1 任务定义
给定商品评论数据集,对商品评论进行关键词抽取、情感分析,并对情感分值按月份聚类后用可视化图表呈现。本任务涉及的数据源为2020年美赛C题的三个tsv文件(csv文件以逗号分隔,而tsv文件以\t分隔,在利用pandas读取时需要增加sep参数,并设置为’\t’),本文主要使用该数据集中的最后两个字段:review_body和review_date。
import pandas as pd
hair_dryer=pd.read_csv("./Dataset/hair_dryer.tsv",sep='\t')
microwave=pd.read_csv("./Dataset/microwave.tsv",sep='\t')
pacifier=pd.read_csv("./Dataset/pacifier.tsv",sep='\t')
# 查看hair_dryer的数据
hair_dryer.head(10)
2 实现过程
from snownlp import SnowNLP
import time
import yake
import random
import pandas as pd
2.1 日期数据处理
将字符形式的日期数据转为时间戳保存下来,有利于后续对时间的其它处理(自己的小习惯,当前的小任务用不上时间戳~);将日期转换为年-月格式,有助于后续在可视化时减少横轴的数据项(如果以天为单位会太多啦)。
# 将日期转换为时间戳
def toTimeStamp(review_date):
## 数据中的日期格式为: %m/%d/%Y, 例如: 8/31/2015
timeArray=time.strptime(review_date,'%m/%d/%Y')
timeStamp=int(time.mktime(timeArray))
return timeStamp
# 将日期转换为年-月形式
def year_month(review_date):
month,day,year=review_date.split("/")
## 月份用2位数字表示, 不足两位用0填充
return year+'-{:0>2}'.format(month)
2.2 关键词与情感
- 计算情感得分:使用SnowNLP库的情感得分计算
- 提取关键词:数据为英文文本,这里用yake库的KeywordExtractor对象进行提取
- 保存中间数据:把三种商品的情感得分和关键词都存储到相应的csv文件中
# 三种类型的商品
names={'hair_dryer','microwave','pacifier'}
# 计算情感得分+抽取关键词
def sentiment_count_keyword(name):
