这一篇分析以太坊的共识引擎,先看一下各组件之间的关系:
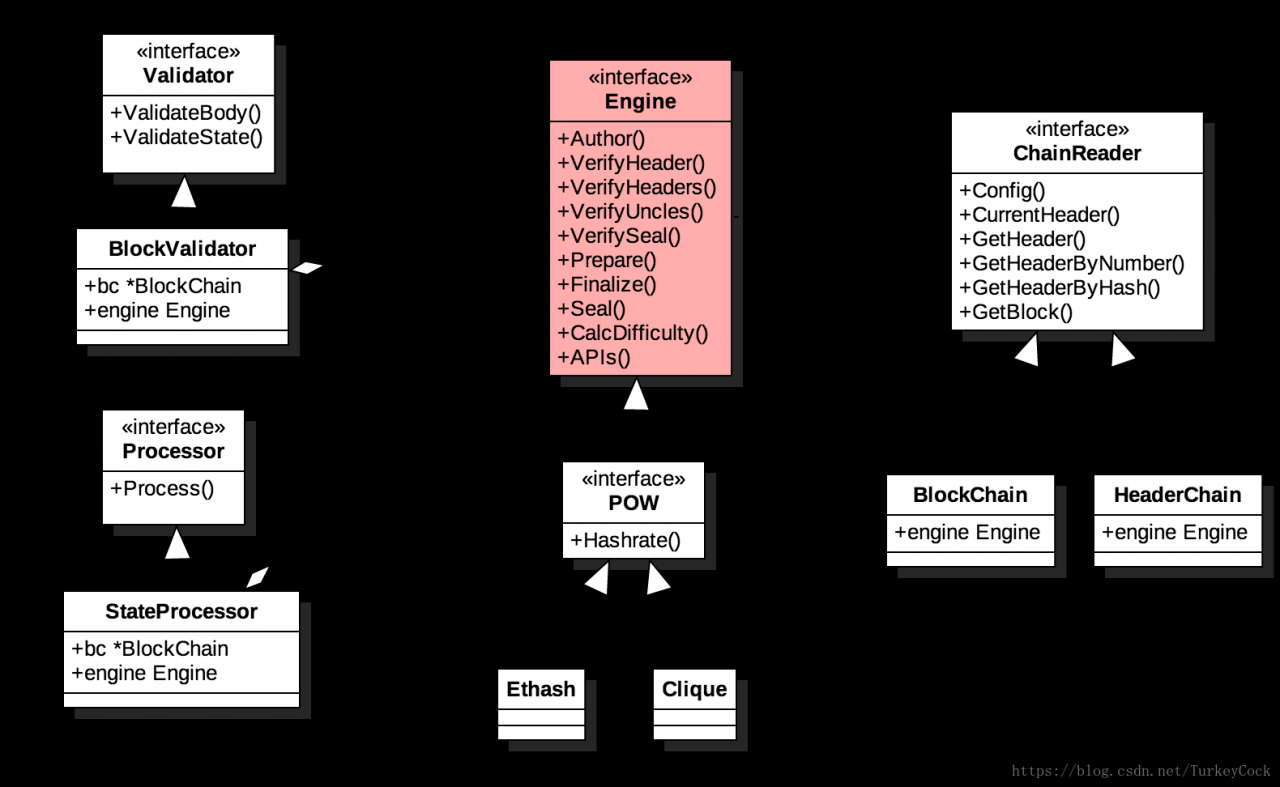
Engine接口定义了共识引擎需要实现的所有函数,实际上按功能可以划分为2类:
- 区块验证类:以Verify开头,当收到新区块时,需要先验证区块的有效性
- 区块盖章类:包括Prepare/Finalize/Seal等,用于最终生成有效区块(比如添加工作量证明)
与区块验证相关联的还有2个外部接口:Processor用于执行交易,而Validator用于验证区块内容和状态。
另外,由于需要访问以前的区块链数据,抽象出了一个ChainReader接口,BlockChain和HeaderChain都实现了该接口以完成对数据的访问。
目前以太坊中实现了两套共识引擎:
- Clique:基于POA(Proof Of Authority)算法,用于测试网络
- Ethash:基于POW(Proof Of Work)算法,用于正式主网
本文主要分析Ethash。
1. 区块验证流程
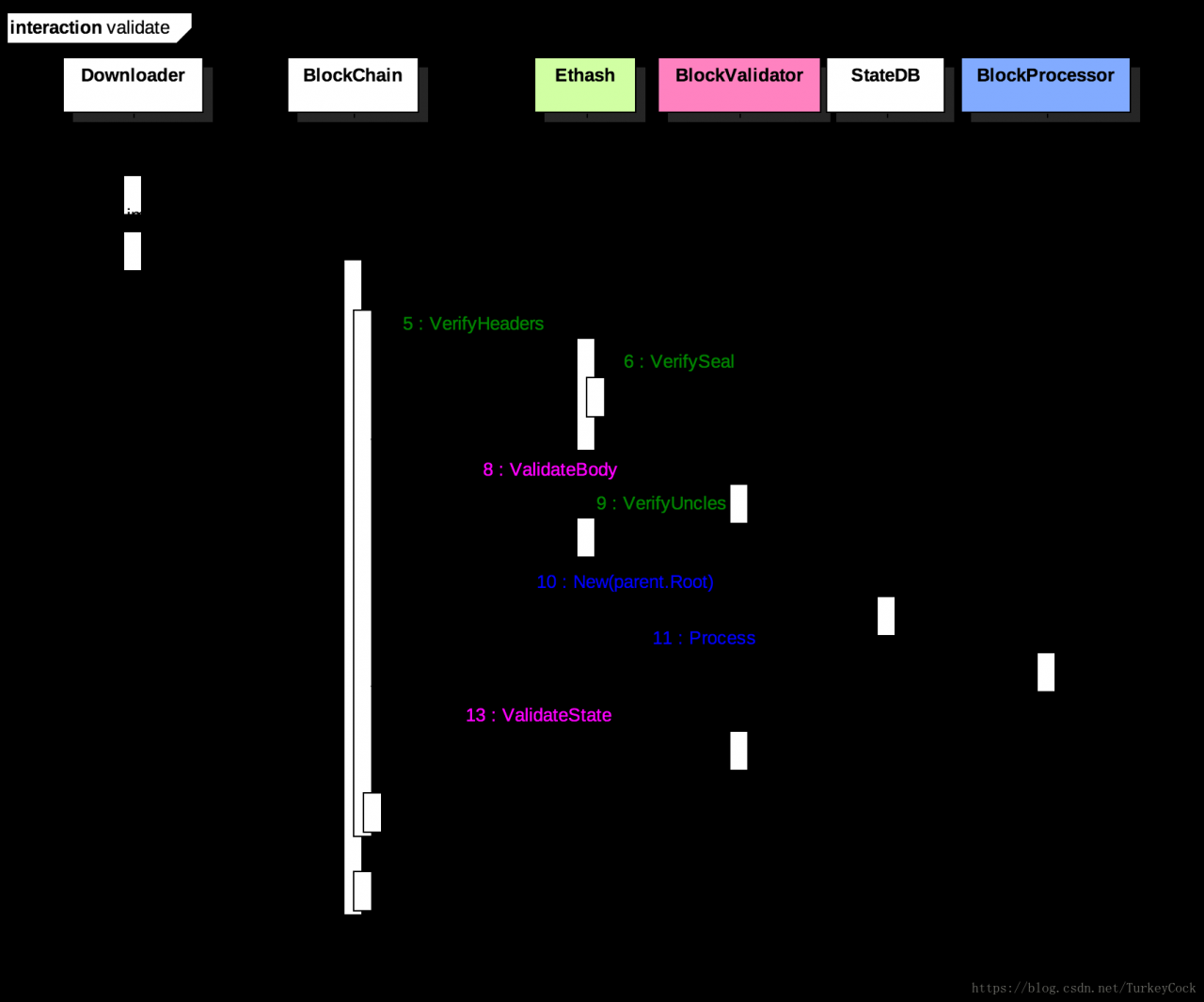
Downloader收到新区块后会调用BlockChain的InsertChain()函数插入新区块。在插入之前需要先要验证区块的有效性,基本分为4个步骤:
- 验证区块头:调用Ethash.VerifyHeaders()
- 验证区块内容:调用BlockValidator.VerifyBody()(内部还会调用Ethash.VerifyUncles())
- 执行区块交易:调用BlockProcessor.Process()(基于其父块的世界状态)
- 验证状态转换:调用BlockValidator.ValidateState()
如果验证成功,则往数据库中写入区块信息,然后广播ChainHeadEvent事件。
2. 区块盖章流程
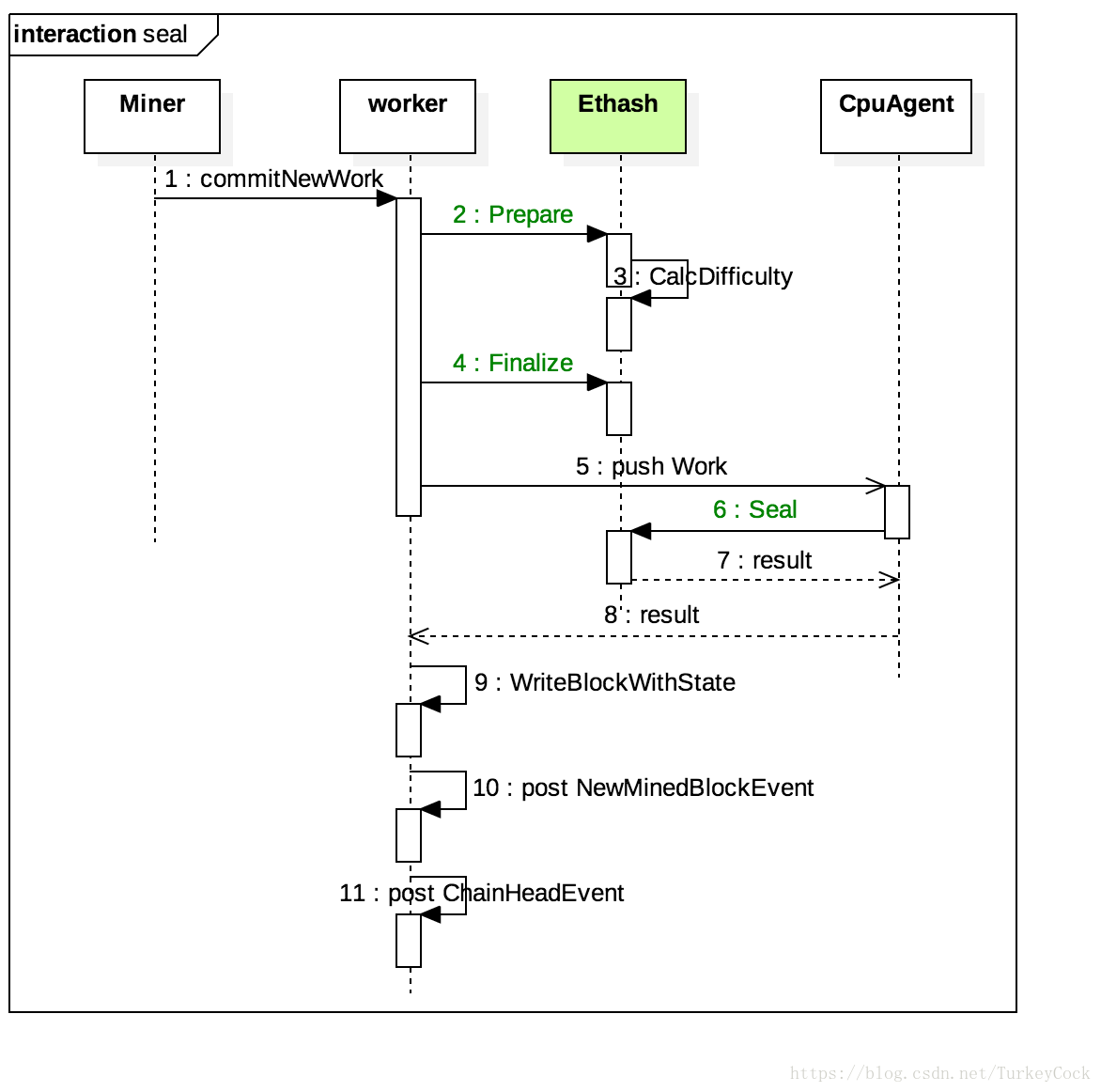
新产生的区块必须经过“盖章(seal)”才能成为有效区块,具体到Ethash来说,就是要执行POW计算以获得低于设定难度的nonce值。这个其实在之前的挖矿流程分析中已经接触过了,主要分为3个步骤:
- 准备工作:调用Ethash.Prepare()计算难度值
- 生成区块:调用Ethash.Finalize()打包新区块
- 盖章:调用Ethash.Seal()进行POW计算,填充nonce值
3. Ethash实现分析
上面已经把基本流程梳理清楚了,所以只需要逐个分析每个函数的具体实现就可以了。
3.1 Ethash.VerifyHeaders()
// Spawn as many workers as allowed threads
workers := runtime.GOMAXPROCS(0)
if len(headers) < workers {
workers = len(headers)
}
首先根据待验证区块的个数确定需要创建的线程数,最大不超过CPU个数。
var (
inputs = make(chan int)
done = make(chan int, workers)
errors = make([]error, len(headers))
abort = make(chan struct{})
)
for i := 0; i < workers; i++ {
