(data['Country'],data['Happiness Score'])
sns.barplot(data['Country'],data['Happiness Score'])
plt.xticks(rotation='vertical')#设置横坐标数据方向
plt.ylabel("Happiness Score")
plt.xlabel("Country")
plt.title('{} is Happiness Score '.format(item))
plt.show()#图片展示
图片展示(只展示一个图片,可以获取代码运行)
-
区域内的人均GDP分部、社会支援信息,预期健康寿命信息,人生抉择自由信息,免于贪腐自由信息,慷慨信息,可视化
**参数**
#'Economy (GDP per Capita)',
# 'Family',
# 'Health (Life Expectancy)',
# 'Freedom',
# 'Trust (Government Corruption)',
# 'Generosity'
#‘Happiness Rank’
def regions_country_Happiness_infos(table):
plt_cols = ['Region','Country','Economy (GDP per Capita)','Family','Health (Life Expectancy)','Freedom','Trust (Government Corruption)','Generosity','Happiness Rank']
plt_data = data_2015[plt_cols]
# print(plt_data.info())
regions = set(plt_data['Region'])
#画子图,看不太清
# plt.figure()
# i = 1
# for item in regions:
# dat = plt_data[plt_data['Region']==item]
# if i !=1 :
# ax = plt.subplot(5,2,i,sharey=ax)
# else:
# ax = plt.subplot(5,2,i)
# sns.barplot(x='Country',y='Economy (GDP per Capita)',data=dat)
# plt.title('GDP per Capita in {}'.format(item))
# plt.xlabel('Country')
# plt.ylabel('GDP per Capita')
# i+=1
# plt.show()
for item in regions:
plt.figure()
dat = plt_data[plt_data['Region'] == item]
sns.barplot(x='Country', y=table, data=dat)
plt.title('{} in {}'.format(table,item))
plt.xlabel('Country')
plt.ylabel(table)
plt.xticks(rotation='vertical')
plt.show()
-
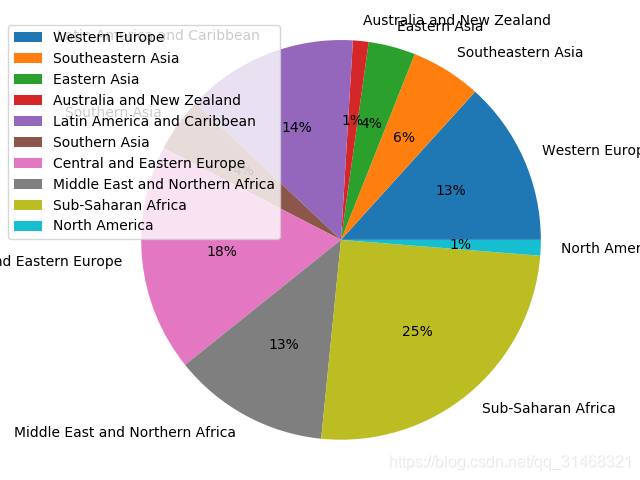
全世界区域内国家数量分布情况
def regions_country_pie():
plt_cols = ['Region','Country']
plt_da = data_2015[plt_cols]
print(type(plt_da))
regions = set(plt_da['Region'])
info = {}
for item in regions:
dat = plt_da[plt_da['Region'] == item]#获取不同区域的国家数量
# print(list(dat['Country']))
country_num = len(list(dat['Country']))
info[item] = country_num
print(info)
plt.figure()#画饼图
labels = info.keys()
sizes = info.values()
print(labels,sizes)
explode =[0.05,0,0,0,0,0,0,0,0,0]
patches,l_text,p_text = plt.pie(x=list(sizes),labels=labels,autopct='%1.f%%')
plt.axis('equal')
for t in l_text:#设置字符尺寸
t.set_size = 130
for t in p_text:
t.set_size = 120
plt.legend(loc='upper left',bbox_to_anchor=(-0.1, 1))#设置图标位置
plt.grid()
plt.show()
图片展示
-
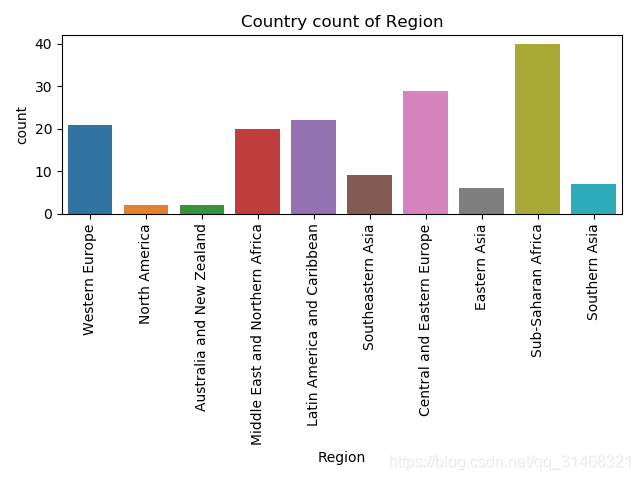
所有国家在不同区域内的分部
def every_regions_country_num():
plt_cols = ['Region', 'Happiness Score', 'Country']
