前言
hadoop的启动模式有三种,一个是本地模式,一个是伪分布式模式,还有一个是集群模式。为了学习hadoop,这里需要搭建一个完全分布式的集群。希望你先把准备工作给看一下,因为我们的配置都是前后一致的。本文因为想让大家学习一下集群分发脚本,所以在模板虚拟机里面少放了很多东西,以后会写一个快速搭建集群的教程。
一、准备工作
首先我们需要多台虚拟机,需要做的工作请看下面这篇博文。
配置hadoop模板虚拟机
二、克隆三台虚拟机并进行网络配置
克隆
找到我们上面配置好的模板虚拟机,打开它,然后右键——》管理——》克隆
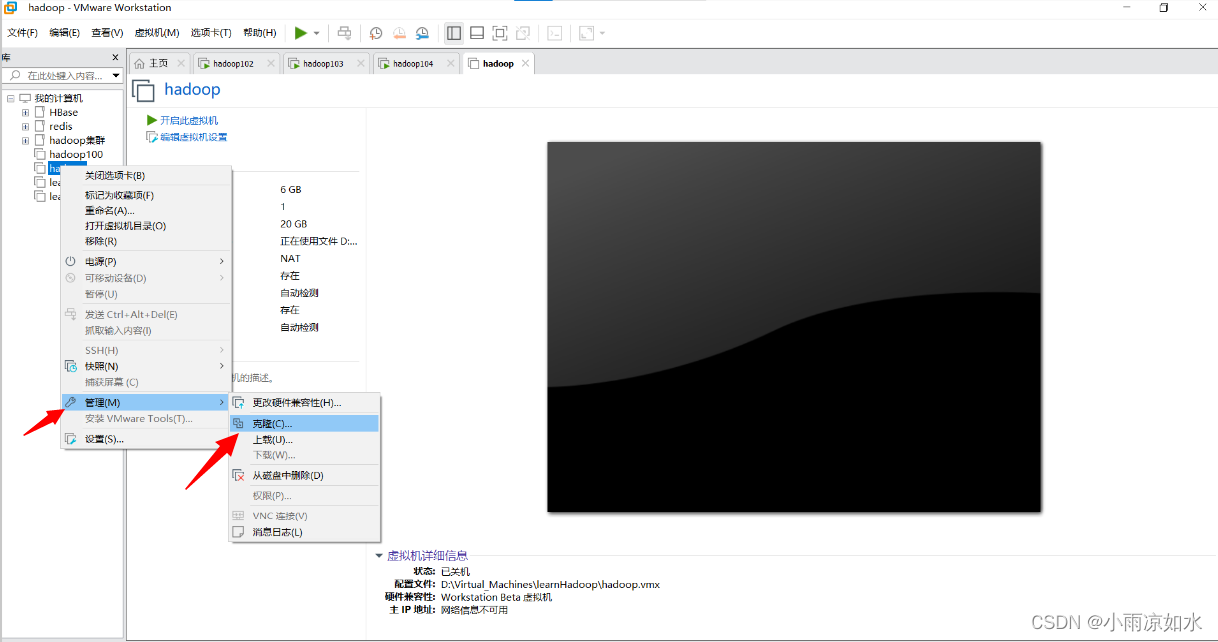
虚拟机克隆引导
在引导的时候,我只说两件事
第一,要选择创建完整克隆
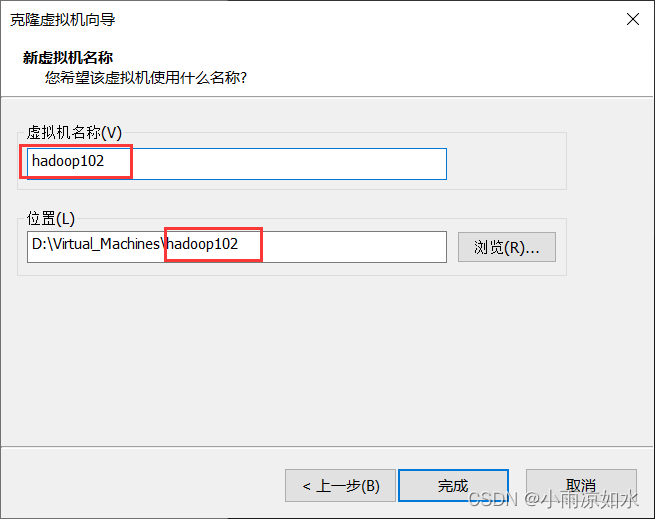
第二,在命名的时候,建议命名成hadoop102,hadoop103,hadoop104
原因有两点:一般hadoop101是用来做伪分布式安装的
第二点,我们的hosts已经修改成了hadoop101~hadoop108
所以,我建议三台虚拟机命名成hadoop102,hadoop103,hadoop104
修改网络配置
让我们开机hadoop102,hadoop103,hadoop104
以管理员的身份登录
首先要强调一点,我们的配置都是前后一致的,一一对应的。