go func() {
for index := range inputs {
errors[index] = ethash.verifyHeaderWorker(chain, headers, seals, index)
done <- index
}
}()
}
这一步就是创建线程了,每个线程会从inputs信道中获得待验证区块的索引号,然后调用verifyHeaderWorker()函数验证该区块,验证完后向done信道发送区块索引号。
errorsOut := make(chan error, len(headers))
go func() {
defer close(inputs)
var (
in, out = 0, 0
checked = make([]bool, len(headers))
inputs = inputs
)
for {
select {
case inputs <- in:
if in++; in == len(headers) {
// Reached end of headers. Stop sending to workers.
inputs = nil
}
case index := <-done:
for checked[index] = true; checked[out]; out++ {
errorsOut <- errors[out]
if out == len(headers)-1 {
return
}
}
case <-abort:
return
}
}
}()
return abort, errorsOut
这一步启动一个循环,首先往inputs信道中依次发送区块索引号,然后再从done信道中依次接收子线程处理完成的事件,最后返回验证结果。
接下来我们就分析一下ethash.verifyHeaderWorker()主要做了哪些工作:
func (ethash *Ethash) verifyHeaderWorker(chain consensus.ChainReader, headers []*types.Header, seals []bool, index int) error {
var parent *types.Header
if index == 0 {
parent = chain.GetHeader(headers[0].ParentHash, headers[0].Number.Uint64()-1)
} else if headers[index-1].Hash() == headers[index].ParentHash {
parent = headers[index-1]
}
if parent == nil {
return consensus.ErrUnknownAncestor
}
if chain.GetHeader(headers[index].Hash(), headers[index].Number.Uint64()) != nil {
return nil // known block
}
return ethash.verifyHeader(chain, headers[index], parent, false, seals[index])
}
首先通过ChainReader拿到父块的header,然后调用ethash.verifyHeader(),这个函数就是真正去验证区块头了,具体细节由以太坊黄皮书的4.3.4节所定义。这个函数比较长,大概列一下有哪些检查项:
- 时间戳超前当前时间不得大于15s
- 时间戳必须大于父块时间戳
- 通过父块计算出的难度值必须和区块头难度值相同
- 消耗的gas必须小于gas limit
- 当前gas limit和父块gas limit的差值必须在规定范围内
- 区块高度必须是父块高度+1
- 调用ethash.VerifySeal()检查工作量证明
- 验证硬分叉相关的数据
这里又出现一个ethash.VerifySeal()函数,这个函数主要是用来检查工作量证明,具体细节跟算法相关,后面有时间再详细分析。
3.2 Ethash.VerifyUncles()
这个函数是在BlockValidator.VerifyBody()内部调用的,主要是验证叔块的有效性。函数比较长,我们一段一段地分析。
if len(block.Uncles()) > maxUncles {
return errTooManyUncles
}
这个很简单,以太坊规定每个区块打包的叔块不能超过2个。
uncles, ancestors := set.New(), make(map[common.Hash]*types.Header)
number, parent := block.NumberU64()-1, block.ParentHash()
for i := 0; i < 7; i++ {
ancestor := chain.GetBlock(parent, number)
if ancestor == nil {
break
}
ancestors[ancestor.Hash()] = ancestor.Header()
for _, uncle := range ancestor.Uncles() {
uncles.Add(uncle.Hash())
}
parent, number = ancestor.ParentHash(), number-1
}
ancestors[block.Hash()] = block.Header()
uncles.Add(block.Hash())
这段代码收集了当前块前7层的祖先块和叔块,用于后面的验证。
for _, uncle := range block.Uncles() {
// Make sure every uncle is rewarded only once
hash := uncle.Hash()
if uncles.Has(hash) {
return errDuplicateUncle
}
uncles.Add(hash)
// Make sure the uncle has a valid ancestry
if ancestors[hash] != nil {
return errUncleIsAncestor
}
if ancestors[uncle.ParentHash] == nil || uncle.ParentHash == block.ParentHash() {
return errDanglingUncle
}
if err := ethash.verifyHeader(chain, uncle, ancestors[uncle.ParentHash], true, true); err != nil {
return err
}
}
遍历当前块包含的叔块,做以下检查:
- 如果祖先块中已经包含过了该叔块,返回错误
- 如果发现该叔块其实是一个祖先块(即在主链上),返回错误
- 如果叔块的父块不在这7层祖先中,返回错误
- 如果叔块和当前块拥有共同的父块,返回错误(也就是说不能打包和当前块相同高度的叔块)
- 最后验证一下叔块头的有效性
3.3 BlockValidator.ValidateBody()
func (v *BlockValidator) ValidateBody(block *types.Block) error {
// Check whether the block's known, and if not, that it's linkable
if v.bc.HasBlockAndState(block.Hash(), block.NumberU64()) {
return ErrKnownBlock
}
if !v.bc.HasBlockAndState(block.ParentHash(), block.NumberU64()-1) {
if !v.bc.HasBlock(block.ParentHash(), block.NumberU64()-1) {
return consensus.ErrUnknownAncestor
}
return consensus.ErrPrunedAncestor
}
// Header validity is known at this point, check the uncles and transactions
header := block.Header()
if err := v.engine.VerifyUncles(v.bc, block); err != nil {
return err
}
if hash := types.CalcUncleHash(block.Uncles()); hash != header.UncleHash {
return fmt.Errorf("uncle root hash mismatch: have %x, want %x", hash, header.UncleHash)
}
if hash := types.DeriveSha(block.Transactions()); hash != header.TxHash {
return fmt.Errorf("transaction root hash mismatch: have %x, want %x", hash, header.TxHash)
}
return nil
}
这段代码比较简单,主要是用来验证区块内容的。
首先判断当前数据库中是否已经包含了该区块,如果已经有了的话返回错误。
接着判断当前数据库中是否包含该区块的父块,如果没有的话返回错误。
然后验证叔块的有效性及其hash值,最后计算块中交易的hash值并验证是否和区块头中的hash值一致。
3.4 BlockProcessor.Process()
func (p *StateProcessor) Process(block *types.Block, statedb *state.StateDB, cfg vm.Config) (types.Receipts, []*types.Log, uint64, error) {
var (
receipts types.Receipts
