如果计算机的 CPU 只有「x86」这一种,或者操作系统只有 Windows 这一类,那么或许 Java 就不会诞生。Java 诞生之初就曾宣扬过它的初衷,「一次编写,多处运行」,而它之所以能够实现跨平台的一个核心点就在于,
Java 引入「字节码」屏蔽了与底层操作系统之间的差异
。
同一段 Java 程序在编译后生成的字节码文件是唯一的,不会因为平台的不同而产生任何的变化。而同一段字节码跑在不同实现的 JVM 上,会产生不同的机器指令。于底层而言,其实 Sun 公司针对不同的操作系统开发了不同版本的 JVM,而这些 JVM 则通过识别上层的字节码并向下解释给操作系统执行。因此,你的同一段字节码在不同平台下的 JVM 上运行,会对应到不同的机器指令,以此实现了跨平台运行。
而理解这个「字节码」文件结构就显得十分重要了,理解它是如何存储我们程序中的字段、方法、属性、局部变量、各种常量值等等,是学习虚拟机工作原理的基础。
那么,本文就来分析一下这个「字节码」文件,解开它的神秘面纱。
Class 文件的总体概况
我们的 Java 文件被编译器编译成 Class 文件之后,整个 Class 文件由若干个 0 和 1 组成为一个超长的「二进制串」。各个项目按照严格的规范存储并顺序的排在一起,每个项目占几个字节几乎固定,所以 JVM 在解析的时候,只需要按照我们制定的规范一项一项的拆分解析即可。
整个 Class 文件的各个项目以及它们之前的排列顺序都是固定的,如图:
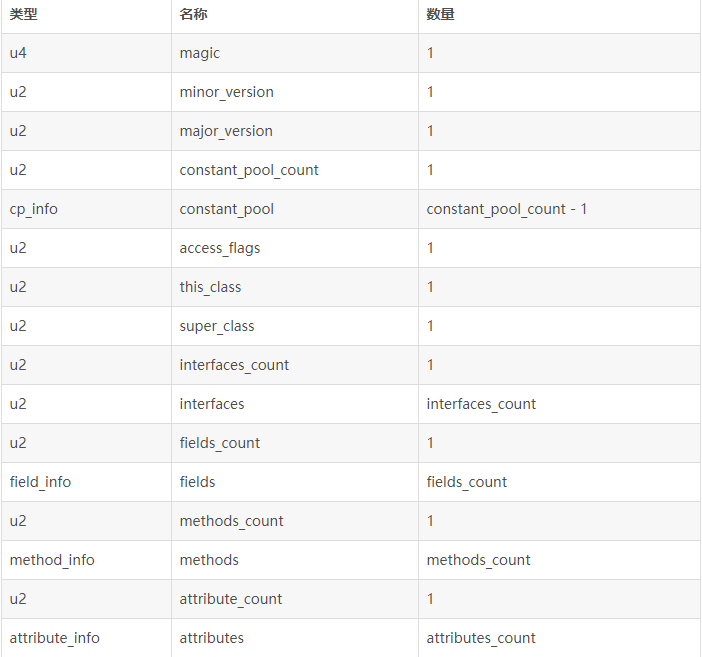
其中 u2 表示当前的项目总共占两个字节,当然,u4 表示占四个字节。以 _info 结尾的项目表述为一张表,具体占多少字节数需要参见该表的内部结构。其实,宏观上来看,整个 Class 文件也可以被看做是一张表。
魔数与 Class 文件的版本
Class 文件开头的四个字节存储的是当前文件的「魔数」,
所谓的「魔数」就是用于标识当前的文件是一个由 Java 文件编译过来的 Class 文件
。不是什么文件拿过来,我虚拟机都接受并运行的,因为文件的扩展名是可以随意更改的,所以有些文件可能就不是 Java 文件编译而来的。
不同类型的文件有着不同的魔数值,图片格式有图片格式的的魔数值,视频格式有视频格式的魔数值,而我们 Class 文件的魔数值为:
0xCAFEBABE
。我们使用 UltraEdit 任意打开一个 Class 文件,会发现前四个字节都是一样的。
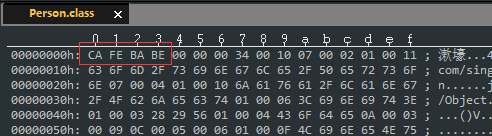
参见 Class 文件的结构图,接下来的 minor_version 和 major_version 用于表述当前 Class 文件的版本号。前者占两个字节,描述的是 Class 文件的「次版本号」,后者也占两个字节,描述的是 Class 文件的「主版本号」。
jdk1.1 之后的每个较大的版本都基于 jdk1.1 的主版本号加一,而 jdk1.1 的主版本号是从 45 开始的。所以,jdk1.2 的主版本号为 46,jdk1.3 的主版本号为 47 。当然,对于每个 jdk 版本中较小的变化而言,主版本号的值就不会发生变化,变化的是次版本号的值。
例如:jdk1.1.8 的版本号为 45.3,其中 45 是主版本号,3 是次版本号。
其实,基本上 jdk1.2 以后的版本就只使用主版本号了,次版本号全为 0 。我电脑上的 jdk 版本是 1.8 的,于是得到它的版本号为 52(45+7) 。
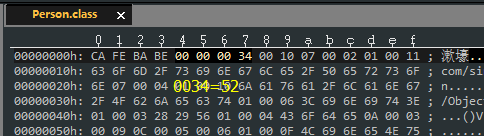
那这个版本号有什么用呢?
虚拟机规范中指明,低版本 jdk 中的虚拟机不能运行高版本的 Class 文件,而高版本 jdk 中的虚拟机则可以运行低版本的 Class 文件。话可能有点绕,但主要意思就是,JVM 拒绝运行比自己版本低的 Class 文件。
常量池
常量池算是类文件中比较繁琐的一块内容了,在解析它之前我们先看一段 Java 代码。
public class Person implements Serializable {
private int num;
private String name = "Yang";
public void sayHello() {
System.out.println("hello,my name is:" + this.name);
}
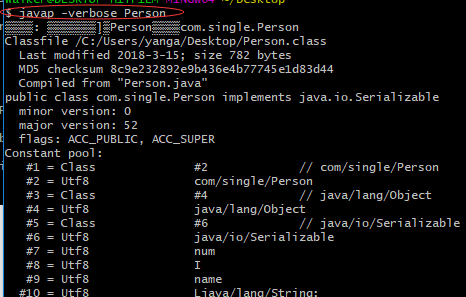
}这是一段再简单不过的 Java 代码,我们打开它编译后的 Class 文件。
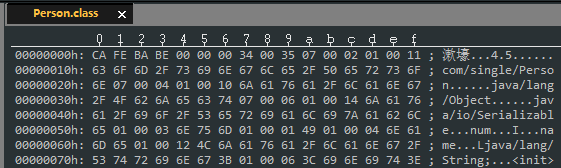
根据我们的 Class 文件格式,第 9,10 两个字节表述 constant_pool_count,它代表了常量池中的容量。从图中我们也可以看出来,constant_pool_count = 0x0035 = 53 。由于 Class 文件格式规定常量池中的项从 1 开始计数,而不是从我们习惯的 0 开始的。所以整个 Class 文件中共有 52(
[1,53)
) 个常量项,0 这个位置用于表述「不引用任何一个常量池项目」。
接下来的一项,Class 文件格式中并没有明确指明它总共占据多少个字节,而只是声明它是一张表。常量池中可以被定义的项目类型:
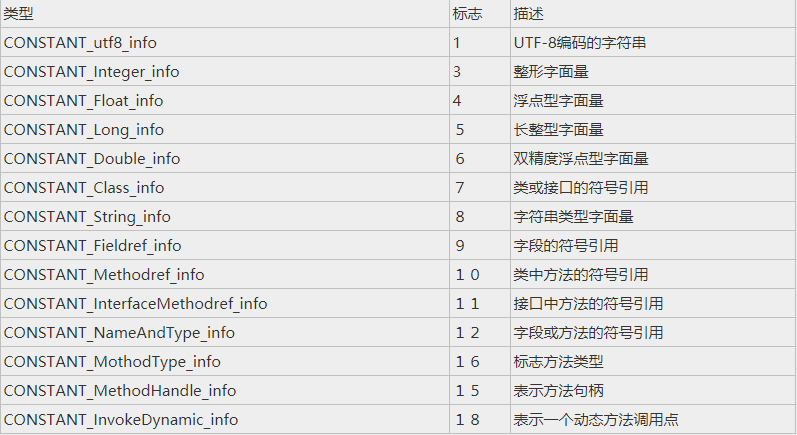
每一项又都是一张表,我们 52 个常量项就是这些项目的组合。因为每个常量项所对应的表结构都不尽相同,所每个常量项的表结构中第一个字节存储的就是一个标志,用于区分当前项的类型。例如:
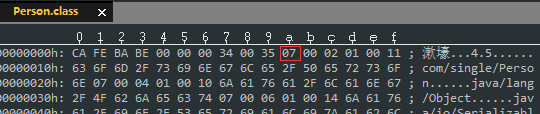
这个值是 7,对应的我们的常量项是 CONSTANT_Class_info。
于是调来 CONSTANT_Class_info 表的结构:

CONSTANT_Class_info 总共占三个字节,第一个字节存储的标志,不再多说。name_index 占两个字节,它是一个偏移地址,我们从上图可以得到它的值是:0x0002,即它指向常量池中第二项常量。
我们去看看第二项常量是什么,0x01 是它的标志,表明它是 CONSTANT_Utf-8_info 类型的常量。
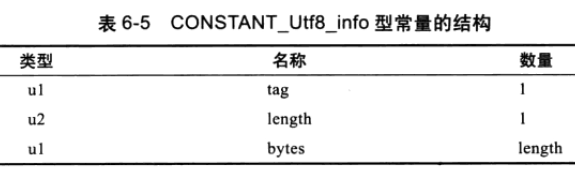
length 占两个字节,本例中的值为:
0x0011 = 17
。所以该常量项还有 17 个 bytes 存储的是该常量的 utf-8 编码值。可以看到:
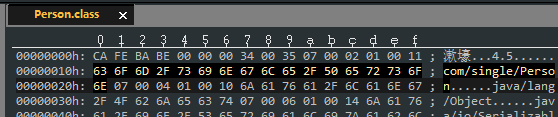
这 17 个字节表述的 utf-8 字符串为:
com/single/Person
我们手动的「翻译」了常量池中前两项,其实 Sun 公司为我们提供了工具帮我们计算字节码文件中各个项目,这些工具都是非常好用的。
这里我们只分析了两种常量项的表结构,其余 12 种大家可以自行搜索了解。我们常量池所有的常量都是有用的,Class 文件结构中其他项目几乎都会引用这里面的常量,待会再解释。
访问标志
访问标志用于描述类文件的一些详细信息,这个 Class 是类还是接口,修饰为 public 或 protected,是否修饰为 final 等。Class 文件格式定义了访问标志占两个字节,总共 16 个比特位。
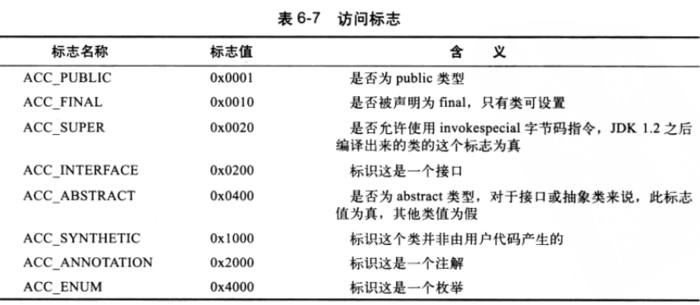
很简单,一共 16 个比特位,这里只使用了 8 个比特位,如果最低位为 1 说明该 Class 被修饰为 public,为 0 则说明没有被修饰为 public。一个标志占了一个位,有两个状态,1 为被修饰了某个状态,0 表示没有被修饰为某个状态。
例如:
0x0011(0000 0000 0001 0001):public + final
0x0201(0000 0010 0000 0001):public + 接口
类、父类、父接口索引的集合
这三个项目用于描述 Class 文件的继承相关信息,它们按顺序排列在访问标志后。根据我们的 Class 文件格式,this_class 占两个字节,存放的是相对于常量池的偏移值,同理 super_class 是其父类的符号引用。Java 除了 Object 类没有父类,其他任何类都是有且仅有一个类,所以 Object 类的 super_class 的值为 0,表示未引用常量池中任何一项。
以我们上述的例子来说:

this_class 指向常量池中第一项,super_class 指向常量池中第三项。通过查看常量池中的内容,发现他们所对应的常量项类型是 CONSTANT_Class_info ,继续深入得到类的全限定名分别是:
com/single/Person 和 java/lang/Object
。
接口项有稍许不同,因为 Java 中允许接口的多继承,所以表述接口需要使用两项,interfaces_count 占两个字节,计数了 Class 文件实现的接口数量,interfaces 占两个字节,存储的是相对于常量池的偏移值。
这里,interfaces_count 的值为:
0x0001
,interfaces 的值为:
0x0005
。于是得到该 Class 文件所实现的接口的名称为:
java/io/Serializable
。
字段表集合
字段其实就是接口或者类中定义的变量,有实例变量和类变量之分。当然,方法中定义的局部变量肯定不能算字段的,字段特指那些定义在方法之外,类或接口之中的变量。
每个字段表只能描述一个字段的信息,一个 Class 文件中往往又有多个字段,所以 Class 文件格式在字段表之前定义了两个字节的项 fields_count 来计数字段的数量。
字段表的标准结构如下:

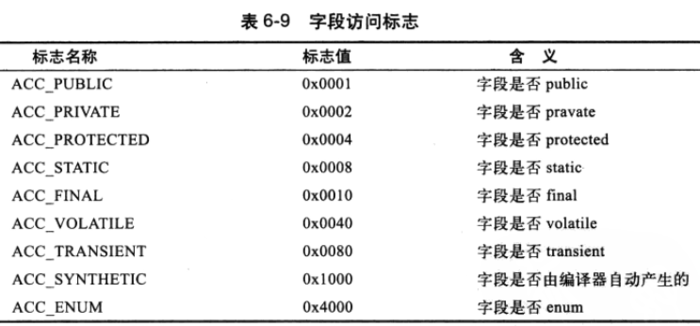
access_flags 占两个字节,它描述了该字段的基本访问标志,主要包括:字段的作用域,实例或类变量(static),可否序列化(transient),可变性(final)等等。这个属性的存储形式和我们之前介绍的类的访问标识存储的思想是类似的,每种状态使用一个比特位来标识对于该状态的修饰与否。
参见我们上述的例子:
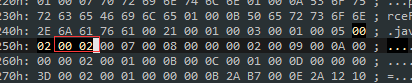
第一个 0x0002 表示字段表数量为 2,即当前 Class 文件中有两个字段。第二个 0x0002 表示当前字段被 「private」 关键字修饰。
我们接着看这个字段表。
name_index 占两个字节,它存储的是当前字段的名称在常量池中的偏移量值。
descriptor_index 占两个字节,它是对当前字段基本数据类型的描述,存储的也是一个字符常量在常量池中的偏移值。但是你如果对应到常量池中去看的话,你会发现这个描述符的的值是:
I

基本数据类型与实际存储的符号之间有这么一种映射关系,为的是简单存储。其中,如果字段是数组类型的话,需要前置一个 『
[
』,多维数组就前置多个该符号进行描述。
接着看字段表。
接下来的 attributes_count 和 attributes 描述的是当前字段的「属性」。所谓「属性」也即字段的额外信息描述。我们的第一个字段没有额外的属性,所以 attributes_count 为 0 。
下面我们完整分析一下第二个字段的字节码:
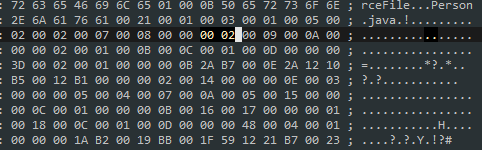
access_flags 的值为 0x0002,对应的访问修饰符是:
private
。name_index 的值对应于字段名称在常量池中的偏移值。
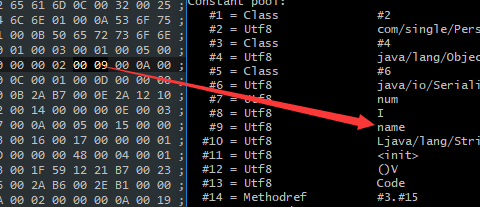
descriptor_index 的值为:
0x000A
,对应的常量值是:
Ljava/lang/String
。同样,它也没有属性描述。
方法表集合
理解了字段表,方法表的内容就很容易理解了。下面是方法表的标准结构:

针对我们上述的示例,简单分析一下:
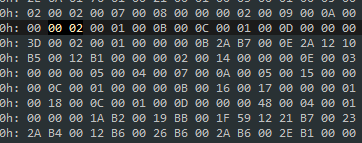
首先,0x0002 表示整个 Class 文件中有两个方法(一个是我们自己编写的 sayHello 方法,还有一个是编译器增加的实例构造器《init》方法)。
然后,0x0001 指明了该方法的访问标志:
public
,0x000B 指明了该方法名称在常量池中的偏移值,对应到常量池中的常量:
。
接下来是这个 descriptor_index,字段表中该属性存储的是字段的数据类型,而在方法表中,这个属性存储的「东西」要稍微多一些,它存储了方法的参数个数,参数类型,返回值等信息。例如我们此示例中,descriptor_index 对应于常量池中的常量:
()V
(0x000C)。
当然,这个方法比较简单,没有参数,返回值类型为 void。我们再看一个稍微复杂点的例子:
public int executeNum(int a,String b,char[] x)
对应的精简版存储形式:
(IL/java/lang/String[C)I
接着就是属性表,显然从我们的字节码表中可以看出来,attributes_count 的值为 1,说明该方法存在一个属性,下面我们来看看属性表有哪些严格的「约束」。
虚拟机规范中定义的属性有很多,并且每种属性都有不同于其他属性的表结构,但是所有的属性都必须包含以下三个项。

通过前两个字节可以辨别当前的属性类型。于我们这里的示例而言,attrubute_name_index 的值为 0x000D(
Code
),所以虚拟机可以调来 Code 表结构继续完成解析,Code 表结构如下:
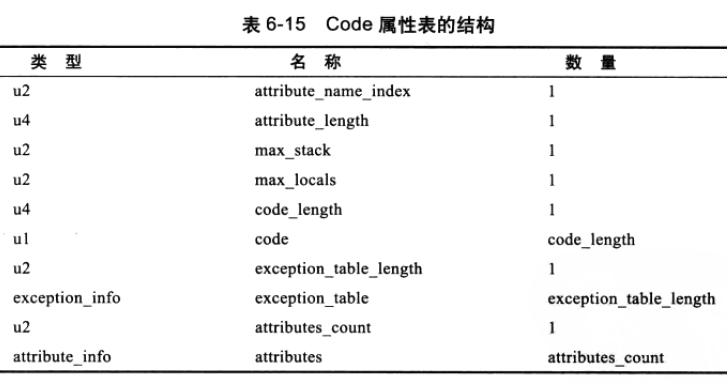
接着分析
,
然后的四个字节表明该属性所占用的总字节数,attribute_length 等于 0x0000003D(61),然后一步一步分析即可,我们这里不再继续分析了。其实 Code 属性表最主要的一个作用是,存储当前方法在编译后所生成的所有字节码指令,并记录所需局部变量表的大小等有关方法运行的信息。
还有一些其他属性表我们这里为了不使篇幅过长,将在后续文章中继续分析。
总体上而言,所谓的字节码文件,或者说 Class 文件就是编译器严格按照虚拟机规范生成的一串二进制,虚拟机在进行解析的时候也是严格按照虚拟机规范进行解析,这样就使得 Class 文件中所有的信息都能够被虚拟机读取解析。
文章中的所有代码、图片、文件都云存储在我的 GitHub 上:
(
https://github.com/SingleYam/overview_java
)
欢迎关注微信公众号:扑在代码上的高尔基,所有文章都将同步在公众号上。
