梯度下降法
梯度下降法简介
梯度下降法,又称最速下降法,是一个一阶最优化算法,迭代法的一种,可以用于求解最小二乘问题(线性和非线性都可以)
梯度
:在单变量的函数中,梯度其实就是函数的
微分
,代表着函数在某个给定点的
切线的斜率
; 在多变量函数中,梯度是函数对每个变量的
偏微分
组成的向量。梯度的方向就是这个向量的方向。它是函数在给定点的上升(下降)最快的方向

基本思想
可用下山举例说明,将小人看作J(ω),即表示目标函数,目的地是最低点。而中间如何到达最低点则是我们需要解决的问题。下山路有千万种,想要快速的到达,就需要选择最陡的地方下山。在当前位置求偏导,即我们所讨论的梯度,正常的梯度方向类似于上山的方向,是使值增大的,下山最快需使J(ω)最小,从负梯度求最小值,这就是梯度下降。梯度上升是直接求偏导,梯度下降则是梯度上升的负值。由于不知道怎么下山,于是需要走一步算一步,继续求解当前位置的偏导数。这样一步步的走下去,当走到了最低点,此时我们能得到一个近似最优解。所以可以看出梯度下降有时得到的是局部最优解,如果损失函数是凸函数,梯度下降法得到的解就是全局最优解。
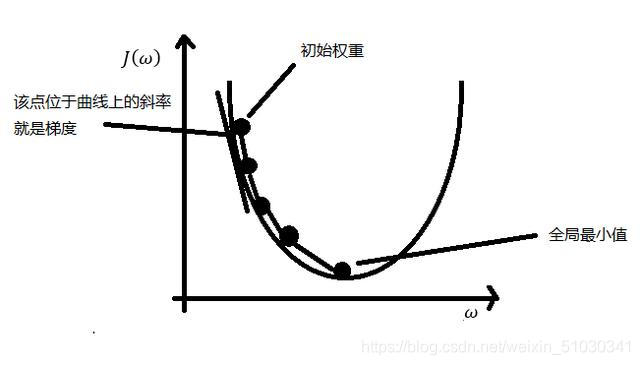
具体分析
如果函数为一元函数,梯度就是该函数的导数。

如果为二元函数,梯度定义为:

要搜索极小值C点,在A点必须向x增加方向搜索,此时与A点梯度方向相反;在B点必须向x减小方向搜索,此时与B点梯度方向相反。总之,搜索极小值,必须向负梯度方向搜索。
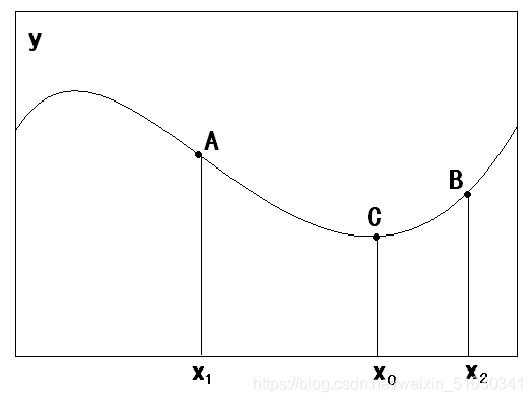
求解步骤
假设函数 y = f(x1,x2,…,xn) 只有一个极小点。
初始给定参数为 X0 = (x10,x20,…xn0) 。从这个点如何搜索才能找到原函数的极小值点?
**
方法:
**1.**首先设定一个较小的正数η,ε;
**2.**求当前位置出的各个偏导数:

**3.**修改当前函数的参数值,公式如下:

**4.**如果参数变化量小于ε,退出;否则返回2。
举例
任给一个初始出发点,设为x0=-4,利用梯度下降法求函数y=x2/2-2x的极小值。
1.首先给定两个参数:η=0.9,ε=0.01
2.计算函数导数:dy/dx=x-2;
3.代入x0=-4,计算当前导数值:y’=-6
4.修改当前参数:x’=x-ηy’=1.4; ∆x=-ηy’=5.4
5.比较∆x与ε的大小:需满足∆x<ε,但当前5.4>0.01
6.代入x’=1.4,计算当前导数值:y’=-0.6
7.循环计算,直到参数变化量小于ε
代码及实现
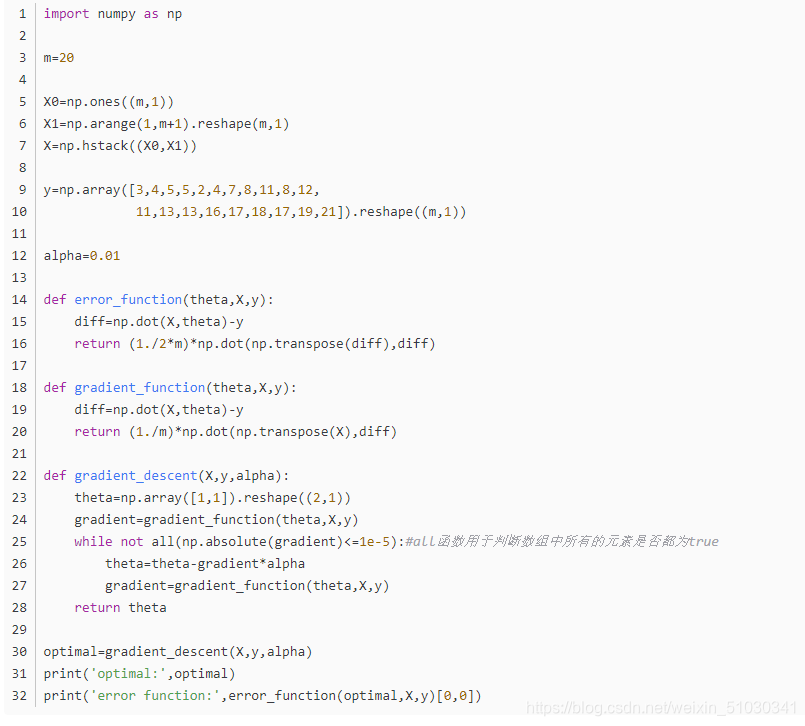
以上转自:https://www.jianshu.com/p/c7e642877b0e
损失函数
损失函数用于衡量预测结果与真实值之间的误差,最简单的损失函数定义方式为平方差损失
举一个例子,房屋占地面积与价格:

我们该如何表达h?
一种可能的表达方式为:hθ(x)=θ0+θ1x,因为只含有一个特征/输入变量
在上式中,θ0,θ1是未知参数,x是已知数据,目的是得到合适的参数来使我们的预测尽可能的准确,此时就要引入损失函数和误差的概念。
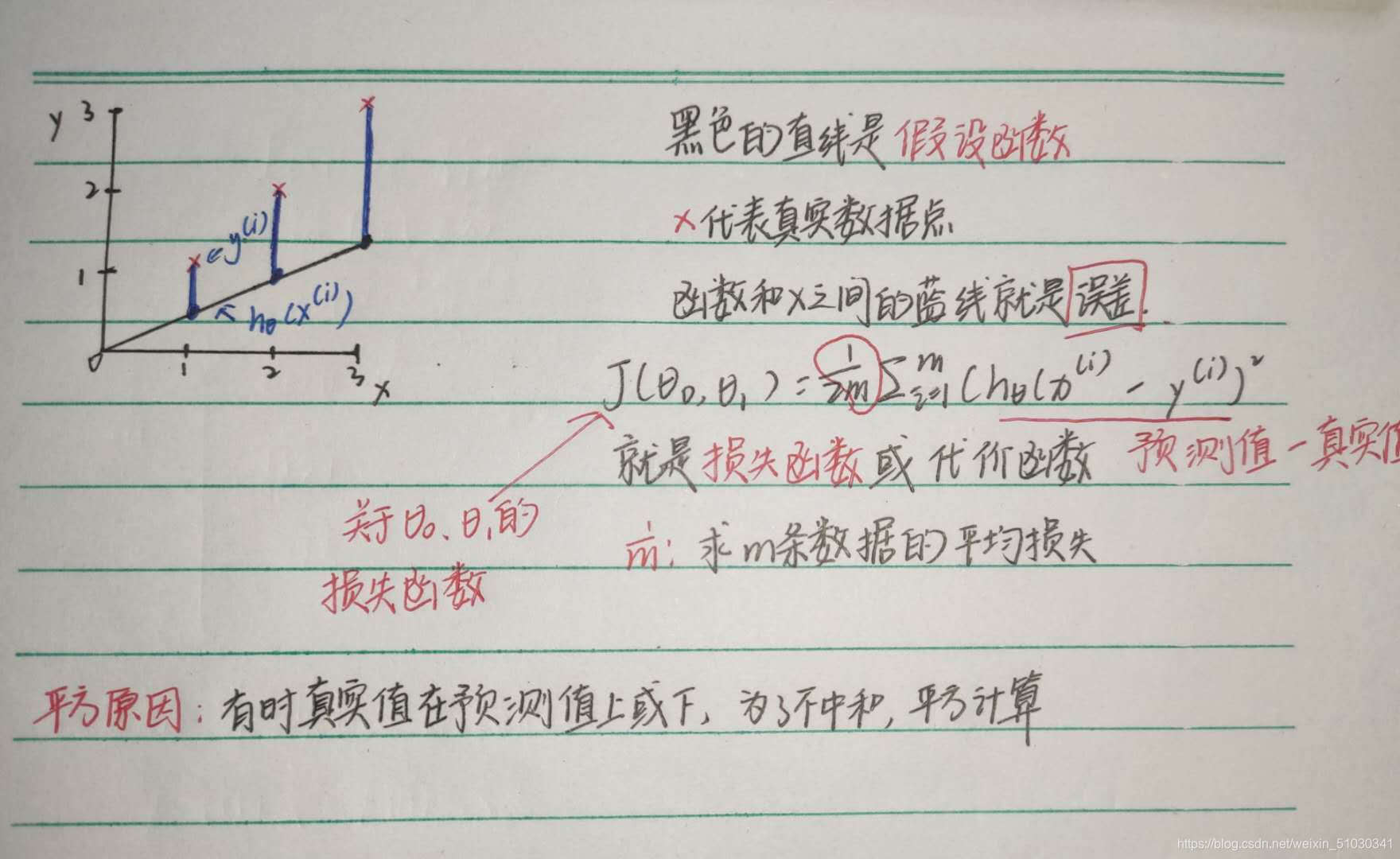
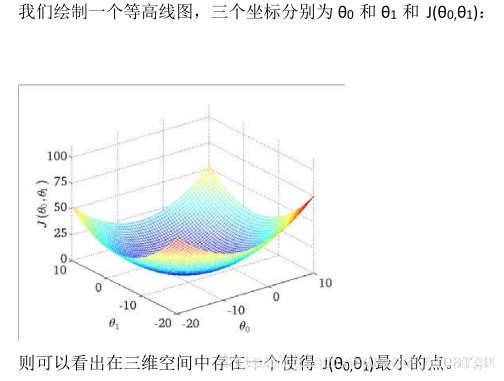
最低点对应的θ0和θ1就是我们要找的参数
对于二次函数来说,最小值可直接由公式算出来 -2a/b
但还有特殊情况
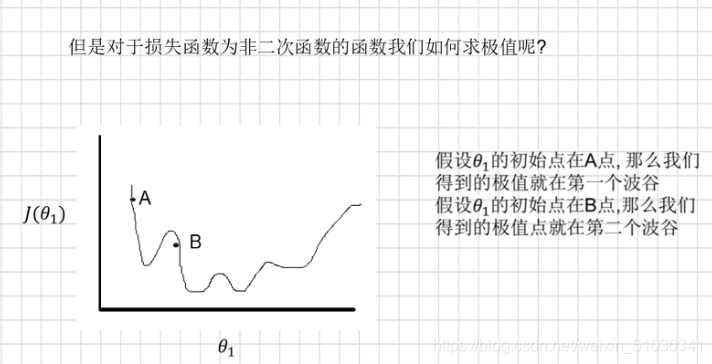
所以此时初始点的选择很重要。
步骤

其中α是学习率(learing rate),它决定了我们沿着能让代价函数下降程度最大的方向向下迈出的步子有多大,限定步长,不能太小或太大。如果 α调整的刚刚好,就能顺利找到最低点。如果α 调整的太小,就会走的太慢,虽然这种情况给足够多的时间也可以找到最低点,实际情况可能会等不及出结果。如果α有点大,就会在上面震荡,走不下去,永远无法到达最低点。还有可能非常大,直接就飞出去了,更新参数的时候只会发现损失函数越更新越大。
梯度下降法的类型
基于如何使用数据计算代价函数的导数,梯度下降法可以被定义为不同的形式(various variants)。确切地说,根据使用数据量的大小(the amount of data),时间复杂度(time complexity)和算法的准确率(accuracy of the algorithm),梯度下降法可分为:
-
批量梯度下降法(Batch Gradient Descent, BGD); -
随机梯度下降法(Stochastic Gradient Descent, SGD); -
小批量梯度下降法(Mini-Batch Gradient Descent, MBGD)。
批量梯度下降法原理
这是梯度下降法的基本类型,这种方法使用整个数据集(the complete dataset)去计算代价函数的梯度。每次使用全部数据计算梯度去更新参数,批量梯度下降法会很慢,并且很难处理不能载入内存(don’t fit in memory)的数据集。在随机初始化参数后,按如下方式计算代价函数的梯度:

其中,m是训练样本(training examples)的数量。
Note:
1. 如果训练集有3亿条数据,你需要从硬盘读取全部数据到内存中;
2. 每次一次计算完求和后,就进行参数更新;
3. 然后重复上面每一步;
4. 这意味着需要较长的时间才能收敛;
5. 特别是因为磁盘输入/输出(disk I/O)是系统典型瓶颈,所以这种方法会不可避免地需要大量的读取
运用梯度下降会快速收敛到圆心,即唯一的一个全局最小值。批量梯度下降法不适合大数据集。
随机梯度下降法原理
批量梯度下降法被证明是一个较慢的算法,所以,我们可以选择随机梯度下降法达到更快的计算。随机梯度下降法的第一步是随机化整个数据集。在每次迭代仅选择一个训练样本去计算代价函数的梯度,然后更新参数。即使是大规模数据集,随机梯度下降法也会很快收敛。随机梯度下降法得到结果的准确性可能不会是最好的,但是计算结果的速度很快。在随机化初始参数之后,使用如下方法计算代价函数的梯度:

这里m表示训练样本的数量。
如下为随机梯度下降法的伪码:
1. 进入内循环(inner loop);
2. 第一步:挑选第一个训练样本并更新参数,然后使用第二个实例;
3. 第二步:选第二个训练样本,继续更新参数;
4. 然后进行第三步…直到第n步;
5. 直到达到全局最小值
随机梯度下降法不像批量梯度下降法那样收敛,而是游走到接近全局最小值的区域终止。
小批量梯度下降法原理
小批量梯度下降法是最广泛使用的一种算法,该算法每次使用m个训练样本(称之为一批)进行训练,能够更快得出准确的答案。小批量梯度下降法不是使用完整数据集,在每次迭代中仅使用m个训练样本去计算代价函数的梯度。一般小批量梯度下降法所选取的样本数量在50到256个之间,视具体应用而定。
1.这种方法减少了参数更新时的变化,能够更加稳定地收敛。
2.同时,也能利用高度优化的矩阵,进行高效的梯度计算。
随机初始化参数后,按如下伪码计算代价函数的梯度:

这里b表示一批训练样本的个数,m是训练样本的总数。
链接:https://www.cnblogs.com/JXPITer/p/6687721.html