之前学习python和fortran的时候已经查过很多次相关内容了,有的内容也会添加到网页收藏夹里。但由于我干的事情很杂(也可能是记性不好),查过的东西总是会忘,忘了再查,查了再忘,索性就专门整理一下以备不时之需吧。(不定期更新)
一、python
1、查找import库的位置
python
二、numpy
1、将数组内nan的值转为0.0
a
2、数组内某数的个数和位置
np.sum(a == 1)
np.where(a ==1)
3、将某列中含有某值的行删除
用到了取反~
site_id_from_step1 = site_id_from_step1[~site_id_from_step1.loc[:,2].isin([-1])]
4、删除有nan的行
delete_nan = pd.DataFrame(delete_nan)
delete_nan = delete_nan.dropna(axis=0,how='any') # 删除有nan的行
delete_nan = delete_nan.dropna(axis=0,how='all') # 删除所有列都是nan的行
5、将数组重复n遍
x = np.tile(ec_lon[0], ec_lat.shape[0])第一个参数是需要被重复的数组,第二个输入参数是重复几遍的几
三、matplotlib
1、contourf(x, y, z, np.arange(np.min(z), np.max(z)+0.01,0.01))中为第四个参数来控制显示范围和间隔
2、如果子图的标题和上一个子图的xlabel重合了
plt.tight_layout()即可
3、涉及到basemap绘图的时候,有时候莫名其妙,figure的外框没了,用常规的方法如:
ax = plt.subplot(111)
ax.spines['top'].set_visible(True)行不通,那么解决办法是
m.drawparallels(np.arange(0., 52., 0.5), labels=[1,0,0,0], fontsize=20,linewidth=1.0)重点是linewidth加上就行,当然有时候直接重启Spyder也能解决问题
4、关于plt.hist
count n是每个间隔内数值出现的个数,bins是每个间隔的位置(每个间隔分左右端,bins包含了第一个间隔的左端和最后一个间隔的右端,所以bins.shape[0]=n.shape[0]+1),spatches不用管。
常规得到的是频数分布图,即纵坐标表示每个间隔内数值出现的个数。若想改为频率分布直方图,老版的matplotlib用到了normed,设为True或者非0数即可,得到的结果是n的值与相应间隔的长度相乘结果为1。
若想得到纵坐标是出现的频率,且不需要面积为1(即上述normed=True),那么有两种办法,第一种如plt.subplot(513),即把hist得到的n通过plt.bar重新绘制;第二种方法是利用plt.hist中的weights,如plt.subplot(515)中的设置,即可得到频率单位为%的结果。第二种方法更为简单。
多说一句,如果是以hist的形式来比较两组数据,最好还是使用normed=True即标准化之后的结果。因为,如果不进行标准化,只是呈现原始数据的话,由于两组数据的间隔范围与间隔长度是不同的,所以会导致看上去是不平衡不协调的。
5、关于spines的相关操作:
plt.gca().spines["top"].set_alpha(0.0)
# plt.gca().spines["bottom"].set_alpha(1.2)
plt.gca().spines["right"].set_alpha(0.0)
# plt.gca().spines["left"].set_alpha(1.2)
plt.gca().spines['bottom'].set_linewidth(2.0)
plt.gca().spines['left'].set_linewidth(2.0)
四、Pandas
1、关于DataFrame插入、删除、重命名列[Post_model.py]
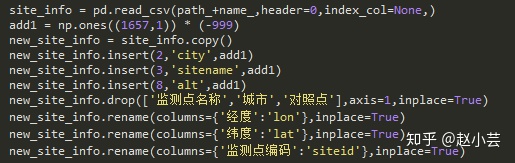
2、读入带有日期格式的数据
2.1 、日期和时间分为了两列

2.2 、日期时间格式不是常规格式

3、发现如下错误,可能是文件确实不存在,修改代码过程中,重复使用某个变量,使得原始变量值被覆盖,当然也会出现windows系统把.txt变为了.txt.txt格式(百度时看到的例子)

