相关参考手册在PaddleOCR项目工程中的位置:
det模型训练和微调:PaddleOCR\doc\doc_ch\PPOCRv3_det_train.md
模型微调PaddleOCR\doc\doc_ch\finetune.md
在手册PPOCRv3_det_train.md中,提到
finetune训练适用于三种场景
- 基于CML蒸馏方法的finetune训练,适用于教师模型在使用场景上精度高于PPOCRv3检测模型,且希望得到一个轻量检测模型。
- 基于PPOCRv3轻量检测模型的finetune训练,无需训练教师模型,希望在PPOCRv3检测模型基础上提升使用场景上的精度。
- 基于DML蒸馏方法的finetune训练,适用于采用DML方法进一步提升精度的场景。
由于第二种工程量最小,本篇中博客中,我记录的是第二种:
基于PPOCRv3轻量检测模型的finetune训练,无需训练教师模型,希望在PPOCRv3检测模型基础上提升使用场景上的精度。
的det模型finetune过程
也就是使用自己的数据集,在PPOCRv3预训练模型上做微调,提升垂类场景效果
基本流程
- 首先使用PPOCRLabel工具,打标签,构造基于自己垂类场景的数据集
-
根据自己数据集的性质和场景需求,修改训练的配置文件
configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml
参数 -
然后基于下载下来的学生模型
student.pdparams
进行训练
详细步骤
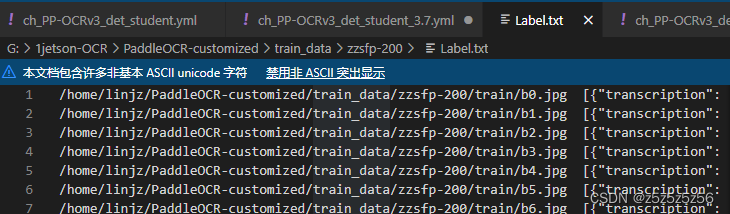
打标签,构建自己的数据集
使用PPOCRLabel,指路:
【PaddleOCR-PPOCRLabel】标注工具使用
,这篇博客详细说过了
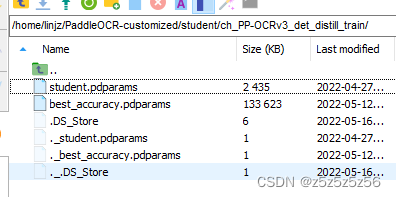
下载PPOCRv3训练模型
在PaddleOCR\doc\doc_ch\finetune.md中的教学:
提取Student参数的方法如下……但其实下载下来模型已经有提取好了的,所以就不用自己提取了
这里提取学生模型参数,在我看来就是获取准备拿来微调的det模型
参数模型就是
student.pdparams
这个文件,下载下来就有
#在项目根目录
mkdir student
cd student
wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_distill_train.tar
tar xf ch_PP-OCRv3_det_distill_train.tar
修改超参数,训练自己数据集
对于其中
configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml
的参数,需要安装训练的实际数据集中训练集和验证集的位置,在yml文件中修改对应txt路径,具体参数说明,见表和下方注释
| 参数名称 | 类型 | 默认值 | 含义 |
|---|---|---|---|
| det_db_thresh | float | 0.3 | DB输出的概率图中,得分大于该阈值的像素点才会被认为是文字像素点 |
| det_db_box_thresh | float | 0.6 | 检测结果边框内,所有像素点的平均得分大于该阈值时,该结果会被认为是文字区域 |
| det_db_unclip_ratio | float | 1.5 |
算法的扩张系数,使用该方法对文字区域进行扩张 |
| max_batch_size | int | 10 | 预测的batch size |
| use_dilation | bool | False | 是否对分割结果进行膨胀以获取更优检测效果 |
| det_db_score_mode | str | “fast” |
DB的检测结果得分计算方法,支持和 , 是根据polygon的外接矩形边框内的所有像素计算平均得分, 是根据原始polygon内的所有像素计算平均得分,计算速度相对较慢一些,但是更加准确一些。 |
更多参数可以在PaddleOCR\doc\doc_ch\inference_args.md《PaddleOCR模型推理参数解释》里面找到
我修改后文件命名为
ch_PP-OCRv3_det_student_3.7.yml
Global:
debug: false
use_gpu: true
epoch_num: 135 # 总的epoch数目
log_smooth_window: 20
print_batch_step: 10
save_model_dir: ./output/ch_PP-OCR_V3_det_11_9/
save_epoch_step: 100 # 每100个global_step 保存一次模型
eval_batch_step: # 每200个global_step 验证一次模型
