一、低内存终止守护程序
Android 低内存终止守护程序 (lmkd) 进程可监控运行中的 Android 系统的内存状态,并通过终止最不必要的进程来应对内存压力大的问题,使系统以可接受的性能水平运行。
所有应用进程都是从zygote孵化出来的,记录在AMS中mLruProcesses列表中,由AMS进行统一管理,AMS中会根据进程的状态更新进程对应的oom_adj值,这个值会通过socket传递给lmkd。lmdk根据内核的版本情况,或传递给kernel或自身处理低内存回收机制。为腾出更多的内存空间,在内存达到一定阀值时会触发清理oom_adj值高的进程。
1. 内存压力简介
并行运行多个进程的 Android 系统可能会遇到系统内存耗尽,需要更多内存的进程出现明显延迟的情况。内存压力是系统内存不足的一种状态,它需要 Android 通过限制或终止不必要的进程、请求进程释放非关键缓存资源等方式来释放内存(以缓解这种压力)。
过去,Android 使用内核中的低内存终止守护程序 (LMK) 驱动程序来监控系统内存压力,该驱动程序是一种依赖于硬编码值的严格机制。从内核 4.12 开始,LMK 驱动程序已从上游内核中移除,改由用户空间 lmkd 来执行内存监控和进程终止任务。
2. 压力失速信息
Android 10 及更高版本支持新的 lmkd 模式,它使用内核压力失速信息 (PSI) 监视器来检测内存压力。上游内核中的 PSI 补丁程序集(已向后移植到 4.9 和 4.14 内核)可测量由于内存不足导致任务延迟的时间。由于这些延迟会直接影响用户体验,因此它们代表了确定内存压力严重性的便捷指标。上游内核还包括 PSI 监视器,这类监视器允许特权用户空间进程(例如 lmkd)指定这些延迟的阈值,并在突破阈值时从内核订阅事件。
① PSI 监视器与 vmpressure 信号
由于 vmpressure 信号(由内核生成,用于检测内存压力并由 lmkd 使用)通常包含大量误报,因此 lmkd 必须执行过滤以确定是否真的存在内存压力。这会导致不必要的 lmkd 唤醒并使用额外的计算资源。使用 PSI 监视器可以实现更精确的内存压力检测,并最大限度地减少过滤开销。
②使用 PSI 监视器
如需使用 PSI 监视器(而不是 vmpressure 事件),请配置 ro.lmk.use_psi 属性。默认值为 true,这会以 PSI 监视器作为 lmkd 内存压力检测的默认机制。由于 PSI 监视器需要内核支持,因此内核必须包含 PSI 向后移植补丁程序,并在启用 PSI 支持 (CONFIG_PSI=y) 的情况下进行编译。
3. 内核中 LMK 驱动程序的缺点
由于存在大量问题,Android 弃用了 LMK 驱动程序,问题包括:
- 对于低内存设备,必须主动进行调整,即便如此,在处理涉及支持大文件的活跃页面缓存的工作负载时,其性能也较差。性能不良会导致出现抖动,但不会终止。
- LMK 内核驱动程序依赖于可用内存限制,不会根据内存压力进行扩缩。
- 由于设计的严格性,合作伙伴通常会自定义该驱动程序,使其可以在自己的设备上使用。
- LMK 驱动程序已挂接到 Slab Shrinker API,该 API 并非为了执行繁重操作(例如搜索并终止目标)而设计,这类操作会导致 vmscan 进程变慢。
4. 用户空间 lmkd
用户空间 lmkd 可实现与内核中的驱动程序相同的功能,但它使用现有的内核机制检测和评估内存压力。这些机制包括使用内核生成的 vmpressure 事件或压力失速信息 (PSI) 监视器来获取关于内存压力水平的通知,以及使用内存 cgroup 功能限制根据进程的重要性分配给每个进程的内存资源。
在 Android 10 中使用用户空间 lmkd
在 Android 9 及更高版本中,用户空间 lmkd 会在未检测到内核中的 LMK 驱动程序时激活。由于用户空间 lmkd 要求内核支持内存 cgroup,因此必须使用以下配置设置编译内核:
CONFIG_ANDROID_LOW_MEMORY_KILLER=n
CONFIG_MEMCG=y
CONFIG_MEMCG_SWAP=y
终止策略
用户空间 lmkd 支持基于以下各项的终止策略:vmpressure 事件或 PSI 监视器、其严重性以及交换利用率等其他提示。低内存设备和高性能设备的终止策略有所不同:
- 对于内存不足的设备,一般情况下,系统会选择承受较大的内存压力。
- 对于高性能设备,如果出现内存压力,则会视为异常情况,应及时修复,以免影响整体性能。
您可以使用 ro.config.low_ram 属性配置终止策略。如需了解详情,请参阅
低 RAM 配置
。
用户空间 lmkd 还支持一种旧模式,在该模式下,它使用与内核中的 LMK 驱动程序相同的策略(即可用内存和文件缓存阈值)做出终止决策。要启用旧模式,请将 ro.lmk.use_minfree_levels 属性设置为 true。
5. 图解
5-1. LMK/LMKD

5-2. lmkd kill process flow
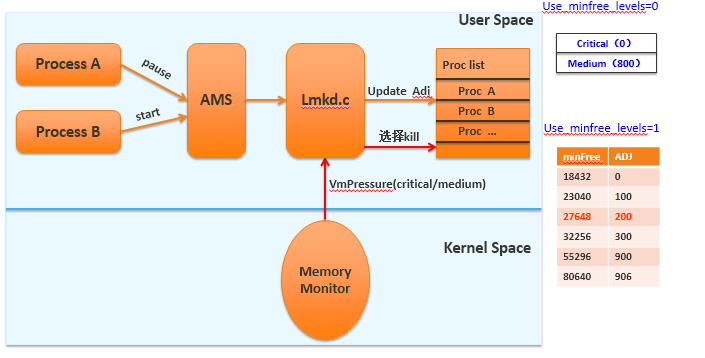
lmkd can use minfree table to adjust which adj process to kill (ro.lmk.use_minfree_levels=1)
or use medium/critical pressure to adjust which adj process to kill (ro.lmk.use_minfree_levels=0).
