高并发系统有哪些分类和例子
侧重于「高并发读」的系统
- 1.搜索引擎
- 2.电商的商品搜索
- 3.电商系统的商品描述、图片和价格
侧重于「高并发写」的系统
- 广告计费系统:C 端用户的每一次浏览或点击都会对广告主的账号余额进行一次扣减
同时侧重于「高并发读」和「高并发写」的系统
- 1.电商的库存系统和秒杀系统
- 2.支付系统和微信红包
- 3.IM、微博和朋友圈
高并发读的应对策略
策略 1:加缓存
- 案例 1:本地缓存或 Memcached/Redis 集中式缓存
- 案例 2:MySQL 的 Master/Slave
- 案例 3:CDN 静态文件加速(动静分离)
策略 2:并发读
- 案例 1:异步 RPC
- 没有耦合关系的 3 个调用可以并行去调
- 案例 2:Google 的「冗余请求」
- 客户端首先给服务端发送一个请求,并等待服务端返回的响应
- 如果客户端在一定的时间内(定义为 95%请求的响应时间)没有收到响应,则马上给一台(或多台)服务器发送同样的请求
- 客户端等待第一个响应到达之后,终止其他请求的处理
策略 3:重写轻读
- 案例 1:微博 Feeds 流
- 场景
- 微博首页或微信朋友圈都存在类似的查询场景:用户关注了n个人(或者有n个好友),每个人都在不断地发微博,然后系统需要把这n个人的微博按时间排序成一个列表,也就是Feeds流并展示给用户
- 用户也需要查看自已发布的微博列表
- 原始方案(假设数据存在数据库中)
- 表结构
- 关注关系表(Following 表)
- ID(自增主键)
- user_id(关注者)
- followings(被关注的人)
- 微博发布表(Msg表)
- ID(自增主键)
- user_id(发布者)
- msg_id(发布的微博 ID)
- 关注关系表(Following 表)
- 查询 user_id = 1 发布的微博列表并分页
SELECT msg_ids from Msg where user_id = 1 limit offset, count
- 查询 user_id = 1 用户的 Feeds 流,并按时间排序并分页,需要两条 SQL 语句
- 先查询 user_id = 1 的用户的关注的用户列表:
SELECT followings from Following where user_id=1- 查询关注的所有用户的微博列表,按时间排序并分页I
SELECT msg_ids from Msg where user_id in (followings) limit offset, count
- 表结构
- 重写轻读
- 方案
- 提前为每个 user_id 准备一个 Feeds 流,或叫收件箱
- 每个用户都有一个发件箱和收件箱。用户发布 1 条微博后,只写入自己的发件箱就返回成功。然后后台异步地把这条微博推送到粉丝的收件箱,即「写扩散」
- 这样,每个用户读取 Feeds 流的时候不需实时聚合,直接读取各自的收件箱即可
- 若是收件箱数量超过一定的阈值,丢弃即可
- 用户发布的微博如何全量保存数据
- 仍然按 Msg 表存储,按 user_id 和时间范围进行数据库的分片
- 分页后,如何快速查看某个 user_id 从某个 offet 开始的微博,如显示要第 50 页,每页有 100 个,即 offset = 5000 的位置开始之后的微博。如何快速定位到 5000 所属的库?
- 借助二级索引:另外有一张表,记录<user_id,月份,count>。也就是每个 user_id 在每个月份发表的微博总数。基于这个索引表即可快速定位到 offset = 5000 的微博发生在那个月份
- 用户粉丝多的优化:在读的时候实时聚合
- 在写的一端,对于粉丝数量少的用户(假设定个阈值为5000,小于5000的用户),发布一条微博之后推送给5000个粉丝
- 对于粉丝数多的用户,只推送给在线的粉丝们(系统要维护一个全局的、在线的用户列表)