usedGas = new(uint64)
header = block.Header()
allLogs []*types.Log
gp = new(GasPool).AddGas(block.GasLimit())
)
// Mutate the the block and state according to any hard-fork specs
if p.config.DAOForkSupport && p.config.DAOForkBlock != nil && p.config.DAOForkBlock.Cmp(block.Number()) == 0 {
misc.ApplyDAOHardFork(statedb)
}
// Iterate over and process the individual transactions
for i, tx := range block.Transactions() {
statedb.Prepare(tx.Hash(), block.Hash(), i)
receipt, _, err := ApplyTransaction(p.config, p.bc, nil, gp, statedb, header, tx, usedGas, cfg)
if err != nil {
return nil, nil, 0, err
}
receipts = append(receipts, receipt)
allLogs = append(allLogs, receipt.Logs...)
}
// Finalize the block, applying any consensus engine specific extras (e.g. block rewards)
p.engine.Finalize(p.bc, header, statedb, block.Transactions(), block.Uncles(), receipts)
return receipts, allLogs, *usedGas, nil
}
这段代码其实跟挖矿代码中执行交易是一模一样的,首先调用Prepare()计算难度值,然后调用ApplyTransaction()执行交易并获取交易回执和消耗的gas值,最后通过Finalize()生成区块。
值得注意的是,传进来的StateDB是父块的世界状态,执行交易会改变这些状态,为下一步验证状态转移相关的字段做准备。
3.5 BlockValidator.ValidateState()
func (v *BlockValidator) ValidateState(block, parent *types.Block, statedb *state.StateDB, receipts types.Receipts, usedGas uint64) error {
header := block.Header()
if block.GasUsed() != usedGas {
return fmt.Errorf("invalid gas used (remote: %d local: %d)", block.GasUsed(), usedGas)
}
// Validate the received block's bloom with the one derived from the generated receipts.