hadoop102 对应的ip地址末尾是102 hostname也是hadoop102
hadoop103 对应的ip地址末尾是103 hostname也是hadoop103
hadoop104 对应的ip地址末尾是104 hostname也是hadoop104
看明白了吗?这些在准备工作里面都配置过,下面的修改也不过是进行了一致性修改。
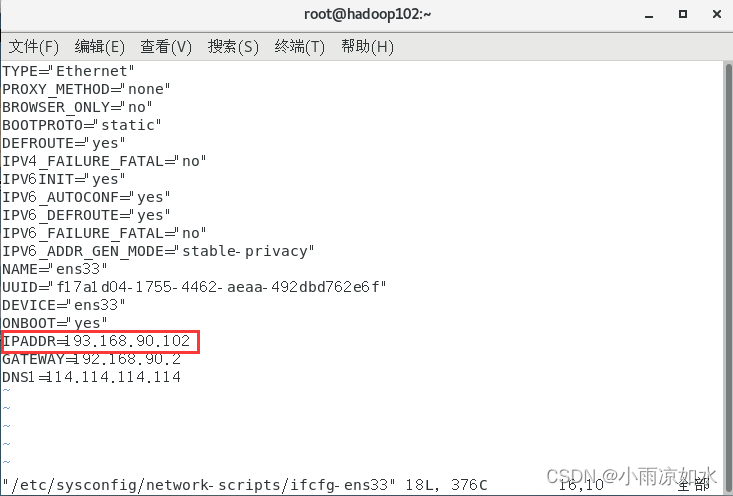
首先,修改ip地址
输入下面的命令
vim /etc/sysconfig/network-scripts/ifcfg-ens33
把 ip地址与名字对应(hadoop102的ip末尾修改成102就行,hadoop103同理)保存退出就行了,毕竟之前我们已经配置了模板虚拟机。
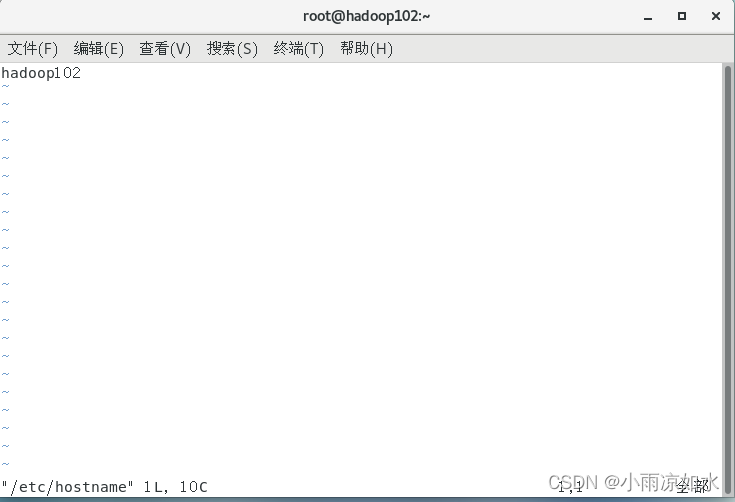
修改hostname
vim /etc/hostname
hadoop102的hostname修改成hadoop102
hadoop103同理
保存退出。输入“
:wq
”
验证
验证方式一
让我们
ping www.baidu.com
验证方式二
打开我们的xshell,
连接这三台虚拟机。(这里不再演示了)
三、安装jdk和hadoop
注:这里在hadoop102安装就行了
(这里主要是为了学习一下分发脚本,不然直接在模板机直接把这些配置好岂不是妙哉?)