## 读取特定商品对应的数据文件(该文件以\t隔开)
df=pd.read_csv("./Dataset/{}.tsv".format(name),sep='\t')
## 将日期转换为时间戳和年-月形式
df['review_stamp']=df['review_date'].apply(toTimeStamp)
df['year_month']=df['review_date'].apply(year_month)
## 创建新DataFrame, 字段包括'review_date','review_body','review_stamp','year_month'
date_comments = df[['review_date','review_body','review_stamp','year_month']]
## 使用SnowNLP计算情感得分
sentiment_list = []
for comment in date_comments['review_body']:
try:
sentiment_list.append(SnowNLP(comment).sentiments)
except:
sentiment_list.append(random.random())
date_comments['sentiment']=sentiment_list
## 使用年-月聚类, 按月份计算情感平均值
sort_comments=date_comments.groupby('year_month')['sentiment'].agg('mean').reset_index().sort_values(by='year_month')
sort_comments['review_count']=date_comments.groupby('year_month')['review_body'].count().tolist()
sort_comments.to_csv('./DataSet/[{}]sentiment_count.csv'.format(name),index=False)
## 使用yake进行关键词抽取
language = "en"
max_ngram_size = 2 #最大关键词语长度
deduplication_threshold = 0.9 #设置在关键词中是否可以重复单词
numOfKeywords = 20
custom_kw_extractor = yake.KeywordExtractor(lan=language, n=max_ngram_size, dedupLim=deduplication_threshold, top=numOfKeywords, features=None)
keywords=[]