// For valid blocks this should always validate to true.
rbloom := types.CreateBloom(receipts)
if rbloom != header.Bloom {
return fmt.Errorf("invalid bloom (remote: %x local: %x)", header.Bloom, rbloom)
}
// Tre receipt Trie's root (R = (Tr [[H1, R1], ... [Hn, R1]]))
receiptSha := types.DeriveSha(receipts)
if receiptSha != header.ReceiptHash {
return fmt.Errorf("invalid receipt root hash (remote: %x local: %x)", header.ReceiptHash, receiptSha)
}
// Validate the state root against the received state root and throw
// an error if they don't match.
if root := statedb.IntermediateRoot(v.config.IsEIP158(header.Number)); header.Root != root {
return fmt.Errorf("invalid merkle root (remote: %x local: %x)", header.Root, root)
}
return nil
}
这部分代码主要是用来验证区块中和状态转换相关的字段是否正确,包含以下几个部分:
- 判断刚刚执行交易消耗的gas值是否和区块头中的值相同
- 根据刚刚执行交易获得的交易回执创建Bloom过滤器,判断是否和区块头中的Bloom过滤器相同(Bloom过滤器是一个2048位的字节数组)
- 判断交易回执的hash值是否和区块头中的值相同
- 计算StateDB中的MPT的Merkle Root,判断是否和区块头中的值相同
至此,区块验证流程就走完了,新区块将被写入数据库,同时更新世界状态。
3.6 Ethash.Prepare()
func (ethash *Ethash) Prepare(chain consensus.ChainReader, header *types.Header) error {
parent := chain.GetHeader(header.ParentHash, header.Number.Uint64()-1)
if parent == nil {
return consensus.ErrUnknownAncestor
}
header.Difficulty = ethash.CalcDifficulty(chain, header.Time.Uint64(), parent)
return nil
}
可以看到,会调用CalcDifficulty()计算难度值,继续跟踪:
func (ethash *Ethash) CalcDifficulty(chain consensus.ChainReader, time uint64, parent *types.Header) *big.Int {
return CalcDifficulty(chain.Config(), time, parent)
}
func CalcDifficulty(config *params.ChainConfig, time uint64, parent *types.Header) *big.Int {
next := new(big.Int).Add(parent.Number, big1)
switch {
case config.IsByzantium(next):
return calcDifficultyByzantium(time, parent)
case config.IsHomestead(next):
return calcDifficultyHomestead(time, parent)
default:
return calcDifficultyFrontier(time, parent)
}
}
根据以太坊的Roadmap,会经历Frontier,Homestead,Metropolis,Serenity这几个大的版本,当前处于Metropolis阶段。Metropolis又分为2个小版本:Byzantium和Constantinople,目前的最新代码版本是Byzantium,因此会调用calcDifficultyByzantium()函数。
计算难度的公式如下:
diff = (parent_diff +
(parent_diff / 2048 * max((2 if len(parent.uncles) else 1) – ((timestamp – parent.timestamp) // 9), -99))
) + 2^(periodCount – 2)
前面一项是根据父块难度值继续难度调整,而后面一项就是传说中的“难度炸弹”。关于难度炸弹相关的具体细节可以参考下面这篇文章:
https://juejin.im/post/59ad6606f265da246f382b88
由于PoS共识机制开发进度延迟,不得不减小难度炸弹从而延迟“冰川时代”的到来,具体做法就是把当前区块高度减小3000000,参见以下代码:
// calculate a fake block number for the ice-age delay:
// https://github.com/ethereum/EIPs/pull/669
// fake_block_number = min(0, block.number - 3_000_000
fakeBlockNumber := new(big.Int)
if parent.Number.Cmp(big2999999) >= 0 {
fakeBlockNumber = fakeBlockNumber.Sub(parent.Number, big2999999) // Note, parent is 1 less than the actual block number
}
3.7 Ethash.Finalize()
func (ethash *Ethash) Finalize(chain consensus.ChainReader, header *types.Header, state *state.StateDB, txs []*types.Transaction, uncles []*types.Header, receipts []*types.Receipt) (*types.Block, error) {
// Accumulate any block and uncle rewards and commit the final state root