- 对于读的一端,一个用户的关注的人当中,有的人是推给他的(粉丝数少于5000), 有的人是需要他去拉的(粉丝数大于5000),需要把两者聚合起来,再按时间排序,然后分页显示,这就是“推拉结合”
- 方案
- 场景
- 案例 2:多表的关联查询:宽表和搜索引擎
- 提前把关联数据计算好,存在一个地方,读的时候直接去读聚合好的数据,而不是读取的时候再去做 join
- 宽表实现:把要关联的表的数据算好后保存在宽表里。依据实际情况,可以定时算,也可能任何一张原始表发生变化之后就触发-次宽表数据的计算
- ES 类的搜索引擎实现:把多张表的Join 结果做成一个个的文档,放在搜索引擎里面,也可以灵活地实现排序和分页查询功能
高并发写的应对策略
策略 1:数据分片
- 案例 1:数据库的分库分表
- 案例 2:JDK 的 ConcurrentHashMap 实现
- ConcurrentHashMap在内部分成了若干槽( 个数是2的整数次方,默认是16 个槽),也就是若干子HashMap。这些槽可以并发地读写,槽与槽之间是独立的,不会发生数据互斥
- 案例 3:Kafka 的 partition
- 在Kafka中,一个topic表示-一个逻辑上的消息队列,具体到物理上,一个topic 被分成了多个partition,每个parition对应磁盘中的一个日志文件。partition 之间也是相互独立的,可以并发地读写,也就提高了一个topic 的并发量
- 案例 4:ES 的分布式索引
- 在搜索引擎里有一个基本策略是分布式索引。比如有10亿个网页或商品,如果建在一个倒排索引里面,则索引很大,也不能并发地查询
- 可以把这 10 亿个网页或商品分成n份,建成n个小的索引。一个查询请求来了以后,并行地在n个索引上查询,再把查询结果进行合并
策略 2:任务分片
- 案例 1:CPU 的指令流水线
- 案例 2:Map/Reduce
- 案例 3:Tomcat 的 1+N+M 网络模型
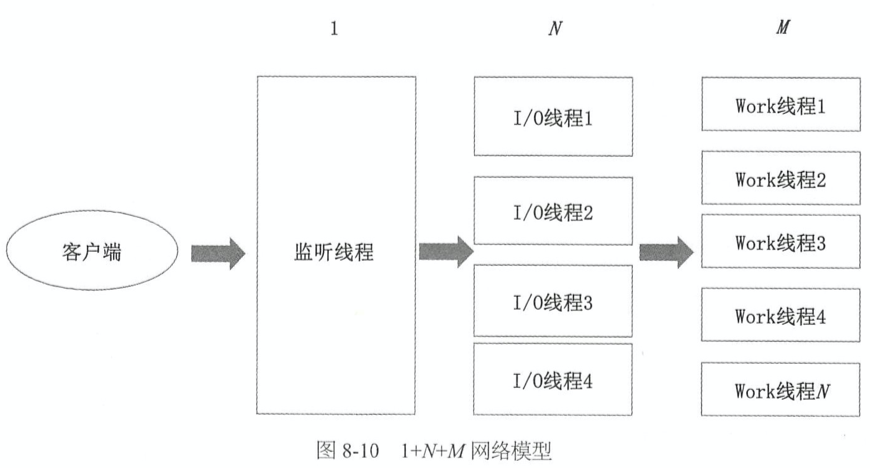
- 把一个请求的处理分成了三个工序:监听、I/O、业务逻辑处理。1 个监听线程负责监听客户端的 Socket 连接;N 个 I/O 线程负责对 Socket 进行读写,N 通常约等于 CPU 核数;M 个 Work 线程负责对请求进行逻辑处理
- 进一步来讲,Work 线程还可能被拆分成解码、业务逻辑计算、编码等环节,进一步提高并发度
策略 3:异步化
- 解释
- 站在客户端的角度来讲,是请求服务器做一个事情,客户端不等结果返回,就去做其他的事情,回头再去轮询,或者让服务器回调通知
- 站在服务器角度来看,是接收到一个客户的请求之后不立即处理,也不立马返回结果,而是在“后台慢慢地处理”,稍后返回结果。因为客户端不等上一个请求返回结果就可以发送一个请求,可以源源不断地发送请求,从而就形成了异步化
- 案例 1:短信验证码注册或登录
- 通常在注册或登录App或小程序时,采用的方式为短信验证码。短信的发送通常需要依赖第三方的短信发送平台。客户端请求发送验证码,应用服务器收到请求后调用第三方的短信平台
- 公网的HTTP调用可能需要1~2s,如果是同步调用,则应用服务器会被阻塞。假设应用服务器是Tomcat,一台机器最多可以同时处理几百个请求,如果同时来几百个请求,Tomcat就会被卡死了。
- 改成异步调用就可以避免这个问题。应用服务器收到客户端的请求后,放入消息队列,并立即返回。然后有一个后台任务,从消息队列读取消息,去调用第三方短信平台发送验证码
- 案例 2:电商的订单系统
- 买多个商品,但只下了一个订单付一次款,因为后台会进行「拆单」等环节
- 案例 3:广告计费系统
- 用户的点击请求或浏览请求首先会以日志的形式进行落盘。落盘之后,立即给客户端返回数据。后续的所有处理,当然也包括扣费,全部是异步化的
- 案例 4:LSM 树(写内存+Write-Ahead 日志)