for i in range(date_comments.shape[0]):
keyword=custom_kw_extractor.extract_keywords(date_comments.loc[i,'review_body'])
keywords.append([i[0] for i in keyword])
date_comments['keywords']=keywords
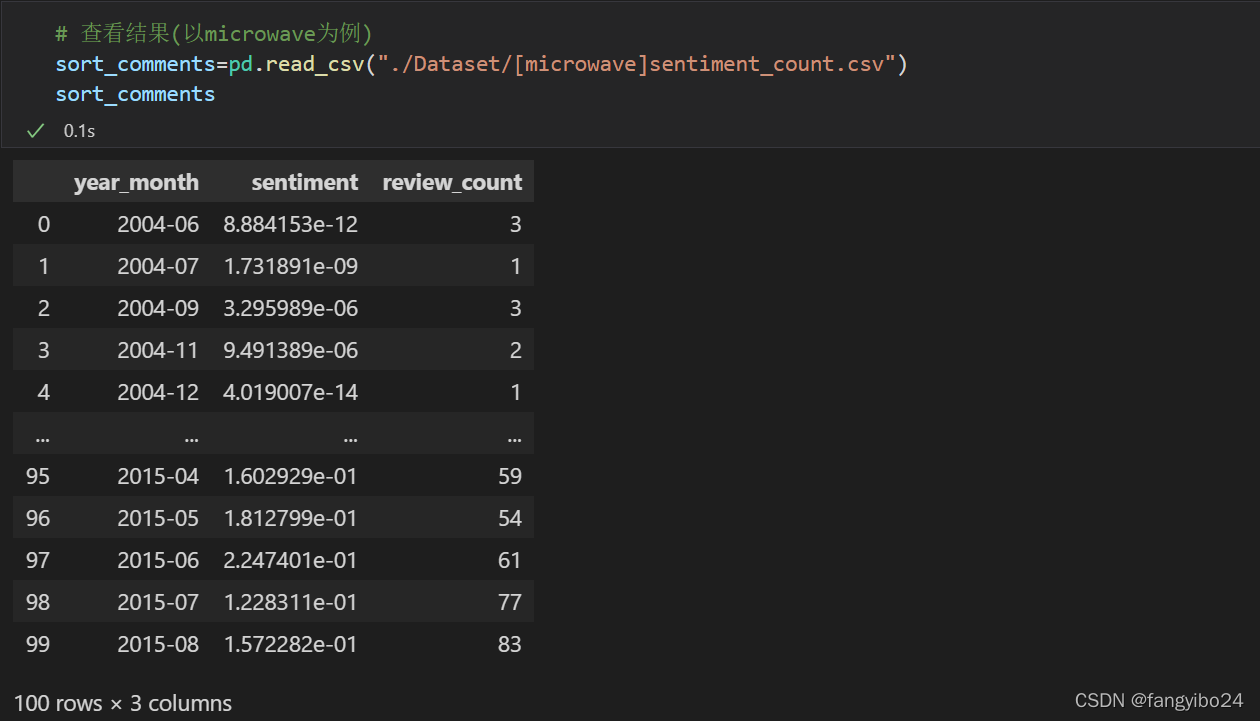
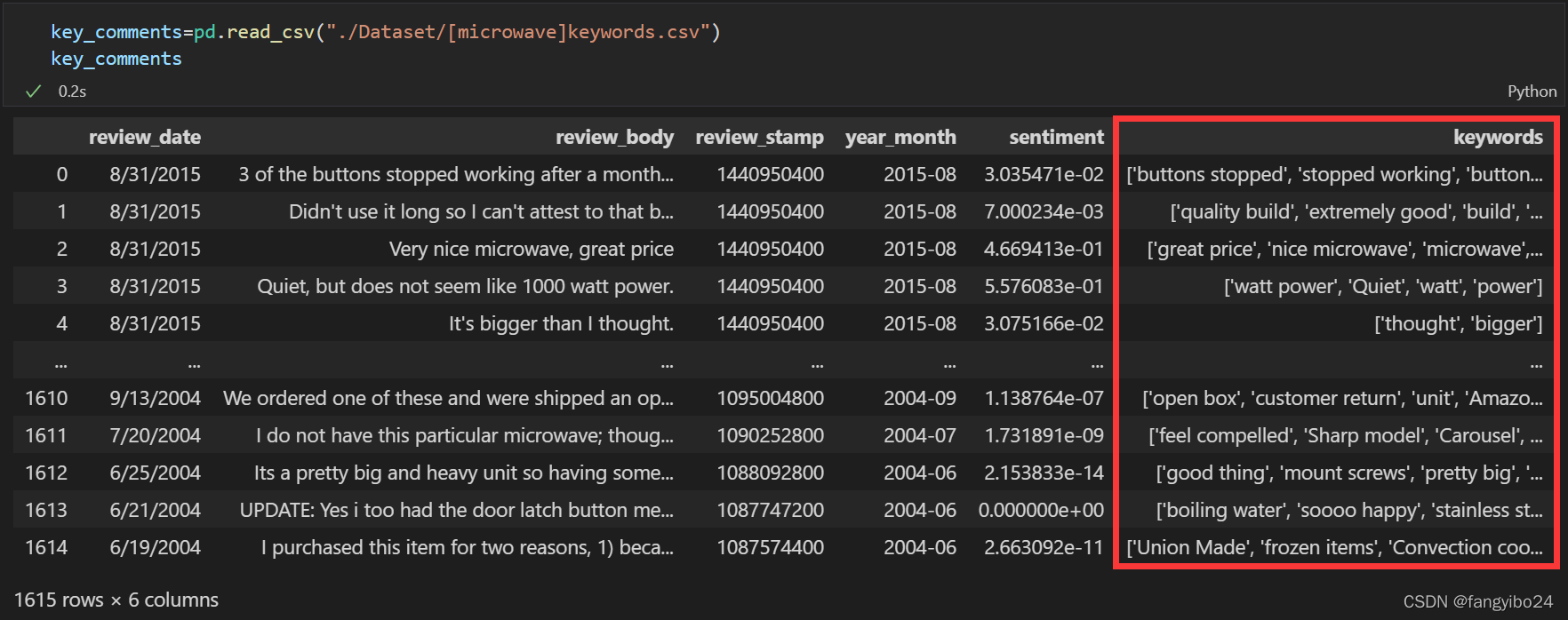
date_comments.to_csv("./DataSet/[{}]keywords.csv".format(name),index=False)查看情感和关键词结果,以microwave商品为例:
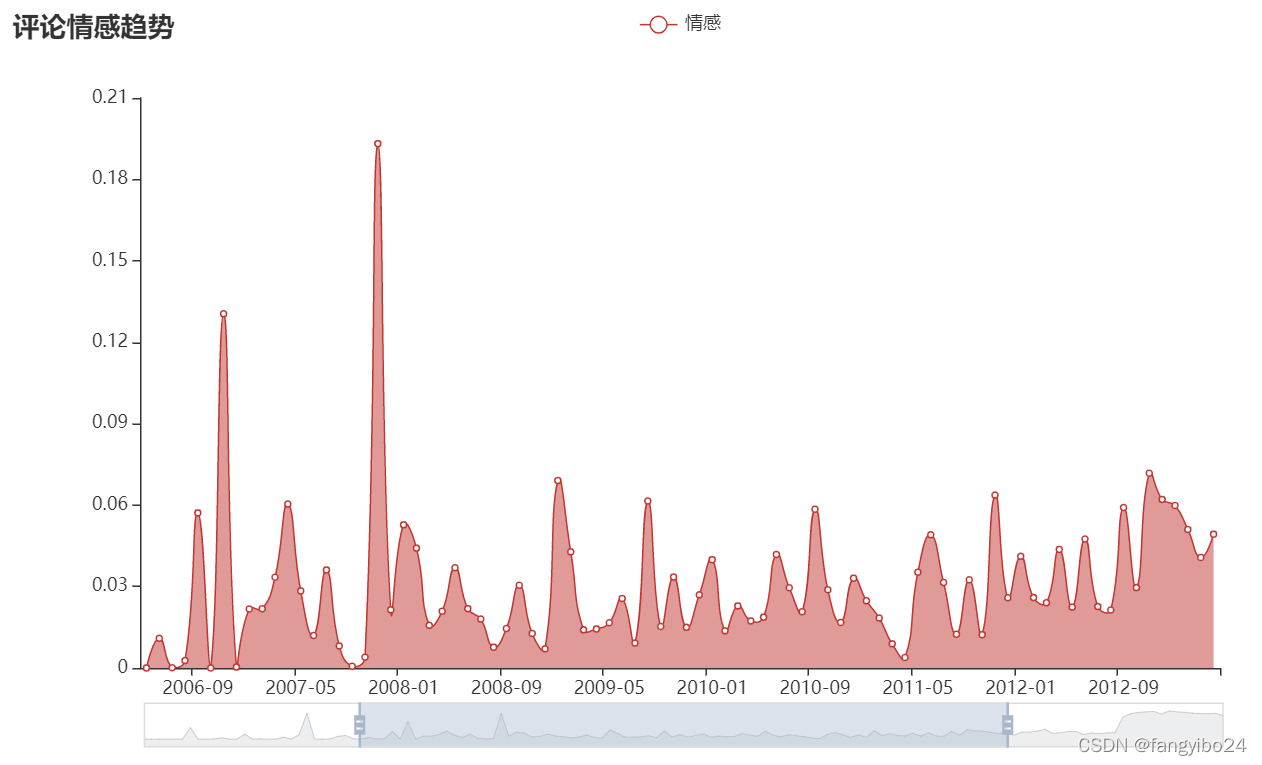
2.3 情感趋势可视化
以microwave的情感得分为例,利用pyecharts绘制折线图如下。
from pyecharts.charts import Line
from pyecharts import options as opts
sort_comments=pd.read_csv("./Dataset/[microwave]sentiment_count.csv")
line = (
Line()
.add_xaxis(list(sort_comments['year_month'].unique()))
.add_yaxis("情感", sort_comments['sentiment'].to_list(), is_smooth=True)
.set_series_opts(
areastyle_opts=opts.AreaStyleOpts(opacity=0.5),
label_opts=opts.LabelOpts(is_show=False),
)
.set_global_opts(
title_opts=opts.TitleOpts(title="评论情感趋势"),
datazoom_opts=opts.DataZoomOpts()
# xaxis_opts=opts.AxisOpts(
# axistick_opts=opts.AxisTickOpts(is_align_with_label=True),
# is_scale=False,
# boundary_gap=False,
# ),
)
.render("./Visual/评论情感趋势.html")
)
版权声明:本文为fangyibo24原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。