本系列分为三篇,此文为本系列第二篇,其他文章:
YOLO系列(一)—— You Only Look Once:Unified, Real-Time Object Detection
YOLO系列(三)—— YOLOv3: An Incremental Improvement
project: https://pjreddie.com/darknet/yolo/
paper: YOLO9000:Better, Faster, Stronger
yolo v2在yolo的基础上做了一些改进,对yolo不熟悉的可以参考:YOLO系列(一)
在paper中,并没有给出网络结构的完整示意图,下图是在网上找的,原网址查看更加清晰:https://ethereon.github.io/netscope/#/gist/d08a41711e48cf111e330827b1279c31

相对yolo做出的修改:
1)去掉全连接层,采用全卷积结构,可以输入不同的尺寸结构(32的倍数即可,下采样率为32)
2)在每个卷积层中加入Batch Normalization,去掉dropout
3)开始训练时就采用448×448的高分辨率进行训练
4)使用了Anchor Boxes,每个grid预测5个boxes,一共可以预测13×13×5=845个boxes,且每个box都有对应的class,远多于yolo的98个boxes,以及每个grid一个class
5)Anchor Boxes由聚类生成,评价标准为IOU
6)使用多尺度特征,将两层前的feature reorganization后和当前层进行concate
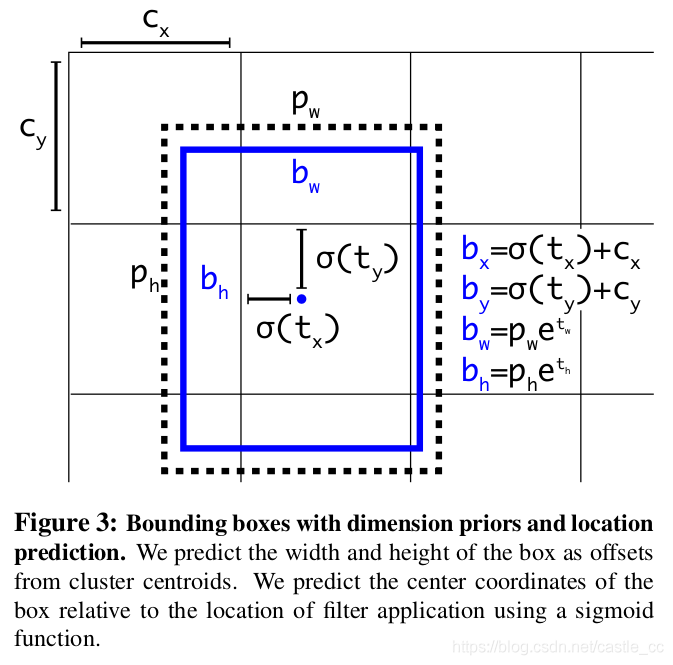
7) box的预测在之前的基于Anchor的方式上做了一定修改,如下图所示
版权声明:本文为castle_cc原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。