Python的基本数据类型
基本数据类型 – 数值
一 数值类型(不可变数据类型) :
整型(int) 浮点型(float) 复数类型(complex) à 数值运算过程下,会自动从左到右进行转换
布尔类型(bool) à 只有 True 和 False 两种结果 ;
1 bool 继承了 int 类型,因此可直接使用 bool 参与数学运算 ,int(True) = 1 , int(False) = 0
2 非零,非空为 真 , 零值,空值为假
PS –
type( ) 函数可以参与 数据类型的查看
强制类型转换 int float complex
关于 float 涉及的运算精度问题 – 有效保证 小数点后16位
int(“整数字符串”,n)
int(“111”) à 111 默认转化为十进制数 111
int(“111”,2) à 7 指定参数 2 将其转化为二进制数 7
二 数值运算
1 算数运算 + – * ** / // %
Ps –
“/” 真除法,以实际结果为准,保留至少一个小数位,最多保留16位
“//”, “%” 取整,取余 ,运算结果的类型取决于操作数的类型
2 比较运算 == != > < >= <=
Ps –
数值进行比较时,以大小进行比较 ; 字符进行比较时,转化为 ASCII对应的值进行比较
3 赋值运算符 = += -= *= /= **= %= //=
4 位运算 & | ~ ^ << >>
Ps –
处理位运算的过程中,需要首先将其转换为 二进制 模式进行处理,然后按照对应位以相应的位运算法则进行处理
5 逻辑运算 and or not
Ps –
and or 参与的运算 ,其结果为对象的值
not 参与的运算 ,其结果布尔类型(True,False)
6 成员运算符 in , not in
Ps –
成员运算符,对其结果的判定取决于两个条件:值与类型
7 身份运算符 is , not is
Ps –
用于比较两个对象的内存地址,可用于判定两个变量是否应用于一个相同的对象
三 关于小数的精度处理
A 由于整数可以处理任意大类型的数,故可以将某些小数进行整数化(放大)
B 小数对象 – 使用 decimal 包下的 Decimal 函数创建
看作固定精度的浮点数,它有固定的位数和小数,可以满足要求的精度计算