四、ssh免密登录配置
概述
在下一大点,我们用了一个分发脚本。
在使用分发脚本传输文件时,必不可少的一项流程是登录到目标机器,也就是要输入密码(可以先试一试第五点的集群分发脚本来体会为什么要设置ssh免密登录),
并且每次传文件都要输密码,所以配置了ssh免密登录,集群之间的机器再传输文件就不需要密码了。
本节使用的是手动配置ssh免密登录(学习一下,知道ssh免密登录怎么配置),
后续可以使用shell脚本来快速配置集群的免密登录
(假设你有n台机器,你要配置
n*n次
的免密登录,非常的麻烦)
生成公钥和私钥
首先,来到hadoop102,使用tom登录(ssh免密登录是分用户的,假设你使用了root管理员来进行免密登录配置,那你只能使用root来免密登录其他的已经配置过免密登录的机器,而本机器上的其他用户是无法进行免密登录的,登录到其他机器还是要输入密码的)
在
tom的家目录(/home/tom)
输入
ls -lah
,你会看到.ssh

如果你没有这个.ssh,也没有关系,可以输入
ssh localhost
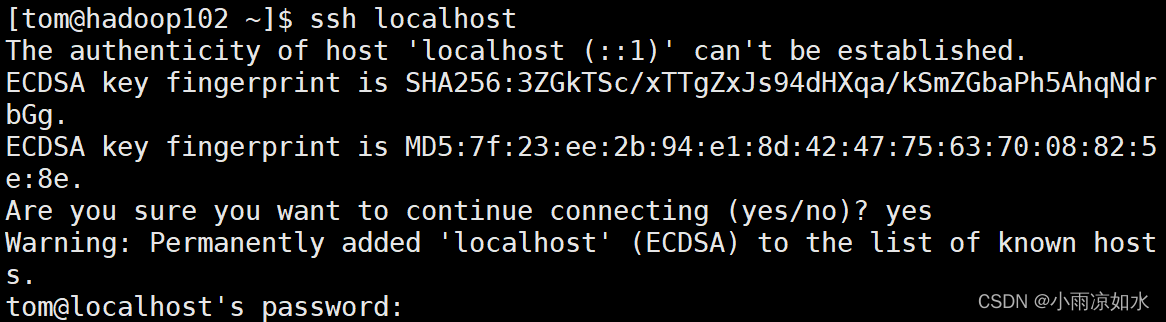
然后输入密码就行了,再输入上面的命令,你就会看到这个.ssh的目录了。
进入.ssh目录
输入
ssh-keygen -t rsa
然后回车三次,生成了公钥和私钥
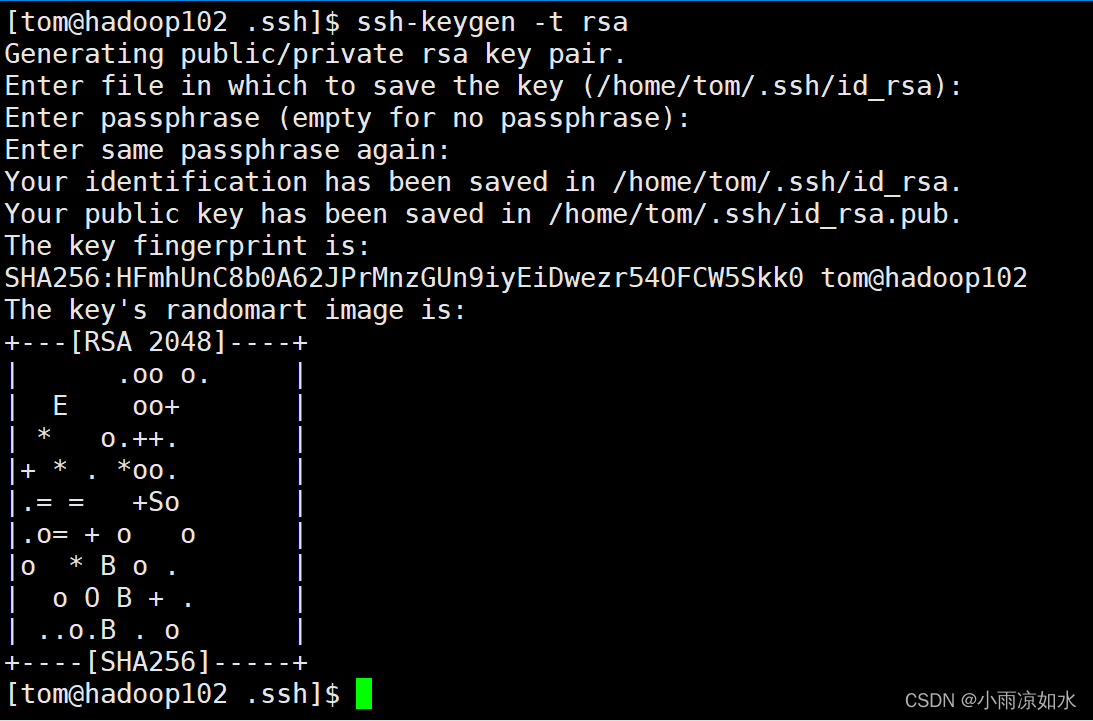
id_rsa 是私钥,id_rsa.pub是公钥

把公钥拷贝到三台虚拟机上面去
依次输入(每次输入的命令需要对应机器的密码)
ssh-copy-id hadoop102
ssh-copy-id hadoop103
ssh-copy-id hadoop104
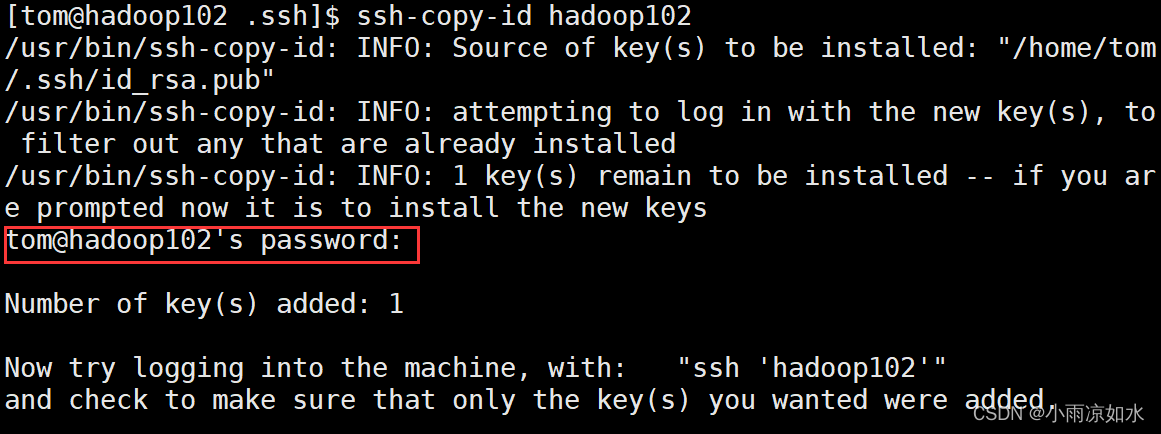
验证