the midum/citical pressure adjust was configured by ro.lmk.medium/ro.lmk.critical , which default value was 800/0 .
lmkd log:(in main log)
ro.lmk.use_minfree_levels=1
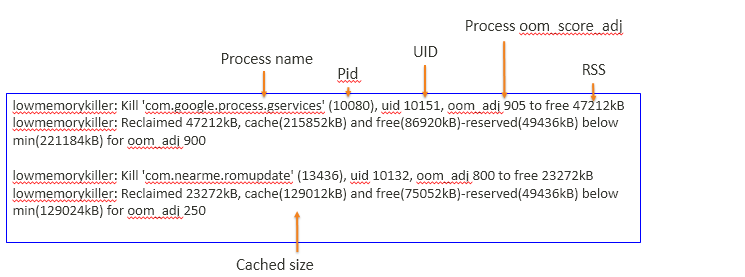
ro.lmk.use_minfree_levels=0

5-3. lmk kill process flow
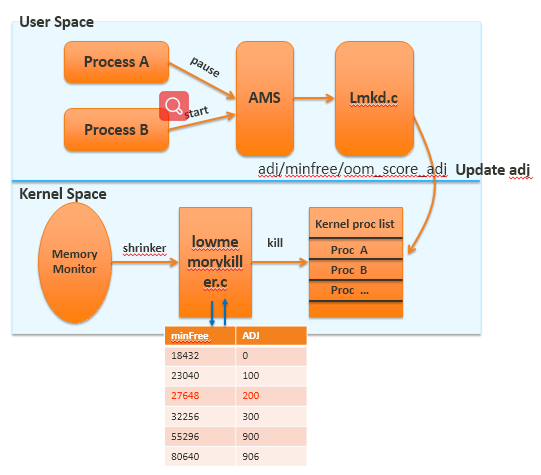
lmk log: (in kernel log)

6 .minfree table & oom adj
6.1 minfree table
adb shell cat /sys/module/lowmemorykiller/parameters/minfree
或者
adb root
adb shell getprop |grep minfree
[sys.lmk.minfree_levels]: [18432:0,23040:100,27648:200,32256:250,36864:900,46080:950]
6.2 如何修改?
•可以通过修改修改minfree表
(frameworks/base/core/res/res/values/config.xml)
config_lowMemoryKillerMinFreeKbytesAbsolute
config_lowMemoryKillerMinFreeKbytesAdjust
(frameworks/base/services/core/java/com/android/server/am/ProcessList.java)
updateOomLevels() function’s calculation formula or
default value table(mOomMinFreeLow/mOomMinFreeHigh)
6.3 oom adj
|
ADJ优先级> |
OOMADJ |
对应场景 |
|
UNKNOWN_ADJ |
1001 |
一般指将要会缓存进程,无法获取确定值 |
|
CACHED_APP_MAX_ADJ |
906 |
不可见进程的adj最大值(不可见进程可能在任何时候被杀死) |
|
CACHED_APP_MIN_ADJ |
900 |
不可见进程的adj最小值(不可见进程可能在任何时候被杀死) |
|
SERVICE_B_ADJ |
800 |
B List中的Service(较老的、使用可能性更小) |
|
PREVIOUS_APP_ADJ |
700 |
上一个App的进程(比如APP_A跳转APP_B,APP_A不可见的时候,A就是属于PREVIOUS_APP_ADJ) |
|
HOME_APP_ADJ |
600 |
Home进程 |
|
SERVICE_ADJ |
500 |
服务进程(Service process) |
|
HEAVY_WEIGHT_APP_ADJ |
400 |
后台的重量级进程,system/rootdir/init.rc文件中设置 |
|
BACKUP_APP_ADJ |
300 |
备份进程 |
|
PERCEPTIBLE_APP_ADJ |
200 |
可感知进程,比如后台音乐播放 |
|
VISIBLE_APP_ADJ |
100 |
可见进程(可见,但是没能获取焦点,比如新进程仅有一个悬浮Activity,Visible process) |
|
FOREGROUND_APP_ADJ |
0 |
前台进程(正在展示是APP,存在交互界面,Foreground process) |
|
PERSISTENT_SERVICE_ADJ |
-700 |
关联着系统或persistent进程 |
|
PERSISTENT_PROC_ADJ |
-800 |
系统persistent进程,比如telephony |
|
SYSTEM_ADJ |
-900 |
系统进程 |
|
NATIVE_ADJ |
-1000 |
native进程(不被系统管理) |
7. lmkd parameters
|
|
|
|
|
|
ro.lmk.debug |
debug 开关, 除了killing log以外的debug 讯息需要打开这个才能看的到 |
false |
|
|
ro.lmk.kill_heaviest_task |
默认false – 每次需要杀进程时,则从高oom_adj开始遍历,同oom_adj时从最后加入列表的开始杀,直到释放出足够内存为止; true – 每次需要杀进程时,则从高oom_adj开始遍历,同oom_adj时从rss最高的进程开始杀(参考节点/proc/<$pid>/statm中的第二个数值),直到释放出足够内存为止; |
false |
|
|
ro.config.low_ram |
一般ago device定义为low ram device , 目前是1GB ram 以下的device , 有两个特点 1.依据不同oomadj 限制内存 , 2.一次只会kill 一个process |
false |
|
|
ro.lmk.kill_timeout_ms |
kill process 后下次kill 中间间隔的 timeout 时间 |
0 |
|
|
ro.lmk.use_minfree_levels |
采用kernel lowmemory killer 的 cache /minfree 参考机制来kill process , 而非参考memory pressure |
false |
|
|
|
mp_event_common 使用的prop,和PSI 参数不同时生效 |
|
|
|
ro.lmk.low |
memory pressure 为low 时kill 的最低 adj |
1001 |
|
|
ro.lmk.medium |
memory pressure 为medium时kill 的最低 adj |
800 |
|
|
ro.lmk.critical |
memory pressure 为high时kill 的最低 adj |