- LSM(Log Structured Merged Tree)的核心思想是「异步写」。LSM 树支撑的是 KV 存储,磁盘上实现了 Sorted HashMap,但插入时是无序的
- 原理:LSM 在内存中维护一个 Sorted HashMap,并写一条日志(即 Write-Ahead 日志),该日志的关键点是顺序写入,只会在日志尾部追加,而不会随机地写入,再有一个后台任务定期地把内存中的 SortedHashMap 合并到磁盘文件中,后台任务会执行磁盘数据的合并排序
- 拓展:上层业务高并发扣减 MySQL 中的账户余额,可以在 Redis 中扣,同时落一条日志(日志可以在一个高可靠的消息中间件或数据库中插入一条条日志,数据库可以分库分表)。当 Redis 宕机,把所有的日志重放完毕,再用数据库中的数据初始化 Redis 中的数据。当然,数据库中的数据不能比Redis落后太多,否则积压大量日志未处理,宕机恢复的时间会很长
- 案例 5:Kafka 的 Pipeline
- kafka 为了高可用性,会为每个 Topic 的每个 Partition 准备多个副本,其中一个被选举为 Leader,另外都是 Follower
- 对于同步发送,客户端每发送一条消息,Leader 要把这条消息同步到所有 Follower 后,才会对客户端返回成功
- 在实现上,Leader 并不会主动给两个 Follower 同步数据,而是等 Follower 主动拉取,并且是批量拉取。当 Leader 收到客户端的消息 msg1 并把它存到本地文件后,就去做别的事情了,如接收下一个消息 msg2,此时客户端仍处于阻塞状态,等待 msg1 返回。只有等所有 Follower 把消息 msg1 拖过去后,Leader 才会返回客户端说 msg1 接收成功了
策略 4:批量
- 案例 1:Kafka 的百万 QPS 写入
- kafka 快的三个策略:1.Partition 分片,2.磁盘的顺序写入,3批量,把多条合并成一条,一次性写入
- kafka 的客户端在内存中为每个 Partition 准备了一个队列,称为 RecordAccumulator。Producer 线程一条条地发送消息,这些消息都进入内存队列。然后通过 Sender 线程从这些队列中批量地提取消息发送给 kafka 集群
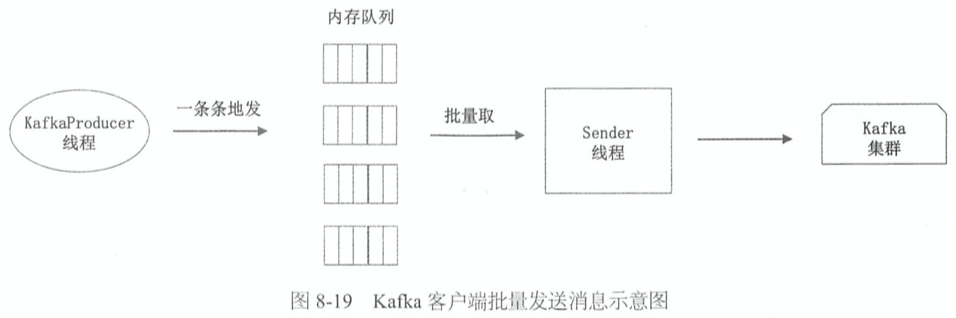
- 如果是同步发送,Producer 向队列中放入一条消息后会阻塞,等待 Sender 线程取走该条消息并发出去后,Producer 才会返回,这是没有批量操作
- 如果是异步发送,Producer把消息放入队列中后就返回了,Sender线程会把队列中的消息打包,一次发送出去多个,这时就会用到批量操作
- 对于具体的批量策略,Kafka提供了几种参数进行配置,可以按Batch的大小或等待时间来批量操作
- 案例 2:广告计费系统的合并扣费
- 例如可把同一账号扣 10 次,每次扣 1 块。改为 1 次扣 10 块
- 扣费模块一次性地从持久化消息队列中取多条消息,对这多条消息按广告主的账号 ID 进行分组,同一个组内的消息的扣费金额累加合并,然后从数据库里扣除
- 案例 3:MySQL 的小事务合并机制
- 比如扣库存,对同一个SKU,本来是扣10次、每次扣1个,也就是10个事务;在MySQL内核里面合并成1次扣10个,也就是10个事务变成了1个事务
策略 5:串行化+多进程单线程+异步 I/O
- 案例:Nginx、Redis 的单线程模型
- 有了异步 I/O 后,可把请求串行化处理。这样,没有了锁的竞争和 I/O 的阻塞,单线程也非常高效。要利用多核优势可开多个实例
注:原始发布于个人博客:https://shiqi-lu.tech/soft-arch-design-ch8/
版权声明:本文为u011703187原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。