上面的做完了,开始验证是否配置成功
现在我们在hadoop102这台机器上面,我们输入
ssh hadoop102
看看需不需要输密码,如果不需要输密码,就说明我们已经配置成功了

把hadoop103 和 hadoop104的免密登录配置安装上面的操作再做一遍
建议把hadoop102 root 到hadoop102 103 104 的免密登录也配置一下,试了一下集群分发脚本,文件或目录好多因为没有权限而无法创建。
五、集群分发脚本
我们还是使用tom登录hadoop102
我们已经在模板虚拟机的时候就已经安装了rsync(因为每个模板虚拟机都需要这个)
如果你的虚拟机没有rsync
sudo yum install rsync
请在
用户
的
家目录
下
创建
一个
bin
目录,然后输入
vim xsync
下面就是集群分发脚本
(记得先输入 i 进入编辑的模式再复制粘贴脚本代码)
#!/bin/bash
# 1.判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
# 2.遍历机器所有机器
for host in hadoop102 hadoop103 hadoop104
do
echo ================== $host ===============
# 3.遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
# 5.获取父目录
pdir=$(cd -P $(dirname $file);pwd)
# 6.获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
修改脚本权限
chmod 777 xsync
xsync的执行方式就是
xsync 跟上文件或目录的路径就行了
验证全局是否能使用
首先
cd ..
