一、触发器
==触发器就是与表有关的数据库对象,在满足定义条件时触发,并执行触发器中定义的语句集合。==触发器的这种特性可以协助应用在数据库端确保数据的完整性。
【举个栗子】
现在有用户表和日志表两个表。当一个用户被创建的时候就需要在日志表中插入创建的日志。如果没有触发器那么就需要编写程序语言逻辑才能实现,但是如果定义了一个触发器,触发器的作用就是
当你在用户表中插入一条数据之后帮你在日志表中插入一条日志信息。
如下表就列出了一些触发器类型以及对应的激活触发器的语句。
| 触发器类型 | 激活触发器的语句 |
|---|---|
| INSERT型触发器 | insert、load、data、replace |
| UPDATE类型触发器 | updata |
| DELETE型触发器 | delete、replace |
【补充】
Replace和insert的区别
现在我们有test这个表,里面的字段类型有id为主键,其他还是有name姓名、age年龄。
初始化里面有一条数据为
“1,zhangsan,18”
如果此时我们再插入一条数据为
“1,lisi,20”
那么,如果采用replace就会执行成功,但是使用insert就会执行失败。就是因为
Replace做的事情相当于是先把数据进行删除过后再进行插入。
但是在插入数据为“2,lisi,20”数据的情况下
两个插入操作没有任何区别。
1、触发器的SQL相关操作
1、创建触发器
创建的语法如下:
create trigger trigger_name
trigger_time
trigger_event
on table_name for each row
begin
sql语句
end;
各个参数的含义:
-
trigger_name
:触发时间,可以是before(检查约束前触发)或者after(检查约束后触发) -
trigger_event
:触发器的触发事件,可以是insert、updata或者delete.
对同一个表相同触发时间的相同触发事件,只能定义一个触发器。所以一张表上最多只能定义6个触发器
-
triggrt_stmt
:要去处理的一系列操作,可能不止一条SQL语句,
不允许select操作执行
【举个栗子】当插入操作来的时候让记录里面的结果加一。
[补充:结束符的指定]
;
为数据库的结束符,代表sql语句的终止,但是begin和end是一组没有办法分离的关键字。所以,解决办法就是通过delimiter来指定结束符。
delimiter +任意符号
即可。
由此,触发器的具体创建如下:
delimiter &&
create trigger tri_1
after
insert
on test
for each row
begin
set @count = @count + 1;
end;
&&
使用过程如下:
-
首先,定义一个变量记录数据中的个数,初始化为10
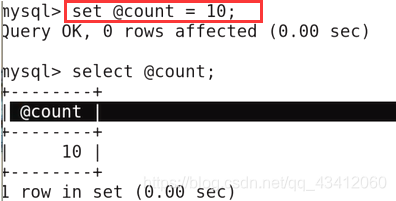
