本实验主要是重新设计锁,增加并行性
分别是为kmem和bcache设计
memory allocator
https://blog.csdn.net/RedemptionC/article/details/108127655 这里对kalloc做了一点基本的分析
他的设计是所有的cpu(NCPU为8,但是实际是3个)都使用一个freelist,这样lock contention就很高
要做的改进是为每一个cpu设置一个free list,每个freelist一个锁,这样不同的cpu就能独立的进行分配
首先修改结构体的定义,改为定义一个结构体数组:
struct kmem{
struct spinlock lock;
struct run *freelist;
};
struct kmem kmems[3];然后在kinit中初始化三个锁,仍然用freerange将全部内存分配给调用它的cpu
void
kinit()
{
printf("[kinit] cpu id %d\n",getcpu());
for(int i=0;i<3;i++)
initlock(&kmems[i].lock, "kmem");
freerange(end, (void*)PHYSTOP);
}其实这里如果将全部的内存均匀的分给每个cpu的freelist,会更好,但是不管怎样,都会面临这样一个问题:当前cpu的freelist为空,但是其他cpu的freelist不为空,此时就需要向其他cpu借内存
修改kalloc
void *
kalloc(void)
{
// printf("[kalloc] cpu id %d\n",getcpu());
// printkmem();
struct run *r;
int hart=getcpu();
acquire(&kmems[hart].lock);
r = kmems[hart].freelist;
if(r)
kmems[hart].freelist = r->next;
release(&kmems[hart].lock);
if(!r)
{
// 当前cpu对应的freelist为空 需要从其他cpu对应的freelist借
r=steal(hart);
}
if(r)
memset((char*)r, 5, PGSIZE); // fill with junk
return (void*)r;
}
void *
steal(int skip){
// printf("cpu id %d\n",getcpu());
struct run * rs=0;
for(int i=0;i<3;i++){
// 当前cpu的锁已经在外面获取了,这里为了避免死锁,需要跳过
if(holding(&kmems[i].lock)){
continue;
}
acquire(&kmems[i].lock);
if(kmems[i].freelist!=0){
rs=kmems[i].freelist;
kmems[i].freelist=rs->next;
release(&kmems[i].lock);
return (void *)rs;
}
release(&kmems[i].lock);
}
// 不管还有没有,都直接返回,不用panic
return (void *)rs;
}执行kfree的时候,只要将内存回收到当前cpu的freelist即可
这样,即可通过kalloctest:
Buffer cache
在bio.c中,可以看到,所有的buffer都被组织到了一条链表中,因此如果有多个进程要使用buffer,他们并发的请求只能被顺序的处理
指导书给出了一种优化的办法:使用哈希表,separate chaining的方式来组织buffer,使用blockno作为key
具体我在代码注释里写的很清楚了:
// Buffer cache.
//
// The buffer cache is a linked list of buf structures holding
// cached copies of disk block contents. Caching disk blocks
// in memory reduces the number of disk reads and also provides
// a synchronization point for disk blocks used by multiple processes.
//
// Interface:
// * To get a buffer for a particular disk block, call bread.
// * After changing buffer data, call bwrite to write it to disk.
// * When done with the buffer, call brelse.
// * Do not use the buffer after calling brelse.
// * Only one process at a time can use a buffer,
// so do not keep them longer than necessary.
#include "types.h"
#include "param.h"
#include "spinlock.h"
#include "sleeplock.h"
#include "riscv.h"
#include "defs.h"
#include "fs.h"
#include "buf.h"
#define NBUCKETS 13
struct {
// 每个bucket一个lock
// hashbucket.next是当前bucket的MRU
struct spinlock lock[NBUCKETS];
struct buf buf[NBUF];
struct buf hashbucket[NBUCKETS];
} bcache;
int bhash(int blockno){
return blockno%NBUCKETS;
}
void
binit(void)
{
struct buf *b;
for(int i=0;i<NBUCKETS;i++){
initlock(&bcache.lock[i], "bcache.bucket");
// 仍然将每个bucket的头节点都指向自己
b=&bcache.hashbucket[i];
b->prev = b;
b->next = b;
}
// 此时因为buffer没有和磁盘块对应起来,所以blockno全部为初始值0,将其全部放在第一个bucket中
// 至于其他bucket缺少buffer该怎么解决,在bget里阐述
for(b = bcache.buf; b < bcache.buf+NBUF; b++){
// 虽然看起来复杂了点,但仍然是插在表头
b->next = bcache.hashbucket[0].next;
b->prev = &bcache.hashbucket[0];
initsleeplock(&b->lock, "buffer");
bcache.hashbucket[0].next->prev = b;
bcache.hashbucket[0].next = b;
}
}
// Look through buffer cache for block on device dev.