让我随便的创建一个文件
touch a.txt
然后
xsync a.txt
说明
,这个时候大概率可能是不能用的,我试了好几次。
修改文件的路径
我们需要把这个脚本文件移动到一个全部变量的目录里面
sudo cp /home/tom/bin/xsynv /bin
再次验证
我们在/home/tom 的目录下创建了一个 a.txt 文件,现在试一试能不能使用这个东西
cd /home/tom
xsync a.txt
然后登录root账户
su root
mkdir aaa
xsync aaa
如果能执行,就说明我们的分发脚本配置成功了。
六、集群配置
我们要按照这张图来配置集群

注意
NameNode 和 SecondaryNameNode 不要安装在同一台服务器上
ReourceManager 也很消耗内存,不要和NameNode,secondaryNameNode 配置在同一台机器上。
那么应该怎么配置呢?
需要修改相应的配置文件
修改配置文件
所有需要修改的文件都在$HADOOP_HOME/etc/hadoop里面
**注意!!!**如果用tom不能修改,大概率是因为你使用的是root来创建了目录,使用了root来解压文件等原因,执行下面的代码修改
sudo chown -R tom:tom /opt
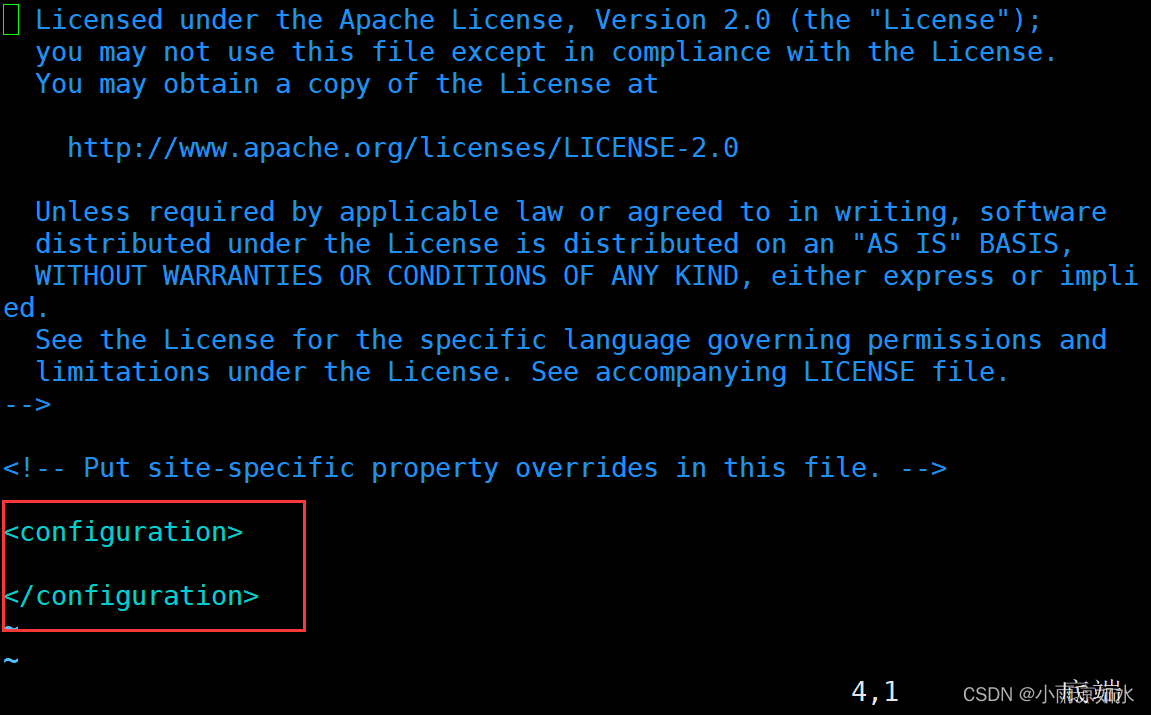
首先修改hadoop102的core-site.xml
下面是需要修改的内容(不要复制粘贴错位置了,xml不再多说了,学过html就很容易懂这种格式)
<configuration>
<!--指定NameNode 的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!--指定hadoop数据的存储目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.3.4/data</value>