- 0
- 200 # 400
cal_metric_during_train: false # 设置是否在训练过程中评估指标,此时评估的是模型在当前batch下的指标
pretrained_model: null
checkpoints: null
save_inference_dir: ./output/det_db_inference/ # null
use_visualdl: True # false
infer_img: DATA2/predict01.jpg # doc/imgs_en/img_10.jpg
save_res_path: ./output/det19/predicts_ppocrv3_distillation.txt # ./checkpoints/det_db/predicts_db.txt
# save_res_path: ./output/det2/predicts_ppocrv3_distillation.txt # ./checkpoints/det_db/predicts_db.txt
distributed: true
Architecture:
model_type: det # 网络类型
algorithm: DB # 模型名称
Transform: # 设置变换方式
Backbone:
name: MobileNetV3
scale: 0.5
model_name: large # 网络大小
disable_se: True
Neck:
name: RSEFPN
out_channels: 96
shortcut: True
Head:
name: DBHead
k: 50 # DBHead二值化系数
Loss:
name: DBLoss
balance_loss: true # DBLossloss中是否对正负样本数量进行均衡(使用OHEM)
main_loss_type: DiceLoss # DBLossloss中shrink_map所采用的的loss
alpha: 5 # DBLossloss中shrink_map_loss的系数
beta: 10 # DBLossloss中threshold_map_loss的系数
ohem_ratio: 3
Optimizer: # 主要修改部分
name: Adam
beta1: 0.9
beta2: 0.999
lr: # 设置学习率下降方式
name: Cosine # 使用cosine下降策略
learning_rate: 0.00005 # 0.001
warmup_epoch: 2
regularizer: # 正则化
name: L2
factor: 5.0e-05 # 正则化系数
PostProcess:
name: DBPostProcess
thresh: 0.42 # 输出的概率图中,得分大于该阈值的像素点才会被认为是文字像素点
box_thresh: 0.52 # 检测结果边框内,所有像素点的平均得分大于该阈值时,该结果会被认为是文字区域
max_candidates: 1000
unclip_ratio: 2.6 # 算法的扩张系数,使用该方法对文字区域进行扩张
Metric:
name: DetMetric
main_indicator: hmean
Train:
dataset:
name: SimpleDataSet
data_dir: ./train_data/det/train/ # ./train_data/icdar2015/text_localization/
label_file_list:
- ./train_data/det/train0.txt # ./train_data/icdar2015/text_localization/train_icdar2015_label.txt
- ./train_data/det/train1.txt
- ./train_data/det/train2.txt
- ./train_data/det/train3.txt
ratio_list: [1.0, 1.0, 1.0, 1.0]
# ratio_list: [1.0]
transforms:
- DecodeImage:
img_mode: BGR
channel_first: false
- DetLabelEncode: null
- IaaAugment:
augmenter_args:
- type: Fliplr # 翻转
args:
p: 0.5
- type: Affine # 仿射
args:
rotate:
- -10
- 10
- type: Resize # 调整大小
args:
size:
- 0.5
- 3
- EastRandomCropData:
size:
- 960
- 960
max_tries: 50
keep_ratio: true