0 |
|
|
ro.lmk.critical_upgrade |
允许 memory pressure 从medium 被上升到critical , 条件是mem_pressure计算低于upgrade_pressure临界值 |
false |
|
|
ro.lmk.upgrade_pressure |
critical pressure 的参考值 , 以上为medium , 以下为critical |
100 |
|
|
ro.lmk.downgrade_pressure |
medium pressure 的参考值 , 以上为low ,以下为medium |
100 |
|
|
|
mp_event_psi使用的参数,和Pressuure参数不同时生效 |
|
|
|
ro.lmk.use_psi |
kernel 使用psi event上发lmkd |
1 |
1 |
|
ro.lmk.use_new_strategy |
1: use mp_event_psi , 0: use mp_event_common to kill process |
0 |
1 |
|
ro.lmk.swap_free_low_percentage |
判定swap low的百分比 ex : swap free < 10/100 |
20 |
10 |
|
ro.lmk.swap_util_max |
最大内存交换量:占可交换内存的百分比。(默认值实际上会停用此功能) |
100 |
100 |
|
ro.lmk.thrashing_limit |
判定 thrashing 的标准值 |
100 |
30 |
|
ro.lmk.thrashing_limit_decay |
thrashing limit衰减百分比 , 每次衰减 |
10 |
50 |
|
ro.lmk.psi_partial_stall_ms |
内存失速阈值。用于触发内存不足的通知。 Default for low-RAM devices = 200, for high-end devices = 70 (PSI_SOME) |
70 |
200 |
|
ro.lmk.psi_complete_stall_ms |
完全PSI失速阈值。用于触发关键内存通知。 Default =700 (PSI_FULL) |
700 |
700 |
|
ro.lmk.thrashing_min_score_adj |
发生thrashing 时kill 的 min score adj |
200 |
200 |
|
|
|
|
|
二、低内存的数据特征和行为特征
1、Meminfo 信息
最简单的方法是使用 Android 系统自带的 Dumpsys meminfo 工具
|
1 |
adb shell dumpsys meminfo |
如果系统处于低内存的话 , 会有如下特征:
- FreeRam 的值非常少 , Used RAM 的值非常大
- ZRAM 使用率非常高(如果开了 Zram 的话)
2、LMK && kswapd 线程活跃
低内存的时候, LKMD 会非常活跃, 在 Kernel Log 里面可以看到 LMK 杀进程的信息:
|
1 |
[kswapd0] lowmemorykiller: Killing ‘u.mzsyncservice’ (15609) (tgid 15609), adj 906, |
上面这段 Log 的意思是说, 由于 mem 低于我们设定的 900 的水位线 (261272kB),所以把 pid 为 15609 的 mzsyncservice 这个进程杀掉(这个进程的 adj 是 906 )
3、proc/meminfo
这里是 Linux Kernel 展示 meminfo 的地方 , 关于 meminfo 的解读,可以参考这篇文章:
/PROC/MEMINFO之谜
从结果来 , 当系统处于低内存的情况时候 , MemFree 和 MemAvailable 的值都很小
shell cat proc/meminfo
|
1 |
MemTotal: 5630104 kB |
4、整机卡顿 && 响应慢
低内存的时候,整机使用的时候要比非低内存的时候要卡很多,点击应用或者启动 App 都会有不顺畅或者响应慢的感觉
三、低内存对性能的具体影响
1、LMK 频繁工作抢占 cpu
LMK 工作时, 会占用 cpu 资源 , 其表现主要有下面几点
- CPU 资源 : 由于 LMK 杀掉的进程通常都是一些 Cache 或者 Service , 这些进程由于低内存被杀之后 , 通常会很快就被其主进程拉起来, 然后又被 LMK 杀掉, 从而进入了一种循环. 由于起进程是一件很消耗 cpu 的操作, 所以如果后台一直有进程被杀和重启, 那么前台的进程很容易出现卡顿
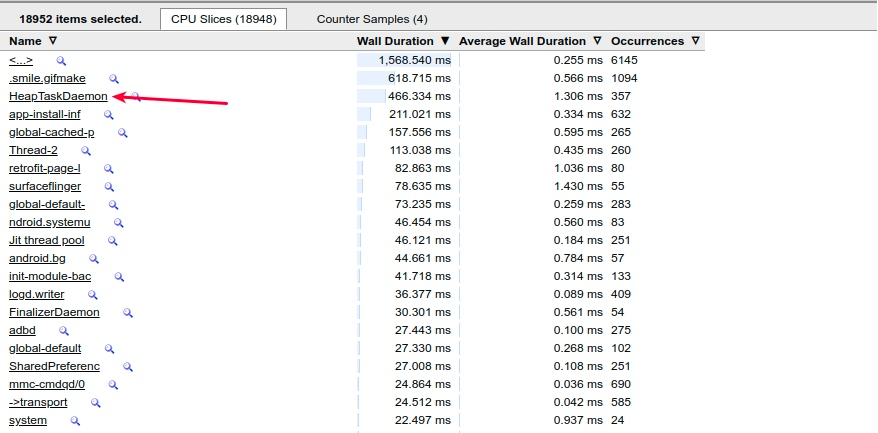
- Memory : 由于低内存的原因, 很容易触发各个进程的 GC , 如下图的 CPU 状态可以看到, 用于内存回收的 HeapTaskDeamon 出现非常频繁
- IO : 低内存会导致磁盘 IO 变多, 如果频繁进行磁盘 IO , 由于磁盘IO 很慢, 那么主线程会有很多进程处于等 IO 的状态, 也就是我们经常看到的 Uninterruptible Sleep

2、影响主线程 IO 操作
主线程出现大量的 IO 相关的问题 ,
- 反馈到 Trace 上就是有大量的黄色 Trace State 出现 , 例如 : Uninterruptible Sleep | WakeKill – Block I/O .
- 查看其 Block 信息 (kernel callsite when blocked:: “wait_on_page_bit_killable+0x78/0x88)
Linux 系统的 page cache 链表中有时会出现一些还没准备好的 page ( 即还没把磁盘中的内容完全地读出来 ) , 而正好此时用户在访问这个 page 时就会出现 wait_on_page_locked_killable 阻塞了. 只有系统当 io 操作很繁忙时, 每笔的 io 操作都需要等待排队时, 极其容易出现且阻塞的时间往往会比较长.