// If not found, allocate a buffer.
// In either case, return locked buffer.
static struct buf*
bget(uint dev, uint blockno)
{
struct buf *b;
int h=bhash(blockno);
acquire(&bcache.lock[h]);
// 首先在blockno对应的bucket中找,refcnt可能为0,也可能不为0
for(b = bcache.hashbucket[h].next; b != &bcache.hashbucket[h]; b = b->next){
if(b->dev == dev && b->blockno == blockno){
b->refcnt++;
release(&bcache.lock[h]);
acquiresleep(&b->lock);
return b;
}
}
// 如果在h对应的bucket中没有找到,那么需要到其他bucket中找,这种情况不会少见,因为
// binit中,我们就把所有的buffer都插入到了第一个bucket中(当时blockno都是0
// 此时原来bucket的锁还没有释放,因为我们在其他bucket中找到buffer后,还要将其插入到原bucket中
int nh=(h+1)%NBUCKETS; // nh表示下一个要探索的bucket,当它重新变成h,说明所有的buffer都bussy(refcnt不为0),此时
// 如之前设计的,panic
while(nh!=h){
acquire(&bcache.lock[nh]);// 获取当前bocket的锁
for(b = bcache.hashbucket[nh].prev; b != &bcache.hashbucket[nh]; b = b->prev){
if(b->refcnt == 0) {
b->dev = dev;
b->blockno = blockno;
b->valid = 0;
b->refcnt = 1;
// 从原来bucket的链表中断开
b->next->prev=b->prev;
b->prev->next=b->next;
release(&bcache.lock[nh]);
// 插入到blockno对应的bucket中去
// 👇就是有头节点的头插法
b->next=bcache.hashbucket[h].next;
b->prev=&bcache.hashbucket[h];
bcache.hashbucket[h].next->prev=b;
bcache.hashbucket[h].next=b;
release(&bcache.lock[h]);
acquiresleep(&b->lock);
return b;
}
}
// 如果当前bucket里没有找到,在转到下一个bucket之前,记得释放当前bucket的锁
release(&bcache.lock[nh]);
nh=(nh+1)%NBUCKETS;
}
panic("bget: no buffers");
}
// Return a locked buf with the contents of the indicated block.
struct buf*
bread(uint dev, uint blockno)
{
struct buf *b;
b = bget(dev, blockno);
if(!b->valid) {
virtio_disk_rw(b->dev, b, 0);
b->valid = 1;
}
return b;
}
// Write b's contents to disk. Must be locked.
void
bwrite(struct buf *b)
{
if(!holdingsleep(&b->lock))
panic("bwrite");
virtio_disk_rw(b->dev, b, 1);
}
// Release a locked buffer.
// Move to the head of the MRU list.
void
brelse(struct buf *b)
{
if(!holdingsleep(&b->lock))
panic("brelse");
releasesleep(&b->lock);
int h=bhash(b->blockno);
acquire(&bcache.lock[h]);
b->refcnt--;
if (b->refcnt == 0) {
// no one is waiting for it.
// 下面做的就是把b从原来的位置取下来 放在链表开头(头插法)
b->next->prev = b->prev;
b->prev->next = b->next;
b->next = bcache.hashbucket[h].next;
b->prev = &bcache.hashbucket[h];
bcache.hashbucket[h].next->prev = b;
bcache.hashbucket[h].next = b;
}
release(&bcache.lock[h]);
}
void
bpin(struct buf *b) {
int h=bhash(b->blockno);
acquire(&bcache.lock[h]);
b->refcnt++;
release(&bcache.lock[h]);
}
void
bunpin(struct buf *b) {
int h=bhash(b->blockno);
acquire(&bcache.lock[h]);
b->refcnt--;
release(&bcache.lock[h]);
}
做的时候,实验指导书里的很多做法并没有看懂/采用,比如时间戳什么的
更多的参考了这个repo,里面的一些issue也值得一看:
https://github.com/skyzh/6.S081-xv6-riscv-fall19/issues/10
过关截图:
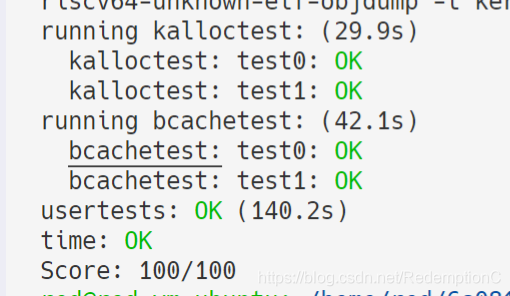
(不得不说关于锁的使用,还是需要更多体会的,并发的情况还是很复杂