C 分数 – 使用 fractions 模块下的 Fraction函数来创建
使用分数可以有效的避免浮点数误差
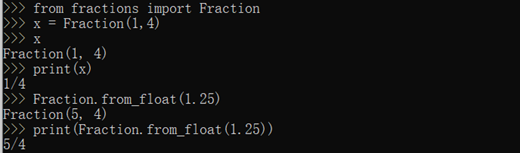
PS –
Python 变量与对象
X = 5
Python 在执行上述语句的过程中包含了3大步骤:
1 创建表示 整数的对象 5 , 在 Python 中的数据都是以对象方式存在
2 检查变量 X 是否存在 , 不存在则创建它
3 建立变量 X 到 5 之间的关系—变量 X 引用对象 5
Ps – Python 中使用变量时,必须理解下面几点:
1 变量在第一次赋值时被创建,再次出现时直接使用
2 变量没有数据类型的概念,数据类型属于对象,类型决定了对象在内存下的存储模式
3 变量引用了对象,当在表达式中使用变量时,变量立即被其引用的对象替代,所以变量在使用前必须对其赋值
Ps–Python 对象的垃圾回收
当对象没有任何引用时,其占用的内存空间会被自动回收
在 Python 内部,Python 为每一个变量创建一个计数器,计数器记录对象的引用次数;若计数器为0,则对象被删除,其占用的空间将会被回收
补充:
1 关于变量名的命名规则 –
前后有下划线的变量,通常为系统变量 ;例如 _name_ , _doc_ …
以一个下划线开头的变量,不能被 from … import * 语句从模块下导入 ;例如 _abc
以两个下划线开头无下划线结尾的变量是类的本地变量 ;例如 __abc
2 关于赋值语句 –
一 序列赋值
1 “=” 左侧是元组,列表表示的变量名,右侧是元组,列表,字符串等
x,y = 1,2
[x,y] = (10,20 )
[x,y] = [20,”abc”]
2 当“=” 右侧是字符串时,Python会将字符串分解为单个字符,依次赋值给各个变量
(x,y,z) = ‘abc’
((x,y),z) = ‘abc’
3 可以在变量名之前合理使用 * 号,此时,不带星号的变量匹配一个值,其余的都将赋给星号的变量
x,*y = ‘abcd’
*x , y = ‘abcd’
x,*y,z = ‘abcd’
二 多目标赋值
使用 = 实现连续赋值
a = b = c = 10
三 关于变量的共享引用
可以借助 身份运算符 is 来判断两个变量是否引用于同一个对象
x = 4
y = x
x = 7
思考 y 是否会受到 x 的影响
x = [4,5,6]
y = x
x[0] = 7
思考 y 是否会受到 x 的影响
基本数据类型 – 字符串
一 字符串的表示及其用法—
表示方法 :
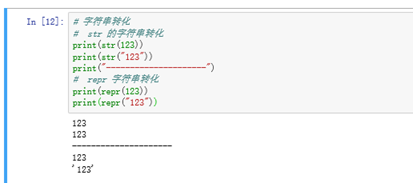
1. 通过引号进行表示 例如: ‘a’ “a” 等
2. 利用内置的 str 函数 进行转换 例如: str(123)
3. 使用带有 r或R/b/B前缀的Raw字符串 例如: r’abc\n123’
4. 使用带有 u或者U 前缀的 Unicode 字符串 例如: u’asdf’
思考题: 如何有效完成一个路径字符串的输入
假定字符串为 : C:\Users\Pluto
1 借助转义字符 \ 来实现对 “\”的处理
2 采用使用带有 r或R/b/B前缀的Raw字符串
例如 :
“C:\\Users\\Pluto”
r“C:\Users\Pluto”
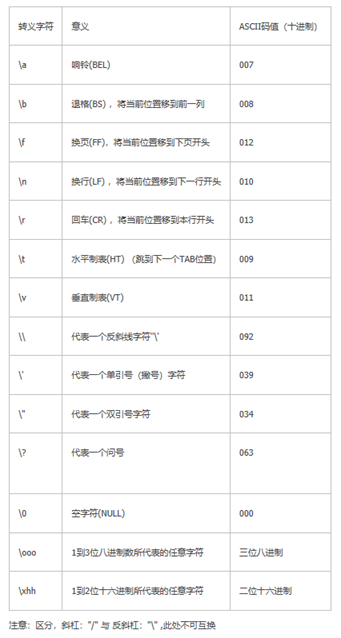
PS – 转移字符
Ps – bytes 字符串
表达式 à b+传统字符串 例如:b’a’ , b’123’ , b’Python code’ ,
注意:
字符串中只包含 ASCII 码字符
使用时,bytes字符串返回对应的字符的 ASCII 码
二 字符串的相关运算
索引与切片
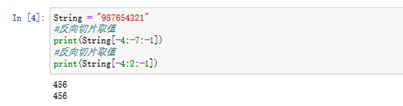
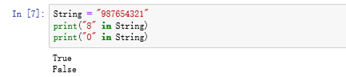
例如:给定一个字符串 String = “987654321”
正向
0
1
2
3
4
5
6
7
8
元素
9
8
7
6
5
4
3
2
1
反向
-9
-8
-7
-6
-5
-4
-3
-2
-1
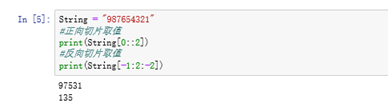
1 利用索引进行值的选择,
例如 取出当前元素 String 中的 6 ,可以采用如下方式