4、处理如图所示,相对复杂的excel时(以读取温度为例,风场类似[Post_WRF.py]):
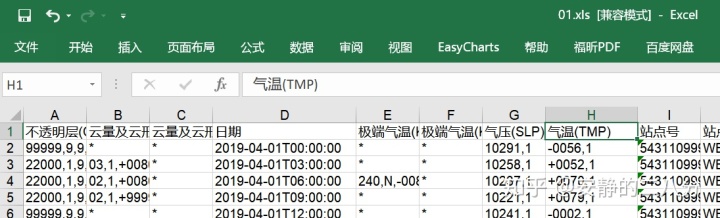
data_obs 通过上述两步可得到如下结果(重点是pandas的.str.split命令):
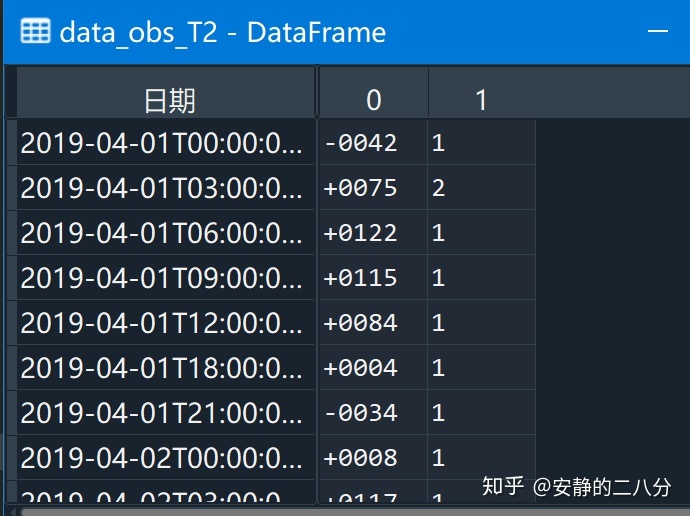
data_obs_T2['zhengfu'] = data_obs_T2[0].str[:1]
data_obs_T2['values'] = data_obs_T2[0].str[1:]然后得到:
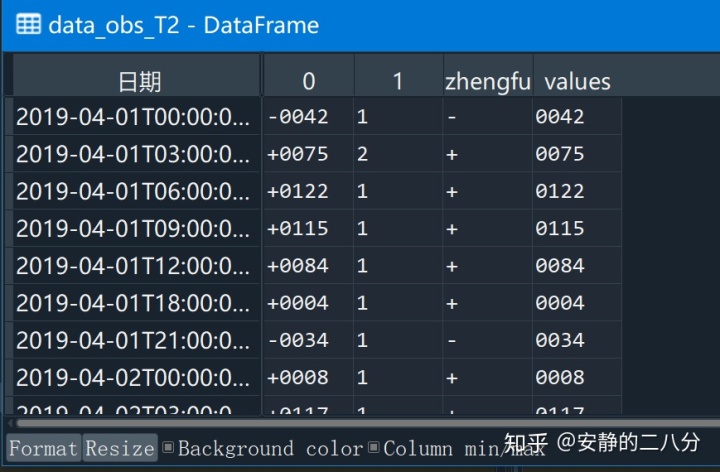
随后用一个for循环遍历整个DF,得到相应的结果,注意str2float直接float()即可,同时还包含有一个UTC2LST的转化:
real_data = np.zeros((data_obs_T2.values.shape[0]))
for i in np.arange(0,data_obs_T2.values.shape[0]):
if data_obs_T2['zhengfu'][i] == '-':
param = -1.0
else:
param = 1.0
tmp1 = float(data_obs_T2['values'][i])
tmp2 = param * tmp1 / 10
real_data[i] = tmp2
data_obs_T2['real values'] = real_data
data_obs_T2 = data_obs_T2['real values']
data_obs_T2_index = data_obs_T2.index
data_obs_T2_index = data_obs_T2_index + pd.Timedelta(hours=8)
data_obs_T2.index = data_obs_T2_index
五、basemap
1、readshapefile[ZYC_
flexpart_D20200703
_autosave.py]
这个函数的第一个输入参数是路径,第二个是属性名,随便输入啥都可以。此外,如果用这个函数读取别人给你的shp文件发现读取失败时,可能是编码的原因,可添加default_encoding参量
m
六、Fortran
1、do循环的等价性
do
2、Fortran居然有个判断NaN的函数 isnan()
if ( isnan(a) ) then
write(*,*) 'a is NaN'
end if
七、linux
1、vim显示某字符串出现次数
:%s/字符串//ng
2、如果碰到一个巨大的文件想要vim,但是内存不给力咋办
head -n 100000 log.out > log.out_head_100000
tail -n 100000 log.out > log.out_tail_100000
3、关于等号前后要不要空格的问题
-
针对.bashrc,在export变量的时候等号前后
不能有
空格 -
针对csh shell脚本,set变量的时候前后
一定要有
空格