斯坦福大学机器学习讲义及作业题地址点击打开链接
1. [15 points] Logistic Regression: Training stability
In this problem, we will be delving deeper into the workings of logistic regression. The goal of this problem is to help you develop your skills debugging machine learning algorithms(which can be very different from debugging software in general).Please do not modify the code for the logistic regression training algorithm for this problem.
First, run the given logistic regression code to train two different models on A and B.
数据来源dataA点击打开链接
数据来源dataB点击打开链接
代码来源点击打开链接
(a)What is the most notable difference in training the logistic regression model on datasets A and B?
运行后会发现dataA和dataB的收敛次数不一样


(b) [5 points] Investigate why the training procedure behaves unexpectedly on datasetB, but not on A. Provide hard evidence (in the form of math, code, plots, etc.) to
corroborate your hypothesis for the misbehavior. Remember, you should address whyyour explanation does not apply to A.
Hint: The issue is not a numerical rounding or over/underow error.
本题中的主要思想就是通过梯度下降法计算逻辑回归系数,不断迭代,通过计算本次迭代和上次迭代的差值的范数,判断收敛性。本题选取的收敛域为10的-15次方,可以看出A在30395步收敛,而B一直不收敛,通过printB的梯度,发现B的梯度还是在持续下降的,但是B的收敛速度过慢,所以迟迟不收敛,这也是梯度下降法本身的缺陷,梯度下降法是一阶收敛,越靠近收敛值的时候,收敛速度越来越慢,而本题中的学习系数为固定值,当然也通过一维搜索确定学习系数的值
画了个图

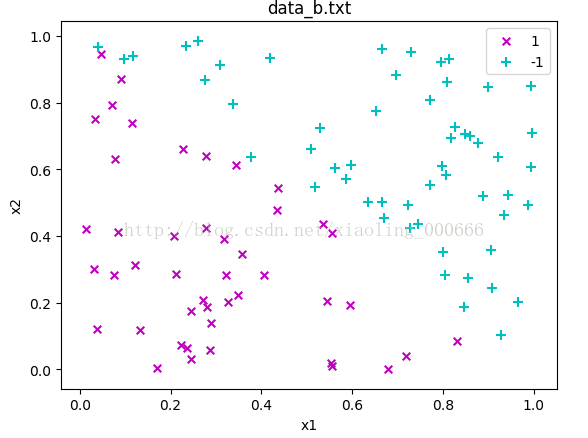 并没有看出什么太大区别
并没有看出什么太大区别
所以应该和梯度下降的梯度有关,此图为dataA的3万次迭代中本次迭代和上次迭代的差值的范数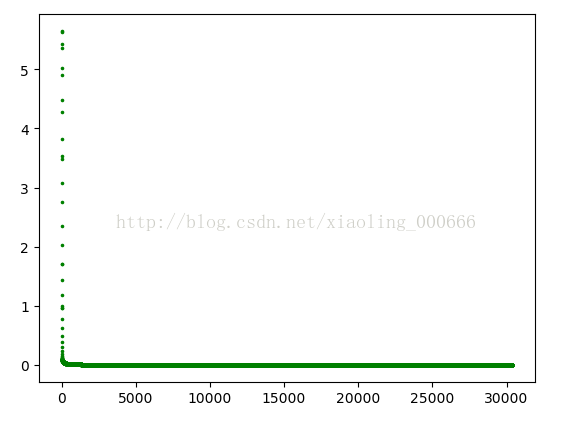
又研究了从第100次迭代开始的图片,会发现其实在迭代几千次之后收敛性已经还不错了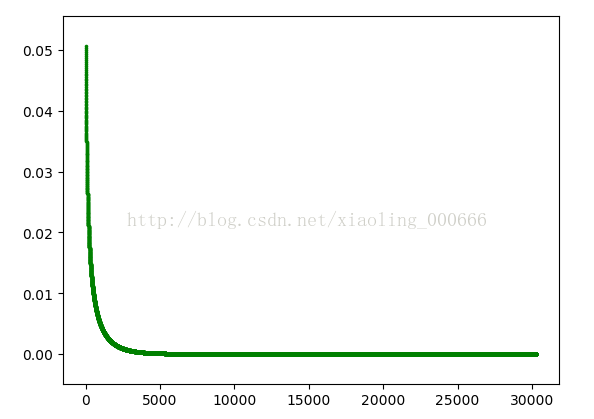
接下来看下B的收敛速度

同样研究了数据B从第100次迭代开始的图片,
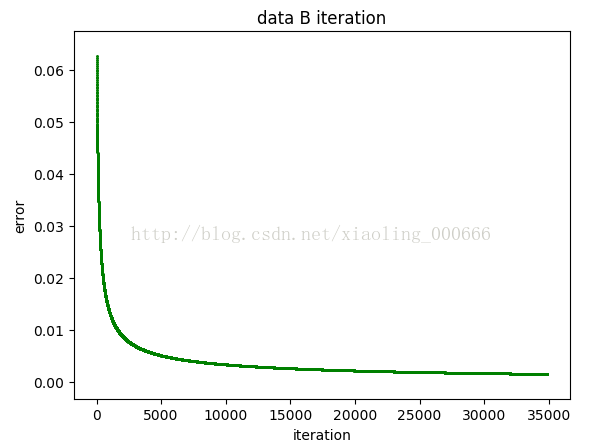
可以看出B的迭代速度比A慢,其实B也是可以收敛的,当我们调整收敛条件时,把收敛条件调大一些的时候,B也可以收敛,但是收敛速度仍然比A慢一些