- MakeBorderMap:
shrink_ratio: 0.4
thresh_min: 0.3
thresh_max: 0.7
- MakeShrinkMap:
shrink_ratio: 0.4
min_text_size: 8
- NormalizeImage: # 图像归一化
scale: 1./255. # 线性变换参数
mean:
- 0.485
- 0.456
- 0.406
std:
- 0.229
- 0.224
- 0.225
order: hwc
- ToCHWImage: null
- KeepKeys:
keep_keys:
- image
- threshold_map
- threshold_mask
- shrink_map
- shrink_mask
loader:
shuffle: true
drop_last: false
batch_size_per_card: 2
num_workers: 0 # 4
Eval:
dataset:
name: SimpleDataSet
data_dir: ./train_data/det/val/ # ./train_data/icdar2015/text_localization/
label_file_list:
- ./train_data/det/val0.txt # ./train_data/icdar2015/text_localization/test_icdar2015_label.txt\
- ./train_data/det/val1.txt
- ./train_data/det/val2.txt
- ./train_data/det/val3.txt
# ratio_list: [1.0, 1.0, 1.0, 1.0] #
# ratio_list: [1.0]
transforms:
- DecodeImage:
img_mode: BGR
channel_first: false
- DetLabelEncode: null
- DetResizeForTest: null
# image_shape:
# - 736
# - 736
# resize_long: 960
# limit_side_len: 736
# limit_type: min
# keep_ratio: true
- NormalizeImage:
scale: 1./255.
mean:
- 0.485
- 0.456
- 0.406
std:
- 0.229
- 0.224
- 0.225
order: hwc
- ToCHWImage: null
- KeepKeys:
keep_keys:
- image
- shape
- polys
- ignore_tags
loader:
shuffle: false
drop_last: false
batch_size_per_card: 1
num_workers: 0 # 2
其中的label_file_list参数对应的txt,记得修改成服务器保存数据的实际路径
如果有多个txt,可以用逗号并列
启动训练
# 单卡训练
python tools/train.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student_3.7.yml -o Global.pretrained_model=student/ch_PP-OCRv3_det_distill_train/student.pdparams
# 如果要使用多GPU分布式训练,请使用如下命令:
python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml \
-o Global.pretrained_model=./student \
Global.save_model_dir=./output/
注意写对yml文件里面的数据集和label文件路径,以及ratio_list: [1.0]不然可能会报错:
AssertionError: The length of ratio_list should be the same as the file_list.
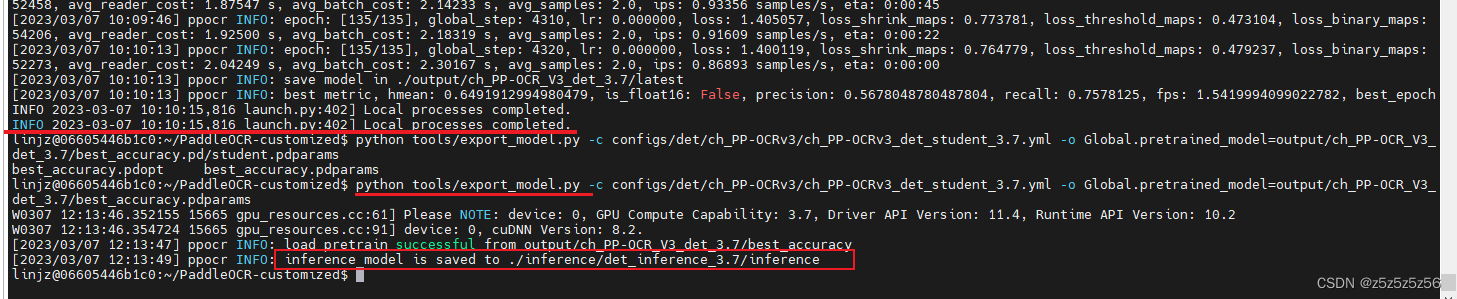
导出模型
我训练了3h,训练模型格式还要进行export为推理模型格式,才可用例程代码推理
python tools/export_model.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student_3.7.yml -o Global.pretrained_model=output/ch_PP-OCR_V3_det_3.7/best_accuracy.pdparams
测试
与微调前的v3模型相比,进行det推理测试,看看自训练模型效果是否有改善