</property>
</configuration>
这个是修改的位置
其次修改hadoop102的hdfs-site.xml
<configuration>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!--2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
</configuration>
然后修改hadoop102的yarn-site.xml
<configuration>
<!--指定mapreduce走shuffle-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定ResourceManager的地址-->
<property>
<name>yarn.nodemanager.env-whitelsit</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
再次修改hadoop102的mapred-site.xml
<configuration>
<!--指定MapReduce程序运行在Yarn上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
最后修改workers(2.x版本叫slaves)

修改hadoop-env.sh
这里主要是添加一下java_home
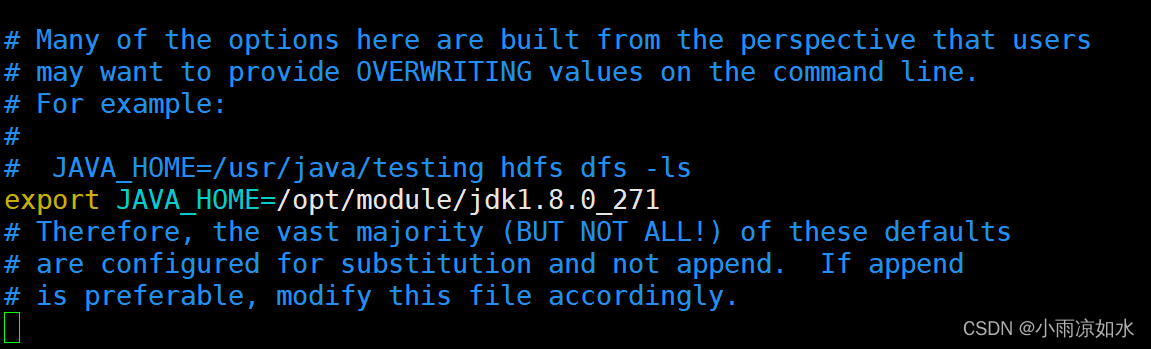
使用xsync来把修改的文件分发出去
在$HADOOP_HOME/etc/ 目录下执行下面的代码
xsync hadoop/
七、启动集群
概述
