1.文件读取:fp.read()
| 模式 | 描述 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
>>> fp=open("d:\\test\\a.txt")
#fp=open("d:\\test\\a.txt",encoding="gbk")
#fp=open(r"d:\test\a.txt")
>>> fp_content=fp.read()
>>> fp.close()
>>> fp_content
'第一行\n第二行\n第三行\n\n第五行'
>>> print(fp_content)
第一行
第二行
第三行
第五行-
判断字符编码类型
>>> import chardet
>>> s="好好学习,天天向上".encode("gbk")))
>>> chardet.detect(s)
{'encoding': 'GB2312', 'confidence': 0.99, 'language': 'Chinese'}
>>>
>>>
>>> fp=open("d:\\test\\b.txt","rb")
>>> content=fp.read()
>>> chardet.detect(content)
{'encoding': 'UTF-8-SIG', 'confidence': 1.0, 'language': ''}
>>> fp.close()
2.相对路径打开文件
>>> import os
>>> os.getcwd()
'C:\\Users\\Administrator.DESKTOP-LFNQE7C\\Desktop\\小目标'
>>> os.chdir("d:\\test") #进入目录
>>> os.getcwd() #获取当前目录
'd:\\test'
>>> fp=open("a.txt") #相对路径
3.写入文件
>>> fp=open("aa.txt","w")
>>> fp.write("好好学习")
4
>>> fp.write("\n") #写入换行
1
>>> fp.write("天天向上\n")
5
>>> fp.flush() #写入时有缓存,存8k时候才会写入,此方法将缓存内容写入文件
>>> fp.close()

练习:在文件中写十行
>>> fp=open("aa.txt","w")
>>> for i in range(10):
... l="第%s行\n" % (str(i+1))
... fp.write(l)
...
4
4
4
4
4
4
4
4
4
5
>>> fp.close()
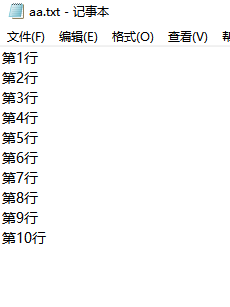
4.读文件
>>> fp=open("aa.txt","r")
>>> fp.read()
'第1行\n第2行\n第3行\n第4行\n第5行\n第6行\n第7行\n第8行\n第9行\n第10行\n'
>>> fp.readlines()
[]
>>> fp.seek(0,0) #指针位置
0
>>> fp.readlines()
['第1行\n', '第2行\n', '第3行\n', '第4行\n', '第5行\n', '第6行\n', '第7行\n', '第8行\n',
'第9行\n', '第10行\n']
>>> fp.seek(0,0)
0
>>> content=fp.readline()
>>> while content: #逐行读的方式1,空字符串为False,退出循环
... print(content)
... content=fp.readline()
...
第1行
第2行
第3行
>>> bool("")
False
>>> for line in fp: #逐行读的方式2
... print(line)
...
第1行
第2行
第3行
>>> fp.seek(0,0)
0
>>> fp.close()- 练习:
fp=open("d:\\test\\aa.txt","r")
#统计一个文件的行
flag=0
for line in fp:
flag+=1
print("文件中有%s行" % flag)
fp.seek(0,0)
flag=0
flag1=0
flag2=0
import string
for line in fp:
if line!="\n":
# 统计文件中不算空行的行数
flag+=1
for i in line:
if i in string.ascii_letters:
# 统计包含英文字母的个数
flag2 += 1
fp.seek(0,0)
import string
for line in fp:
if line!="\n":
for i in line:
if i in string.ascii_letters:
# 统计包含英文字母的行数
flag1 += 1
break
fp.close()
print("文件中不算空行的个数%s" % flag)
print("文件中包含英文有%s行" % flag1)
print("文件中共有英文字母%s个" % flag2)
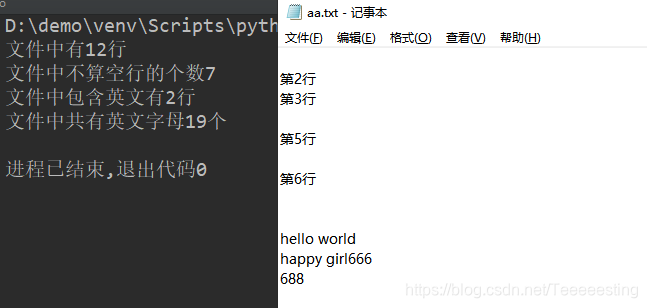
#将文件中所有的包含英文的行去掉
import string
fp=open("d:\\test\\aa.txt","r")
lines=fp.readlines()
fp.close()
fp=open("d:\\test\\aa.txt","w")
for line in lines:
for i in line:
if i in string.ascii_letters:
break
else:
fp.write(line)
fp.close()
版权声明:本文为Teeeeesting原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。