2 利用索引来完成切片选择
例如: 利用正向 取出一定范围的元素 654 ,可以采用如下方式

例如: 利用反向 取出一定范围的元素 456 ,可以采用如下方式
PS – 关于利用索引进行切片的过程中,需要特别注意,在已经给定的方向上,一般要满足两个条件,其一一致方向,其二起始值小于终止值
一个的格式如下:
String[ start : end : step ] 其中 start 代表起始值 , end 代表终止值,step 可以约束方向以及数据间隔
例如
3 计算字符串的长度 — len( ) 函数

4 关系判断 — in , not in
5 字符串的连接
1 * 完成的复制(只可以乘以一个 正整数类型)
2 + 完成组合

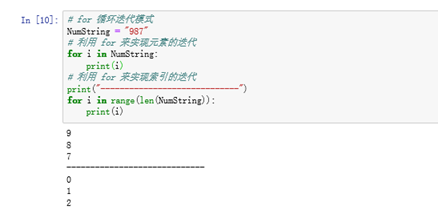
6 字符串的迭代 — 可利用 for 循环迭代来处理序列类型的字符串
序列迭代的模式有两种:一种是元素的迭代,一种是索引的迭代
补充 — 字符串的格式化输出
一 以 % 占位符模式
譬如 print(“The %s’s price is %4.2f” %(“apple”,2.5))
字符串之前的部分表示格式化表达式输出的部分
字符串之后的部分表示参数列表部分

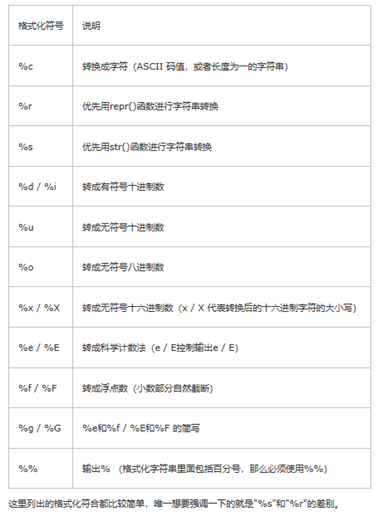
PS – 格式化表达式的基本结构
%[填充方式][对齐方式][数字宽度][小数点位数][格式化输出类型]
格式化控制符 —
二 以 格式化输出函数 format
格式:<模板字符串>.format(<逗号分隔的参数>)
格式化输出 – 槽与槽位


槽内部对格式化的配置方式

例如:


字符串的常用方法 — “方法”特指.
()风格中的函数
( )
str.lower() 或str.upper() 返回字符串的副本,全部字符小写/大写
str.split(sep=None) 返回一个列表,由str根据sep被分隔的部分组成
str.count(sub) 返回子串sub在str中出现的次数
str.replace(old, new) 返回字符串str副本,所有old子串被替换为new
str.center(width[,fillchar]) 字符串str根据宽度width居中,fillchar可选
str.strip(chars) 从str中去掉在其左侧和右侧chars中列出的字符
str.join(iter) 在iter变量除最后元素外每个元素后增加一个str

补充 — 一些以函数形式提供的字符串处理功能
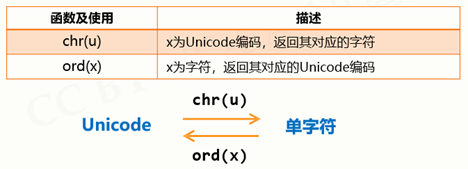
补充:Unicide编码 — 统一字符编码,即覆盖几乎所有字符的编码方式;从0到1114111 (0x10FFFF)空间,每个编码对应一个字符;Python字符串中每个字符都是Unicode编码字符

练习题 :
1 随机生成 20 个数 , 完成这20个数的 均值,方差以及标准差的计算
2 完成任意给定的两个数的最大公约数的计算
3 试给出如下数列的前21项:
1 1 2 3 5 8
4 输出九九乘法表
5 输出21层金字塔
6 输出 1-1000以内的所有回文数