经过了重重的配置,我们终于要来启动集群了,在启动集群之前,我们还要进行一定的配置
格式化namenode节点
如果集群是第一次启动,需要在hadoop102节点格式化NameNode(注意,格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到以往的数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化)
这个要在hadoop102上运行
hdfs namenode -format
启动hdfs
cd /opt/module/hadoop-3.3.4/sbin
start-dfs.sh
没有error就算是启动成功了

在resourcemanager的节点(hadoop103)启动yarn
一定注意:是在103上面
cd /opt/module/hadoop-3.3.4/sbin
start-yarn.sh

验证
验证方式一

输入
jps
各个虚拟机的节点如果和上面对应出说明启动成功了
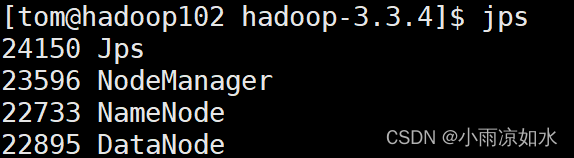
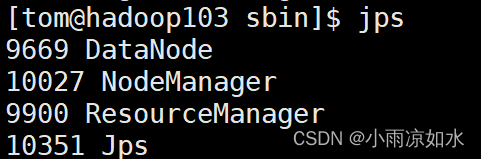
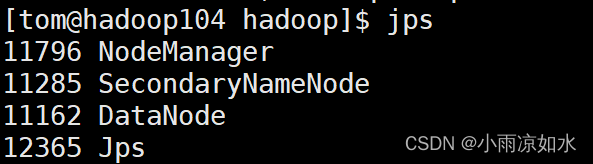
验证方式二
让我们来到浏览器
在框框的地方输入
http://hadoop102:9870
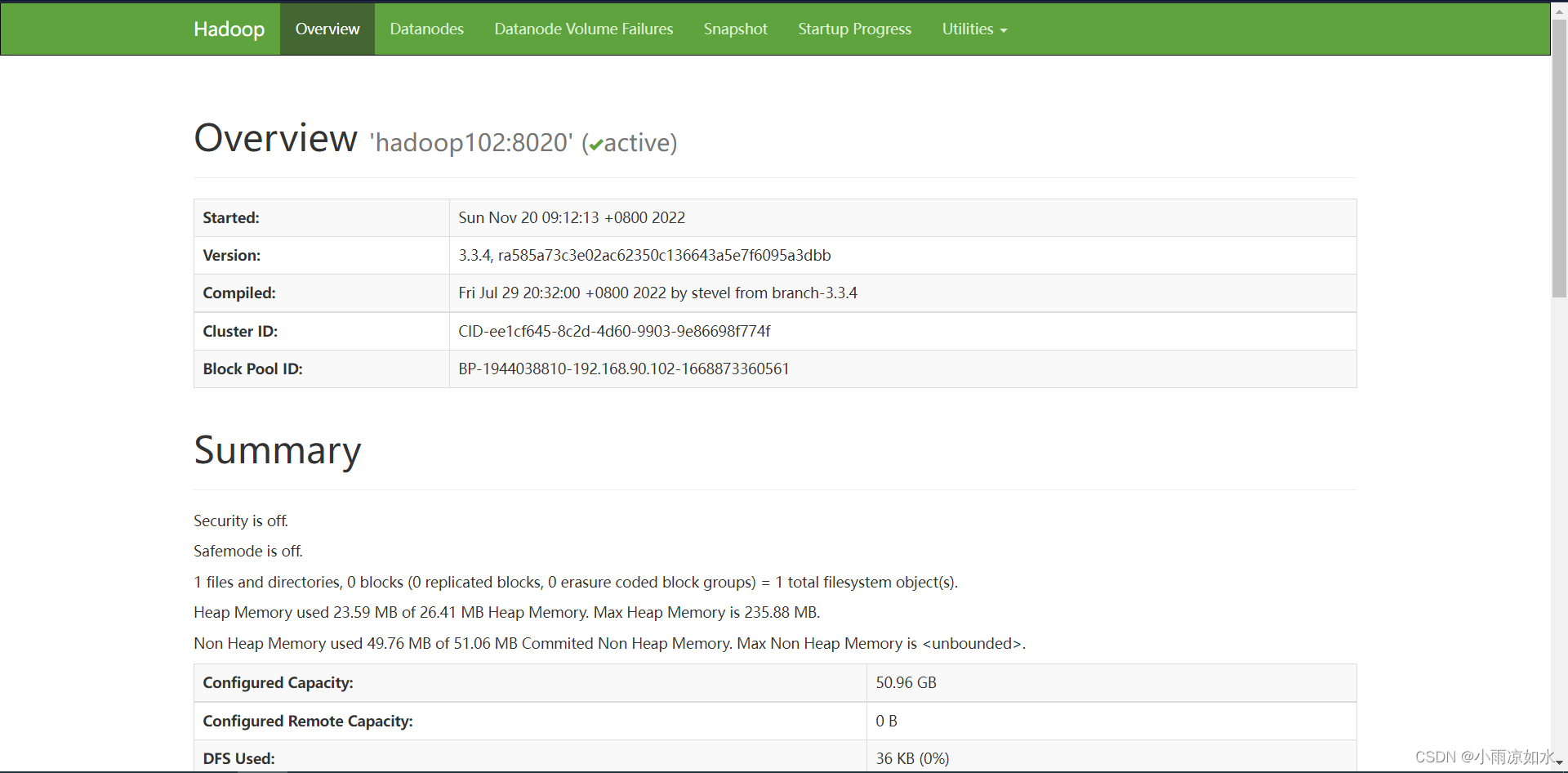
八、配置历史服务器和日志聚集功能
配置历史服务器
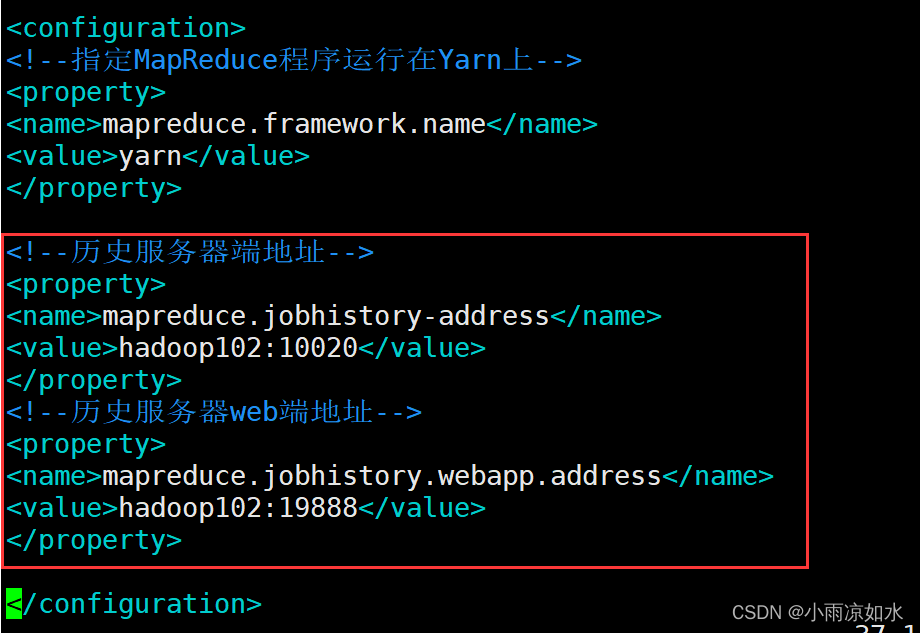
修改hadoop102的mapred-site.xml
<!--历史服务器端地址-->
<property>
<name>mapreduce.jobhistory-address</name>