accumulateRewards(chain.Config(), state, header, uncles)
header.Root = state.IntermediateRoot(chain.Config().IsEIP158(header.Number))
// Header seems complete, assemble into a block and return
return types.NewBlock(header, txs, uncles, receipts), nil
}
这个其实之前分析挖矿流程的时候已经分析过了,先计算收益,然后生成MPT的Merkle Root,最后创建新区块。
3.8 Ethash.Seal()
这个函数就是真正执行POW计算的地方了,代码位于consensus/ethash/sealer.go。代码比较长,分段进行分析:
abort := make(chan struct{})
found := make(chan *types.Block)
首先创建了两个channel,用于退出和发现nonce时发送事件。
ethash.lock.Lock()
threads := ethash.threads
if ethash.rand == nil {
seed, err := crand.Int(crand.Reader, big.NewInt(math.MaxInt64))
if err != nil {
ethash.lock.Unlock()
return nil, err
}
ethash.rand = rand.New(rand.NewSource(seed.Int64()))
}
ethash.lock.Unlock()
if threads == 0 {
threads = runtime.NumCPU()
}
接着初始化随机数种子和线程数。
var pend sync.WaitGroup
for i := 0; i < threads; i++ {
pend.Add(1)
go func(id int, nonce uint64) {
defer pend.Done()
ethash.mine(block, id, nonce, abort, found)
}(i, uint64(ethash.rand.Int63()))
}
然后就是创建线程进行挖矿了,会调用ethash.mine()函数(后面分析)。
// Wait until sealing is terminated or a nonce is found
var result *types.Block
select {
case <-stop:
// Outside abort, stop all miner threads
close(abort)
case result = <-found:
// One of the threads found a block, abort all others
close(abort)
case <-ethash.update:
// Thread count was changed on user request, restart
close(abort)
pend.Wait()
return ethash.Seal(chain, block, stop)
}
// Wait for all miners to terminate and return the block
pend.Wait()
return result, nil
最后就是等待挖矿结果了,有可能找到nonce挖矿成功,也有可能别人先挖出了区块从而需要终止挖矿。
接下来我们看一下ethash.mine()函数的实现,先看一些变量声明:
var (
header = block.Header()
hash = header.HashNoNonce().Bytes()
target = new(big.Int).Div(maxUint256, header.Difficulty)
number = header.Number.Uint64()
dataset = ethash.dataset(number)
)
// Start generating random nonces until we abort or find a good one
var (
attempts = int64(0)
nonce = seed
)
其中hash指的是不带nonce的区块头hash值,nonce是一个随机数种子。target是目标值,等于2^256除以难度值,我们接下来要计算的hash值必须小于这个目标值才算挖矿成功。
接下来就是不断修改nonce并计算hash值了:
digest, result := hashimotoFull(dataset.dataset, hash, nonce)
if new(big.Int).SetBytes(result).Cmp(target) <= 0 {
// Correct nonce found, create a new header with it
header = types.CopyHeader(header)
header.Nonce = types.EncodeNonce(nonce)
header.MixDigest = common.BytesToHash(digest)
// Seal and return a block (if still needed)
select {
case found <- block.WithSeal(header):
logger.Trace("Ethash nonce found and reported", "attempts", nonce-seed, "nonce", nonce)
case <-abort:
logger.Trace("Ethash nonce found but discarded", "attempts", nonce-seed, "nonce", nonce)
}
break search
}
nonce++
hashimotoFull()函数内部会把hash和nonce拼在一起,计算出一个摘要(digest)和一个hash值(result)。如果hash值满足难度要求,挖矿成功,填充区块头的Nonce和MixDigest字段,然后调用block.WithSeal()生成盖过章的区块:
func (b *Block) WithSeal(header *Header) *Block {
cpy := *header
return &Block{
header: &cpy,
transactions: b.transactions,
uncles: b.uncles,
}
}
更多文章欢迎关注“鑫鑫点灯”专栏:https://blog.csdn.net/turkeycock/article/category/7669858
或关注飞久微信公众号:
