哈希表的特点在做一些删去重复元素还有有关重复问题的时候可以用到,还有特点就是快速查找,插入和删除。
哈希表也叫做散列表,是根据关键码值(key-value)而直接进行访问的数据结构,也就是我们常用到的map。
哈希函数:也称为是散列函数,是Hash表的映射函数,它可以把任意长度的输入变换成固定长度的输出,该输出就是哈希值。哈希函数能使对一个数据序列的访问过程变得更加迅速有效,通过哈希函数,数据元素能够被很快的进行定位。
哈希表和哈希函数的标准定义:若关键字为k,则其值存放在h(k)的存储位置上。由此,不需比较便可直接取得所查记录。称这个对应关系f为哈希函数,按这个思想建立的表为哈希表。
例如leetcode中的205题。
205. 同构字符串
给定两个字符串
s
和
t
,判断它们是否是同构的。
如果
s
中的字符可以按某种映射关系替换得到
t
,那么这两个字符串是同构的。
每个出现的字符都应当映射到另一个字符,同时不改变字符的顺序。不同字符不能映射到同一个字符上,相同字符只能映射到同一个字符上,字符可以映射到自己本身。

在本题中,一个s中的字符只能对应一个t中的字符,如果一个字符对应两个则报错,并且不能改变顺序。因此我们在本题中选择哈希表来实现算法。
class Solution {
public:
bool isIsomorphic(string s, string t) {
unordered_map<char,char>s2t; //建立对s字符串的哈希表
unordered_map<char,char>t2s; //建立对t字符串的哈希表
int len=s.size();
for(int i=0;i<len;i++){
char x=s[i],y=t[i];
if((s2t.count(x)&&s2t[x]!=y)||(t2s.count(y)&&t2s[y]!=x)){
//确保已经重复并且第一次之后的值要与第一次映射的值要相同,如果不同,返回false。
return false;
}
s2t[x]=y; //为第一次的映射赋值
t2s[y]=x;
}return true;
}
};
哈希表的时间复杂度为O(1),由于每一个 key 到 address 的映射关系需要记录下来,空间复杂度为O(n)。
————————————————
以下资料来源为CSDN博主「爱吃锅巴饭」的原创文章
原文链接:
https://blog.csdn.net/bryant_zhang/article/details/111600209
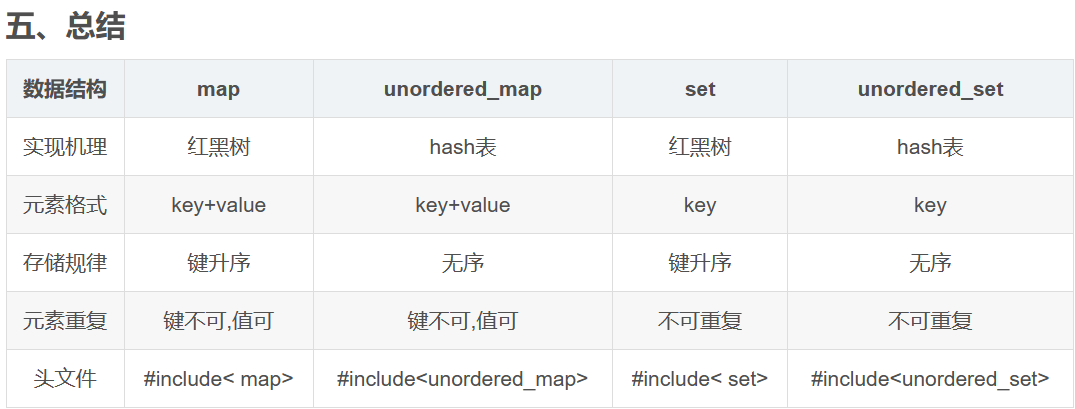
unordered_map和unordered_set的区别
unordered_map
内部实现机理
unordered_map内部实现了一个 哈希表(也叫散列表,通过把关键码值映射到Hash表中一个位置来访问记录,查找的时间复杂度可达到O(1),其在海量数据处理中有着广泛应用)。因此, 其元素的排列顺序是无序的。
优缺点以及适用处
优点: 因为内部实现了哈希表,因此其查找速度非常的快(运行效率快于map)
缺点: 哈希表的建立比较耗费时间(unorder_map占用的内存比map要高)
适用处:对于查找问题,unordered_map会更加高效一些,因此遇到查找问题,常会考虑一下用unordered_map
unordered_set
内部实现机理
unordered_set的内部实现了一个 哈希表,因此, 其元素的排列顺序是无序的。