plt_da = data_2015[plt_cols]
plt.figure()
sns.countplot(x='Region',data=plt_da)
plt.xticks(rotation='vertical')
plt.title('Country count of Region')
plt.show()
图片展示
-
排名前/后5个国家的幸福指数情况
def up_5_country_happiness():
data = data_2015[:5]
data2 = data_2015[-5:]
cols = ['Region', 'Happiness Score', 'Country']
info_up = data[cols]
info_down = data2[cols]
# info1 = data[['Region', 'Happiness Score', 'Country']]
plt.figure()
ax = plt.subplot(1,2,1)
sns.barplot(x='Country',y='Happiness Score',data=info_up)
plt.xticks(rotation='vertical')
plt.title('Country Happiness Score')
ax1 = plt.subplot(1,2,2,sharey=ax)
sns.barplot(x='Country', y='Happiness Score', data=info_down)
plt.xticks(rotation='vertical')
plt.title('Country Happiness Score')
plt.show()
图片展示
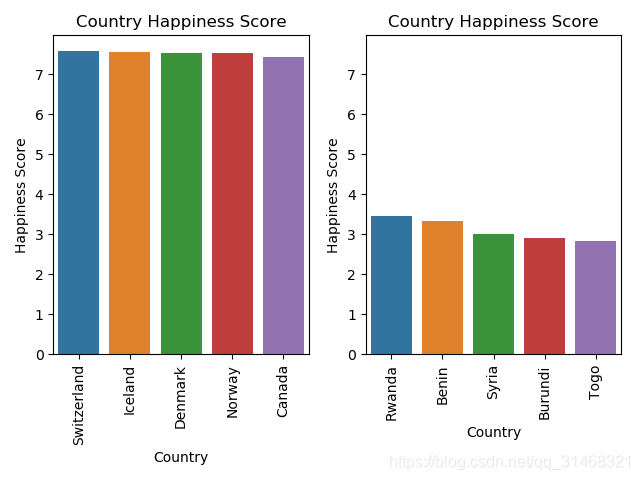
-
三年内幸福指数变化情况
def happiness_change_in_2_years():
cols = ['Region', 'Happiness Score', 'Country']
da_2015 = data_2015[cols]
print(da_2015)
width = 0.4
da_2016 = data_2016[cols]
# da_2017 = data_2017[cols]
regions = set(da_2015['Region'])
for item in regions:
da_15 = da_2015[da_2015['Region'] == item]#获取15/16年的数据
da_16 = da_2016[da_2016['Region'] == item]
x_15 = len(da_15['Country'])
x1_15 = np.arange(x_15)+1
y_15 = list(da_15['Happiness Score'])
height_15 = np.array(y_15)
x_16 = len(da_16['Country'])
x1_16 = np.arange(x_16) + 1+0.4
y_16 = list(da_16['Happiness Score'])
height_16 = np.array(y_16)
plt.figure()
#画图
a = plt.bar(x=x1_15, height=height_15,width=width,label='2015')
b = plt.bar(x=x1_16, height=height_16,width=width,label='2016',tick_label = da_16['Country'])
plt.xticks(rotation='vertical')
plt.title('{} Happiness Score'.format(item))
plt.legend()
plt.show()
图片展示(展示一个图片)
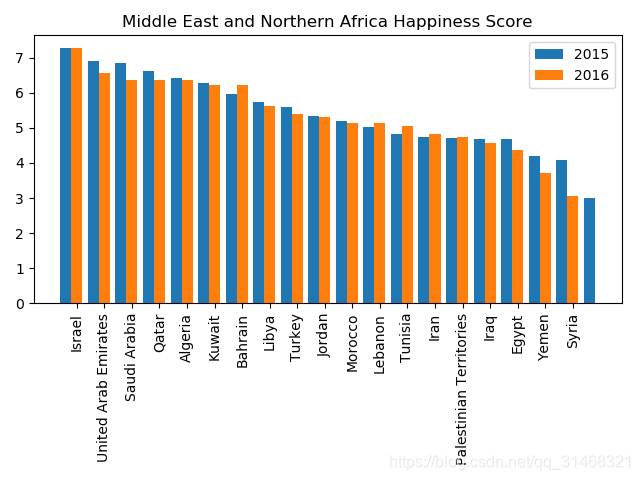
主函数
if __name__ == '__main__':
data_info()
#区域
regions_country_Happiness_infos('Economy (GDP per Capita)')
regions_country_Happiness_infos('Family')
regions_country_Happiness_infos('Health (Life Expectancy)')
regions_country_Happiness_infos('Freedom')
regions_country_Happiness_infos('Trust (Government Corruption)')
regions_country_Happiness_infos('Generosity')
regions_country_rank()
regions_country_pie()
up_5_country_happiness()
#国家
every_regions_country_num()
#幸福指数
happiness_change_in_2_years()
版权声明:本文为qq_31468321原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。