当出现大量的 IO 操作的时候,应用主线程的 Uninterruptible Sleep 也会变多,此时涉及到 io 操作(比如 view ,读文件,读配置文件、读 odex 文件),都会触发 Uninterruptible Sleep , 导致整个操作的时间变长
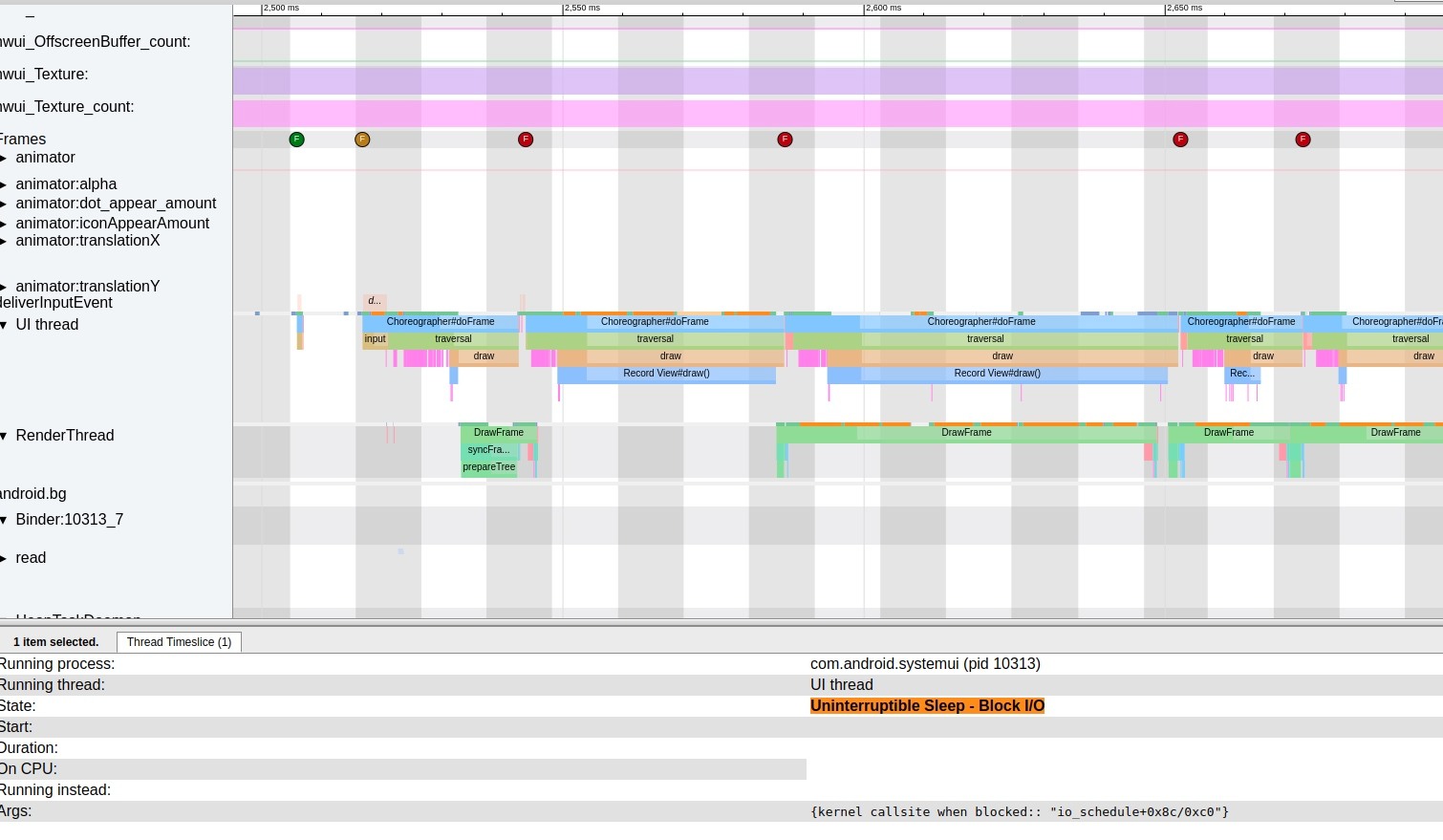

3、出现 CPU 竞争
低内存会触发 Low Memory Killer 进程频繁进行扫描和杀进程,kswapd0 是一个内核工作线程,内存不足时会被唤醒,做内存回收的工作。 当内存频繁在低水位的时候,kswapd0 会被频繁唤醒,占用 cpu ,造成卡顿和耗电。
比如下面这个情况, kswapd0 占用了 855 的超大核 cpu7 ,而且是满频在跑,耗电可想而知,如果此时前台应用的主线程跑到了 cpu7 上,很大可能会出现 cpu 竞争,导致调度不到而丢帧。
HeapTaskDaemon 通常也会在低内存的时候跑的很高

, 来做内存相关的操作
4、进程频繁查杀和重启
对 AMS 的影响主要集中在进程的查杀上面 , 由于 LMK 的介入 , 处于 Cache 状态的进程很容易被杀掉 , 然后又被他们的父进程或者其他的应用所拉起来 , 导致陷入了一种死循环 . 对系统 CPU \ Memory \ IO 等资源的影响非常大.
比如下面就是一次 Monkey 之后的结果 , QQ 在短时间内频繁被杀和重启 .