-
再将这个变量值修改为2
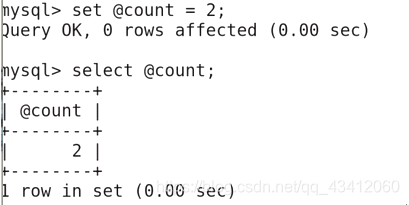
-
此时插入一条数据,此时查询出来的结果就为3了
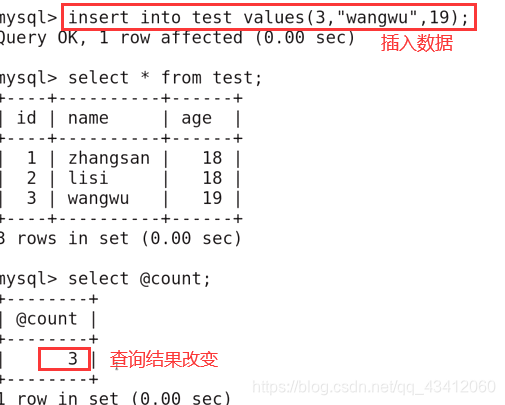
这一系列的结果全是因为触发器,因为一旦执行insert操作就触发了insert操作的触发器,就会把记录的数据个数加一
2、删除触发器
一次可以删除一个触发程序,如果没有指定的schema_name,默认为当前数据库具体语法如下:
drop trigger[schema_name] trigger_name
【举个栗子】要删除film表上的触发器ins_film
drop trigger ins_film;
3、查看触发器
-
可以通过执行
show triggers
命令查看触发器的状态、语法等信息,但是这种方法每一都返回所有的触发器信息,使用起来不太方便。
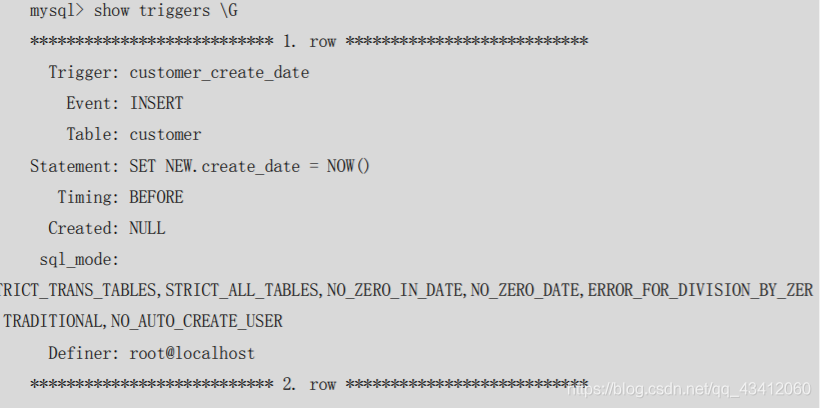
-
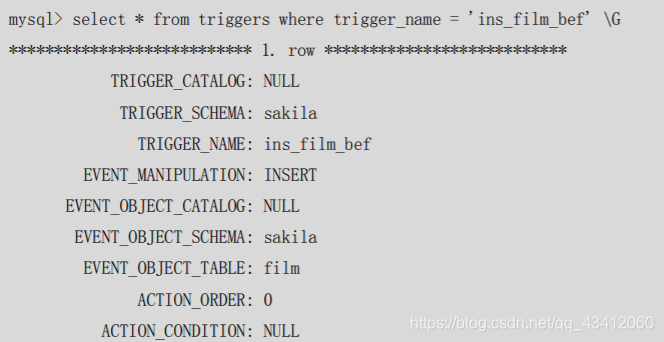
查询指定触发器的指定信息,查看方式是
查询系统表的infromation_schema.tiggers表
4、触发器总结
1、触发器的限制
-
存储过程或者函数通过OUT或者INOUT类型的参数将数据返回触发器是可以的,但是
不能调用直接返回数据的过程
-
不能在触发器中使用以显式或隐式方式开始或结束事务的语句
。如start、trans-action、commit或者rollback。
2、触发器的作用
-
安全性
可以基于数据库的值使用户具有操作数据库的某种权利 -
审计
:可以跟踪用户对数据库的操作
审计用户操作数据库的语句、把用户对数据库的更新写入审计表当中。 -
实现复杂的数据完整性规则
可以引用列或数据库对象。 -
自动计算数据值,如果数据的值达到了一定的要求,则进入待定的处理
二、存储过程
1、概念
存储过程和函数是事先经过编译并存储在数据库中的一段SQL语句的集合
,调用存储过程和函数可以简化应用开发人员的很多工作,减少数据在数据库和应用服务器之间的传输,对于提高数据处理的效率有好处。
存储过程和函数的区别主要如下:
| 存储过程 | 函数 | |
|---|---|---|
| 返回值 | 没有 | 必须有 |
| 参数 | IN、OUT、INOUT | IN |
| 调用 | 通过call调用 | 通过select调用 |
2、优势
减少数据的传输
:可以将数据的处理放在数据库服务器上进行,避免将大量的结果集传输给客户端
1、相关操作
1、创建存储过程
-
需要首先确认用户是否具有相应的权限,例如:
创建
时需要
create routine权限
,
修改或删除
需要
alter routine权限
-
允许包含DDL语句
,也允许在存储过程中执行
提交
(commit,即确认之前的修改)或者