<value>hadoop102:10020</value>
</property>
<!--历史服务器web端地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>
分发配置
xsync mapred-site.xml
在hadoop102启动历史服务器
启动之前,先把hadoop103上面的yarn给重启了
[tom@hadoop102 hadoop]$ mapred –daemon start historyserver
验证
jps
查看一下是否有
配置日志聚集功能
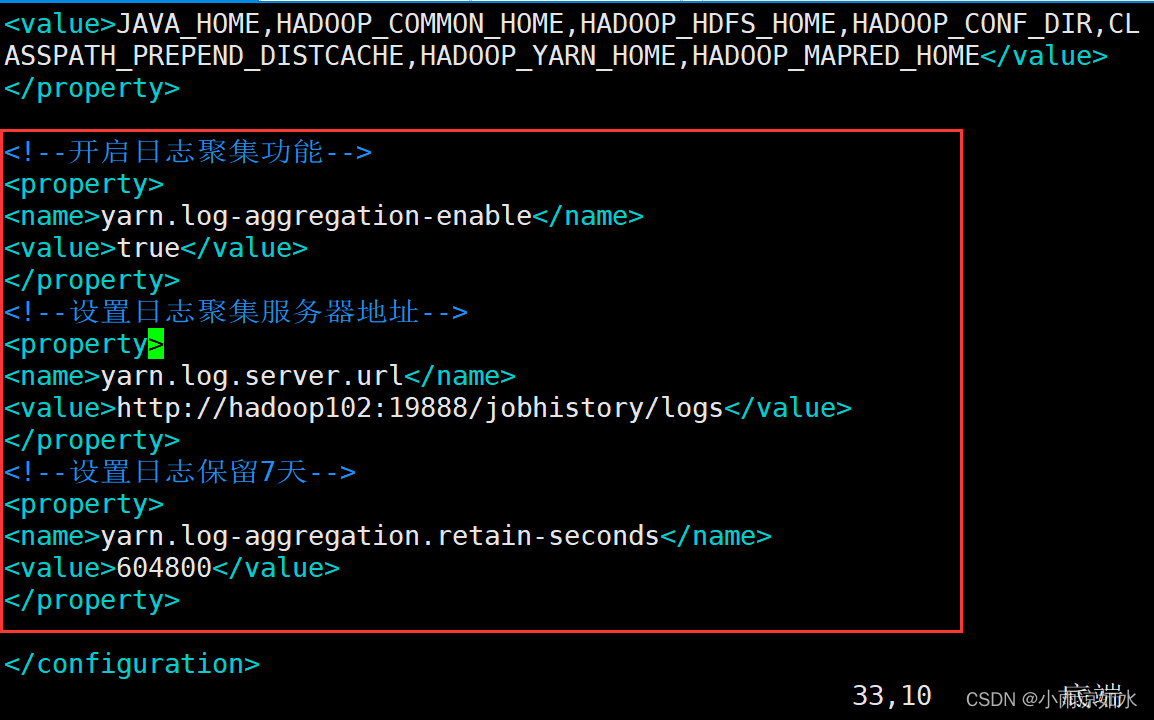
修改hadoop102下面的yarn-site.xml
<!--开启日志聚集功能-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!--设置日志聚集服务器地址-->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!--设置日志保留7天-->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
分发配置
xsync yarn-site.xml
注意:开启日志聚集功能,需要重新启动NodeManager、RescourceManager和HistoryServer
在hadoop102上面
mapred –daemon stop historyserver
在hadoop103上(停止命令是在$HADOOP_HOME/sbin)
sbin/stop-yarn.sh
sbin/start-yarn.sh
然后重启历史服务器
回到hadoop102
mapred –daemon start historyserver
我们的日志聚集功能就算开启了