14:32:16.932 1435 1510 I am_proc_start: [0,30387,10145,com.tencent.mobileqq,restart,com.tencent.mobileqq]
|
1 |
07-23 14:32:16.969 1435 3420 I am_proc_bound: [0,30387,com.tencent.mobileqq] |
其对应的 Systrace – SystemServer 中可以看到 AM 在频繁杀 QQ 和起 QQ

此 Trace 对应的 Kernel 部分也可以看到繁忙的 cpu

5、影响内存分配和触发 IO
手机经过长时间老化使用整机卡顿一下 , 或者整体比刚刚开机的时候操作要慢 , 可能是因为触发了内存回收或者 block io , 而这两者又经常有关联 . 内存回收可能触发了 fast path 回收 \ kswapd 回收 \ direct reclaim 回收 \ LMK杀进程回收等。(fast path 回收不进行回写)
回收的内容是匿名页 swapout 或者 file-backed 页写回和清空。(假设手机都是 swap file 都是内存,不是 disk), 涉及到 file 的,都可能操作 io,增加 block io 的概率。
还有更常见的是打开之前打开过的应用,没有第一次打开的快,需要加载或者卡一段时间 . 可能发生了 do_page_fault,这条路径经常见到 block io 在 wait_on_page_bit_killable(),如果是 swapout 内存,就要 swapin 了。如果是普通文件,就要 read out in pagecache/disk.
do_page_fault —> lock_page_or_retry -> wait_on_page_bit_killable 里面会判断 page 是否置位 PG_locked, 如果置位就一直阻塞, 直到 PG_locked 被清除 , 而 PG_locked 标志位是在回写开始时和 I/O 读完成时才会被清除,而 readahead 到 pagecache 功能也对 block io 产生影响,太大了增加阻塞概率。
四、实例
下面这个 Trace 是低内存情况下 , 抓取的一个 App 的冷启动 , 我们只取应用启动到第一帧显示的部分 ,总耗时为2s 。
可以看到其 Running 的总时间是 682 ms ,
1、低内存的启动情况
低内存情况下 , 这个 App 从 bindApplication 到第一帧显示 , 共花费了 2s . 从下面的 Thread 信息那里可以看到
- Uninterruptible Sleep | WakeKill – Block I/O 和 Uninterruptible Sleep 这两栏总共花费 750 ms 左右(对比下面正常情况才 130 ms)
- Running 的时间在 600 ms (对比下面正常情况才 624 ms , 相差不大)
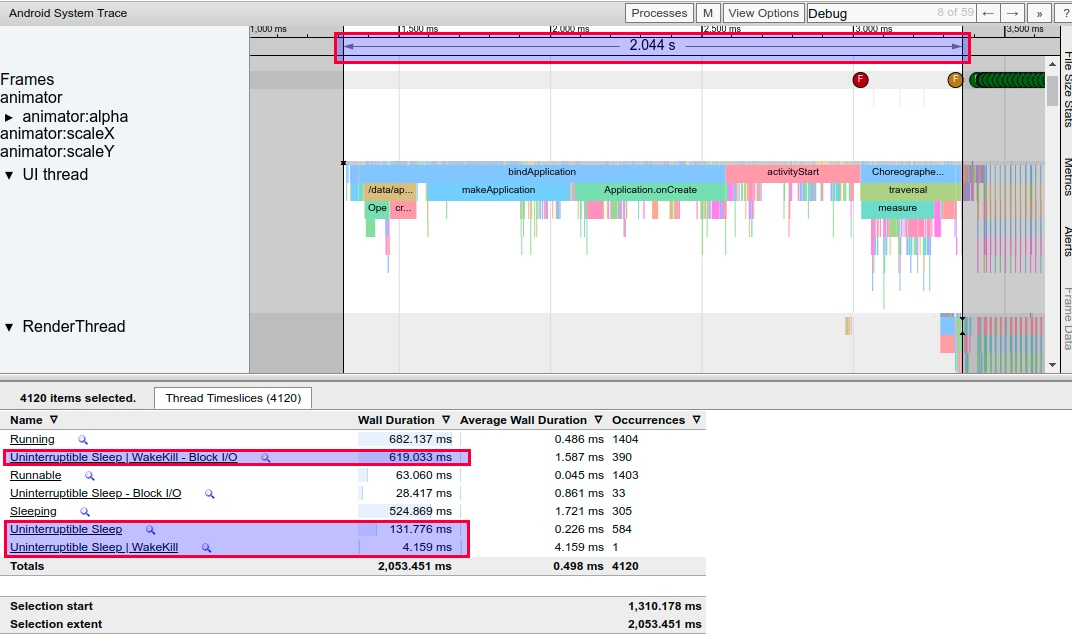
从这段时间内的 CPU 使用情况来看 , 除了 HeapTaskDaemon 跑的比较多之外 , 其他的内存和 io 相关的进程也非常多 , 比如若干个 kworker 和 kswapd0.

2、正常内存情况下
正常内存情况下 , 这个 App 从 bindApplication 到第一帧显示 , 只需要 1.22s . 从下面的 Thread 信息那里可以看到
- Uninterruptible Sleep | WakeKill – Block I/O 和 Uninterruptible Sleep 这两栏总共才 130 ms.
-
Running 的时间是 624 ms
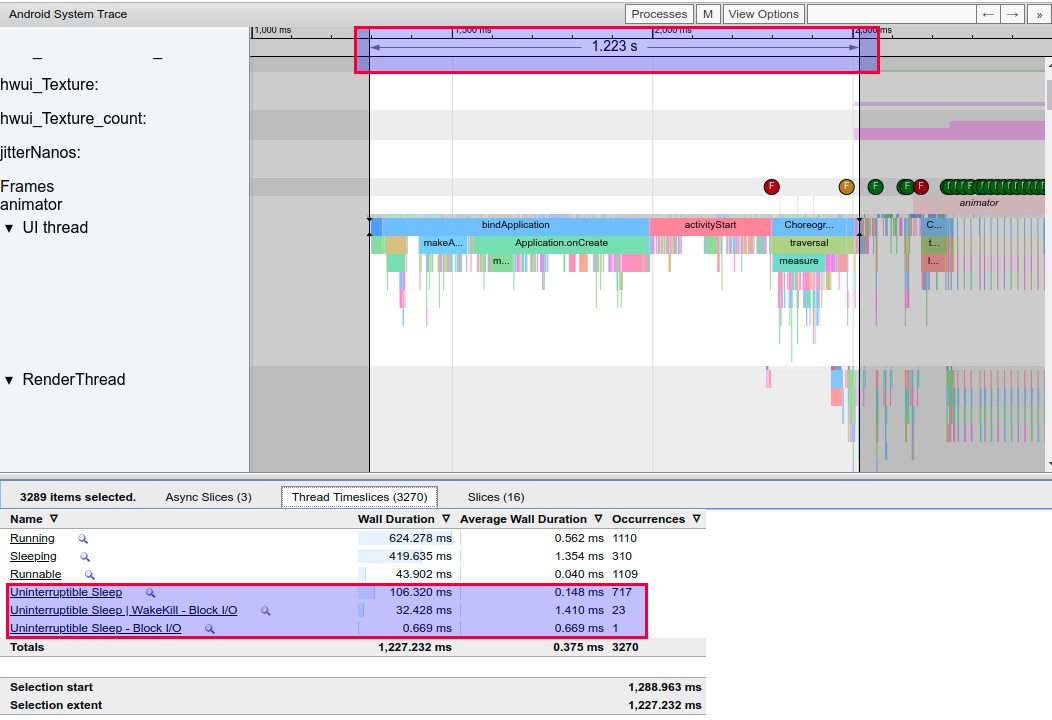
从这段时间内的 CPU 使用情况来看 , 除了 HeapTaskDeamon 跑的比较多之外 , 其他的内存和 io 相关的进程非常少.