回滚
(rollback,即放弃之前的修改),
但是不允许执行load
create proceduce pro_name(arg_list)
begin
pro_stmt;//存储过程
end
参数属性
IN输入型
:值传递,不会改变实参的值,只会改变形参的值
OUT输出型
:做数据输出使用
INOUT输入输出型
:结合了输入输出的特点,既能做输出也能做输入。
【举个栗子】
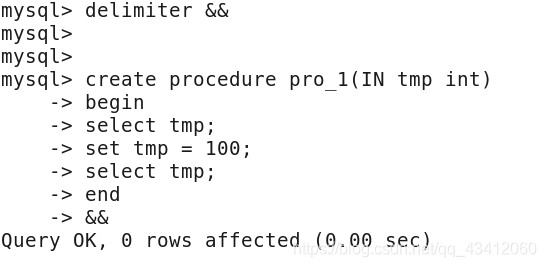
1、输入型
-
定义变量

-
修改结束符,创建存储过程
-
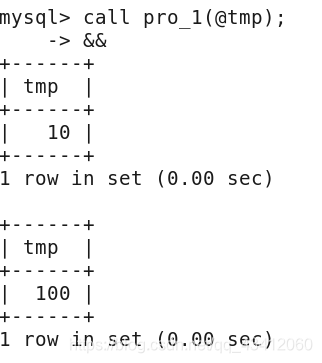
执行存储过程:就是执行存储过程中的流程
-
查看tmp
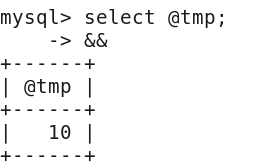
从结果可以看出,并没有改变实参
2、输出型
-
修改结束符,创建存储过程
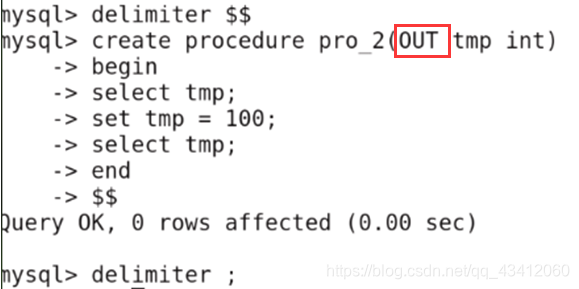
-
执行存储过程:就是执行存储过程中的流程
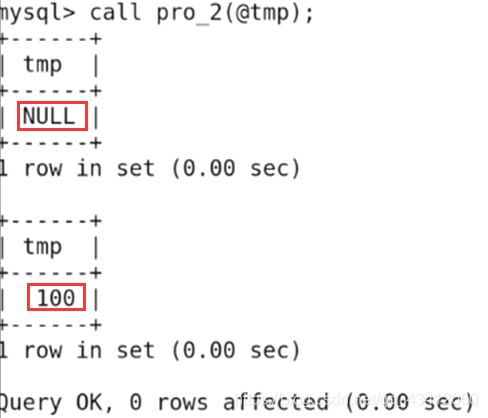
从上面的执行过程可以看出,没有收到实参temp传过来的值,所以打印为NULL,当修改了形参temp的值后,将temp的值给@temp实参,故实参也被修改。 -
查看tmp
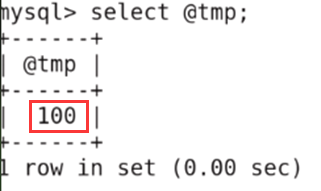
3、输入输出型参数
-
修改结束符,创建存储过程
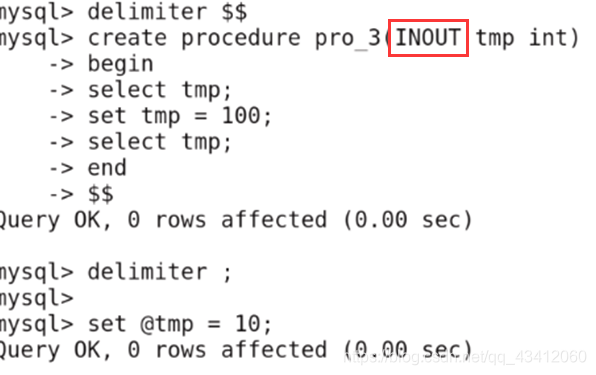
-
执行存储过程:就是执行存储过程中的流程
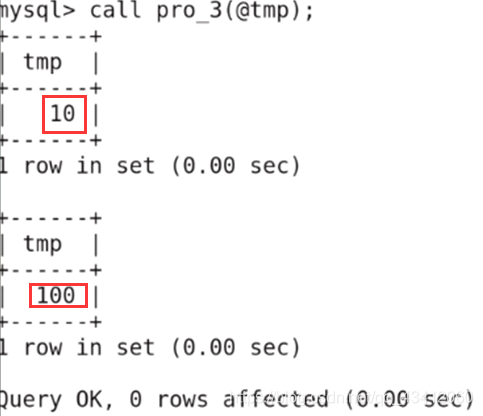
-
查看tmp
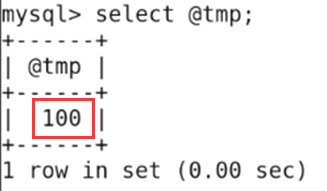
2、删除存储过程或函数
一次只能删除一个存储过程或者函数,删除存储过程或函数需要有该过程或者函数的alter routine权限,具体语法如下:
drop {procedure | function} [if exists] sq_name
【举个栗子】

3、查看存储过程或者函数
SHOW PROCEDURE STATUS LIKE 'pro_book';
SHOW CREATE PROCEDURE pro_book;
DROP PROCEDURE pro_book;
2、存储过程的作用和优点
-
增加性能
:建时已经检查了语法,第一次执行的时候执行计划被创建,被编译,再次执行时不需要重检查语法、不需要重编译,根据已经缓存的计划来决定是否需要重创建执行计划。 -
可保证数据的安全性和完整性
:通过存储过程可以使没有权限的用户在控制之下间接地存取数据库,从而保证数据的安全。通过存储过程可以使相关的动作在一起发生,不要求反复建立一系列处理步骤,从而可以维护数据库的完整性。 -
降低网络的通信量