五、Low memory处理建议
1. 优化系统进程内存占用
参考
Quick Start > Advanced System Debug & Tuning Method > Memory > memory usage分析
排查内存占比高进程并优化
2. 减少reserved memory
2-1 获取reserved memory 讯息:
<=Android P , 参考
FAQ21499reserve_memory 用量
>=Android Q, 请提e-service 申请 “memory-layout-parser” 工具
也可从lk log 搜mblock_reserve-R (但可能有缺漏)
Line 1920: [1604] mblock_reserve-R[3].start: 0x46000000, sz: 0x400000 map:0 name:lk_addr_mb
Line 1921: [1605] mblock_reserve-R[4].start: 0x46900000, sz: 0x8000000 map:0 name:scratch_addr_mb
Line 1922: [1606] mblock_reserve-R[5].start: 0x44000000, sz: 0x80000 map:1 name:dtb_kernel_addr_mb
Line 1923: [1607] mblock_reserve-R[6].start: 0x40008000, sz: 0x3200000 map:0 name:kernel_addr_mb
Line 1924: [1608] mblock_reserve-R[7].start: 0x45000000, sz: 0x1000000 map:0 name:ramdisk_addr_mb
Line 1925: [1609] mblock_reserve-R[8].start: 0x77370000, sz: 0xc90000 map:0 name:framebuffer
Line 1926: [1610] mblock_reserve-R[9].start: 0x7fa00000, sz: 0x400000 map:0 name:logo_db_addr_pa
Line 1927: [1611] mblock_reserve-R[10].start: 0x77360000, sz: 0x10000 map:0 name:SPM-reserved
Line 1928: [1612] mblock_reserve-R[11].start: 0x77350000, sz: 0x10000 map:0 name:MCUPM-reserved
Line 1929: [1613] mblock_reserve-R[12].start: 0x72000000, sz: 0x4000000 map:0 name:ccci
或是lk 代码搜
mblock_reserve 或 mblock_reserve_ext
ex:
|
|
或.dts 搜 reserved-memory
ex:
318 reserve-memory-scp_share {
319 compatible = "mediatek,reserve-memory-scp_share";
320 no-map;
321 size = <0 0x01400000>; /*20 MB share mem size */
322 alignment = <0 0x1000000>;
323 alloc-ranges = <0 0x40000000 0 0x50000000>; /*0x4000_0000~0x8FFF_FFFF*/
324 };
325 consys-reserve-memory {
326 compatible = "mediatek,consys-reserve-memory";
327 no-map;
328 size = <0 0x200000>;
329 alignment = <0 0x200000>;
330 alloc-ranges = <0 0x40000000 0 0x80000000>;
3. 限制后台
3-1修改DEFAULT_MAX_CACHED_PROCESSES
/frameworks/base/services/core/java/com/android/server/am/ActivityManagerConstants.java or ProcessList.java
public int MAX_CACHED_PROCESSES = DEFAULT_MAX_CACHED_PROCESSES;
private static final int DEFAULT_MAX_CACHED_PROCESSES = 32;
// 改为DEFAULT_MAX_CACHED_PROCESSES = 8 or 16 or …
3-2修改mCachedRestoreLevel
/frameworks/base/services/core/java/com/android/server/am/ProcessList.java中
long getCachedRestoreThresholdKb() {
return mCachedRestoreLevel;
//将mCachedRestoreLevel 改为 mCachedRestoreLevel/2
}
4. 调整lmk参数
4-1. 调整minfree table
<=kernel-4.9 non-ago project or kernel-4.14 (ro.lmk.use_minfree_levels=1)
minfree table后三项阀值 ,分别增大1.x倍 1.x倍,1.x倍 (ex: 1.2 , 1.5 ,…倍)
minfree table 参考
Quick Start > Advanced System Debug & Tuning Method > Memory > lmkd & lmk
4-2. 调整lmkd 参数
Ago project , or kernel-4.14 (ro.lmk.use_minfree_levels=0)
ro.lmk.medium 调小(mediaum pressure kill adj 减小, 更多进程可杀)
ro.lmk.downgrade_pressure 调大(更容易进到mediaum pressure状态)
ro.lmk.upgrade_pressure 调大(更容易进到critical pressure状态)
5. swap szie & swappiness
5-1.调大swap size, 使系统逻辑内存延伸加大
/device/mediatek/mt6xxx/
/device/mediatek/vendor/common/
fstab.enableswap
fstab.enableswap_gmo
fstab.enableswap_ago
/dev/block/zram0 none swap defaults zramsize=xx% 把值或百分比调大
可从/proc/zraminfo确认是否生效
5-2.调大swappiness, 使系统充分利用swap 分区
/proc/sys/vm/swappiness
/dev/memcg/memory.swappiness
/dev/memcg/apps/memory.swappiness
/dev/memcg/system/memory.swappiness
6. Duraspeed enable (or 做好后台管理)
duraspeed 可主动管理后台进程与内存, 避免进入内存恶劣情况
7. 其他优化方案
- 提高 extra_free_kbytes 值
- 提高 disk I/O 读写速率,如用 UFS3.0,用固态硬盘
- 避免设置太大的 read_ahead_kb 值
- 使用 cgroup 的 blkio 来限制后台进程的 io 读操作,缩短前台 io 响应时间
- 提前做内存回收的操作,避免在用户使用应用时碰到而感受到稍微卡顿
- 增加 LMK 效率,避免无效的 kill
- kswapd 周期性回收更多的 high 水位
- 调整 swappiness 来平衡 pagecache 和 swap
- 策略 : 针对低内存机器做特殊的策略 , 比如杀进程更加激进 (这会带来用户体验的降低 , 所以这个度需要兼顾性能和用户体验)
- 策略 : 在内存不足的时候提醒用户(或者不提醒用户) , 杀掉不必要的后台进程 .
- 策略 : 在内存严重不足且无法恢复的情况下 , 可以提示用户重启手机.
八.Slab内存占用以致Kill应用程序问题分析
一般的,都是有应用程序向系统申请内存,但是系统发现剩余的内存大小无法满足当前的申请,进行一系列的操作之后还是无法满足,将会选择最合适的程序将其kill,这样系统将可以回收它的内存,从而满足系统中其他进程的内存需求。所以,程序被kill掉,并不一定说该程序有内存泄露,只是说当系统内存被kill时,它最适合被kill。
在程序被kill之前,可以查看进程占用的内存信息,看看进程是否存在内存泄露:
其中部分信息如下: VmPeak: 3068 kB VmSize: 3068 kB VmLck: 0 kB VmPin: 0 kB VmHWM: 612 kB VmRSS: 612 kB
我们主要查看VmRSS的大小是否逐渐在增大,如果该值逐渐增大,很大可能是程序存在内存泄露。但是在test测试中,程序的该值并没有很明显的变化,所以转向系统内存信息。
每隔一段时间,查看系统内存的信息,操作如下:
root@Linux: /# cat /proc/meminfo MemTotal: 493184 kB MemFree: 442572 kB MemAvailable: 452300 kB Buffers: 3424 kB Cached: 3224 kB SwapCached: 0 kB Active: 8940 kB Inactive: 284 kB Active(anon): 2588 kB Inactive(anon): 120 kB Active(file): 6352 kB Inactive(file): 164 kB Unevictable: 0 kB Mlocked: 0 kB HighTotal: 0 kB HighFree: 0 kB LowTotal: 493184 kB LowFree: 442572 kB SwapTotal: 0 kB SwapFree: 0 kB Dirty: 20 kB Writeback: 0 kB AnonPages: 2616 kB Mapped: 2204 kB Shmem: 124 kB Slab: 30528 kB SReclaimable: 13904 kB SUnreclaim: 16624 kB KernelStack: 704 kB PageTables: 296 kB NFS_Unstable: 0 kB Bounce: 0 kB WritebackTmp: 0 kB CommitLimit: 246592 kB Committed_AS: 55424 kB VmallocTotal: 507904 kB VmallocUsed: 0 kB VmallocChunk: 0 kB CmaTotal: 65536 kB CmaFree: 59280 kB
通过cat /proc/meminfo查看系统的内存信息,其中,Slab是slab占用的内存大小,SReclaimable是可回收的,而SUnreclaim是不可回收的。发现Slab占用了系统快30M的内存,留意这个信息。接着,再查看一下,slab的详细使用情况:
root@Linux: /# cat /proc/slabinfo
slabinfo - version: 2.1
# name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail>
ext4_groupinfo_4k 58 81 296 27 2 : tunables 0 0 0 : slabdata 3 3 0
ext4_groupinfo_1k 1 28 288 28 2 : tunables 0 0 0 : slabdata 1 1 0
jbd2_1k 0 0 3072 10 8 : tunables 0 0 0 : slabdata 0 0 0
bridge_fdb_cache 0 0 320 25 2 : tunables 0 0 0 : slabdata 0 0 0
sd_ext_cdb 2 18 216 18 1 : tunables 0 0 0 : slabdata 1 1 0
sgpool-128 2 14 2304 14 8 : tunables 0 0 0 : slabdata 1 1 0
sgpool-64 2 25 1280 25 8 : tunables 0 0 0 : slabdata 1 1 0
sgpool-32 2 21 768 21 4 : tunables 0 0 0 : slabdata 1 1 0
sgpool-16 2 16 512 16 2 : tunables 0 0 0 : slabdata 1 1 0
sgpool-8 2 21 384 21 2 : tunables 0 0 0 : slabdata 1 1 0
cfq_io_cq 10 31 264 31 2 : tunables 0 0 0 : slabdata 1 1 0
cfq_queue 9 22 360 22 2 : tunables 0 0 0 : slabdata 1 1 0
fat_inode_cache 3 26 616 26 4 : tunables 0 0 0 : slabdata 1 1 0
fat_cache 0 0 200 20 1 : tunables 0 0 0 : slabdata 0 0 0
squashfs_inode_cache 88 200 640 25 4 : tunables 0 0 0 : slabdata 8 8 0
jbd2_transaction_s 0 42 384 21 2 : tunables 0 0 0 : slabdata 2 2 0
jbd2_inode 1 76 208 19 1 : tunables 0 0 0 : slabdata 4 4 0
......
kmalloc-128 1589 1596 384 21 2 : tunables 0 0 0 : slabdata 76 76 0
kmalloc-64 15937 16200 320 25 2 : tunables 0 0 0 : slabdata 648 648 0
kmem_cache_node 107 125 320 25 2 : tunables 0 0 0 : slabdata 5 5 0
kmem_cache 107 126 384 21 2 : tunables 0 0 0 : slabdata 6 6 0
从这里可以了解到slab的使用情况,记录下来。
slab是Linux操作系统的一种内存分配机制。其工作是针对一些经常分配并释放的对象,如进程描述符等,这些对象的大小一般比较小,如果直接采用伙伴系统来进行分配和释放,不仅会造成大量的内碎片,而且处理速度也太慢。而slab分配器是基于对象进行管理的,相同类型的对象归为一类(如进程描述符就是一类),每当要申请这样一个对象,slab分配器就从一个slab列表中分配一个这样大小的单元出去,而当要释放时,将其重新保存在该列表中,而不是直接返回给伙伴系统,从而避免这些内碎片。slab分配器并不丢弃已分配的对象,而是释放并把它们保存在内存中。当以后又要请求新的对象时,就可以从内存直接获取而不用重复初始化。
接着将可以隔较长一段时间,重复的进行cat /proc/meminfo和cat /proc/slabinfo操作,对比几次的信息,检查问题。
最后发现,经过较长一段时间的测试之后,Slab占用的内存数量大大增加,如果是slab占用较大的内存,则是内核频繁分配结构体导致,导致系统可用内存减小。直到出现Out of memory导致kill程序。
1.解决
了解到是Slab导致的占用内存过高的问题之后,可以手动的刷Slab,操作如下:
echo 3 > /proc/sys/vm/drop_caches /* 回刷缓冲 */
其中drop_caches的4个值有如下含义:
- 0:不做任何处理,由系统自己管理
- 1:清空pagecache
- 2:清空dentries和inodes
- 3:清空pagecache、dentries和inodes
但是这样的办法不是最佳的,最好还是应该通过slabinfo信息,了解到应用程序进行什么操作,导致内核频繁申请结构体导致Slab占用大量内存,看能否避免这样的问题,同时,内核有自动回收机制,可修改触发自动回收的阀值,当slab空闲内存达到一定量的时候,进行有效的回收。
2.后续
后来在参考文章看到信息,概括如下:
文中开头的说到的老化测试程序test,就是大量的保存文件,频繁的文件io操作(open、write、close),导致了dentry_cache占用了系统太多的内存资源。
inode对应于物理磁盘上的具体对象,而dentry是一个内存实体,其中的d_inode成员指向对应的inode,故可以把dentry看成是Linux文件系统中某个索引节点(inode)的链接,这个索引节点可以是文件,也可以是目录。而dentry_cache是目录项高速缓存,是Linux为了提高目录项对象的处理效率而设计的,它记录了目录项到inode的映射关系。
3.系统的自动slab缓存回收
在slab缓存中,对象分为SReclaimable(可回收)和SUnreclaim(不可回收),而在系统中绝大多数对象都是可回收的。内核有一个参数,当系统内存使用到一定量的时候,会自动触动回收操作。
-
内核参数:
vm.min_free_kbytes = 836787
代表系统所保留空闲内存的最低限。
在系统初始化时会根据内存大小计算一个默认值,计算规则是:
min_free_kbytes = sqrt(lowmem_kbytes * 16) = 4 * sqrt(lowmem_kbytes)(注:lowmem_kbytes即可认为是系统内存大小)
另外,计算出来的值有最小最大限制,最小为128K,最大为64M。
可以看出,min_free_kbytes随着系统内存的增大不是线性增长,因为随着内存的增大,没有必要也线性的预留出过多的内存,能保证紧急时刻的使用量便足矣。 - min_free_kbytes的主要用途是计算影响内存回收的三个参数 watermark[min/low/high]
- watermark[high] > watermark [low] > watermark[min],各个zone各一套
- 在系统空闲内存低于 watermark[low]时,开始启动内核线程kswapd进行内存回收(每个zone一个),直到该zone的空闲内存数量达到watermark[high]后停止回收。如果上层申请内存的速度太快,导致空闲内存降至watermark[min]后,内核就会进行direct reclaim(直接回收),即直接在应用程序的进程上下文中进行回收,再用回收上来的空闲页满足内存申请,因此实际会阻塞应用程序,带来一定的响应延迟,而且可能会触发系统OOM。这是因为watermark[min]以下的内存属于系统的自留内存,用以满足特殊使用,所以不会给用户态的普通申请来用。
-
三个watermark的计算方法:
watermark[min] = min_free_kbytes换算为page单位即可,假设为min_free_pages。(因为是每个zone各有一套watermark参数,实际计算效果是根据各个zone大小所占内存总大小的比例,而算出来的per zone min_free_pages)
watermark[low] = watermark[min] * 5 / 4
watermark[high] = watermark[min] * 3 / 2
所以中间的buffer量为 high – low = low – min = per_zone_min_free_pages * 1/4。因为min_free_kbytes = 4* sqrt(lowmem_kbytes),也可以看出中间的buffer量也是跟内存的增长速度成开方关系。 - 可以通过/proc/zoneinfo查看每个zone的watermark
-
min_free_kbytes大小的影响
min_free_kbytes设的越大,watermark的线越高,同时三个线之间的buffer量也相应会增加。这意味着会较早的启动kswapd进行回收,且会回收上来较多的内存(直至watermark[high]才会停止),这会使得系统预留过多的空闲内存,从而在一定程度上降低了应用程序可使用的内存量。极端情况下设置min_free_kbytes接近内存大小时,留给应用程序的内存就会太少而可能会频繁地导致OOM的发生。
min_free_kbytes设的过小,则会导致系统预留内存过小。kswapd回收的过程中也会有少量的内存分配行为(会设上PF_MEMALLOC)标志,这个标志会允许kswapd使用预留内存;另外一种情况是被OOM选中杀死的进程在退出过程中,如果需要申请内存也可以使用预留部分。这两种情况下让他们使用预留内存可以避免系统进入deadlock状态。
可测试,当调整完min_free_kbytes值大于系统空闲内存后,kswapd进程的确从休眠状态进入运行态,开始回收内存。
同时,还有一个参数vm.vfs_cache_pressure = 200
该文件表示内核回收用于directory和inode cache内存的倾向;缺省值100表示内核将根据pagecache和swapcache,把directory和inode cache保持在一个合理的百分比;降低该值低于100,将导致内核倾向于保留directory和inode cache;增加该值超过100,将导致内核倾向于回收directory和inode cache。