SOPHON SDK对于paddle模型转换的常见问题
静态图保存*.pdmodel和*.pdpot 与*.pdmodel和*.pdiparams的区别?
其主要差别在于保存结果的应用场景:
*.pdmodel,*.pdparams,*.pdopt 三种由save接口保存(2.0的paddle.static.save或者1.8的fluid.io.save)。
*.pdmodel 和 *.pdiparams 由 save_inference_model接口保存(2.0的paddle.static.save_inference_model或者1.8的fluid.io.save_inference_model)
save接口:
该接口用于保存训练过程中的模型和参数,一般包括*.pdmodel,
.pdparams,
.pdopt三个文件。其中*.pdmodel是训练使用的完整模型program描述,区别于推理模型,训练模型program包含完整的网络,包括前向网络,反向网络和优化器,而推理模型program仅包含前向网络,.pdparams是训练网络的参数dict,key为变量名,value为Tensor array数值,.pdopt是训练优化器的参数,结构与*.pdparams一致
save_inference_model接口:
该接口用于保存推理模型和参数,2.0的paddle.static.save_inference_model保存结果为*.pdmodel和*.pdiparams两个文件,其中*.pdmodel为推理使用的模型program描述,.pdiparams为推理用的参数,这里存储格式与.pdparams不同(注意两者后缀差个i),*.pdiparams为二进制Tensor存储格式,不含变量名。1.8的fluid.io.save_inference_model默认保存结果为__model__文件,和以参数名为文件名的多个分散参数文件,格式与2.0一致。
详情请参考:
模型保存与载入-使用文档-PaddlePaddle深度学习平台
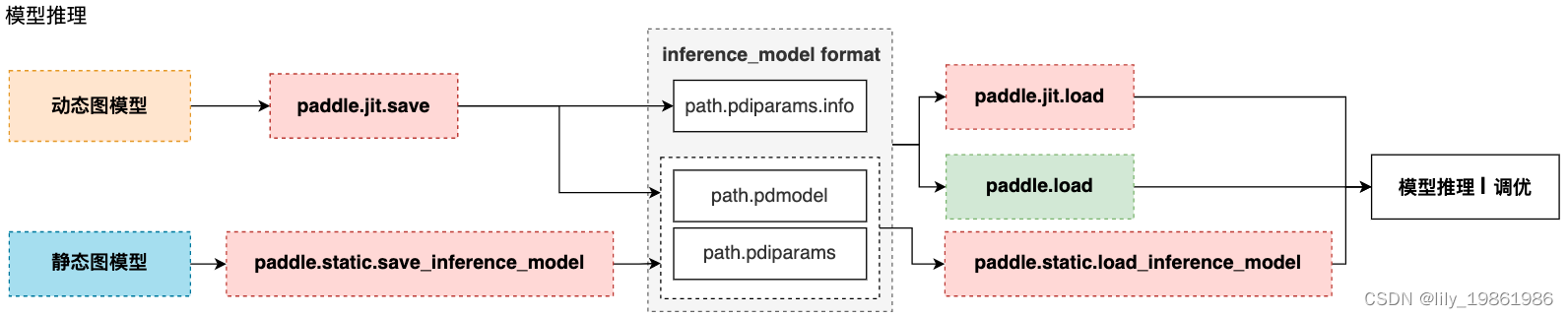
如何生成*.pdmodel和*.pdiparams?
-
动态图存储模型结构和参数 根据训练模式不同,分为两种情况:
动转静训练 + 模型&参数存储:
动转静训练相比直接使用动态图训练具有更好的执行性能,训练完成后,直接将目标Layer传入 paddle.jit.save 存储即可。
动态图训练 + 模型&参数存储:
动态图模式相比动转静模式更加便于调试,如果仍需要使用动态图直接训练,也可以在动态图训练完成后调用paddle.jit.save 直接存储模型和参数。 -
静态图推理模型&参数保存
保存/载入静态图推理模型,可以通过 paddle.static.save/load_inference_model实现。 静态图导出推理模型需要指定导出路径、输入、输出变量以及执行器。save_inference_model 会裁剪Program的冗余部分,并导出两个文件: path_prefix.pdmodel 、path_prefix.pdiparams。
注意事项请参考:
模型保存与载入-使用文档-PaddlePaddle深度学习平台
-
checkpoint(persistable 模型)转换为inference模型保存
在任务的训练阶段,通常我们会保存一些 checkpoint(persistable 模型),这些只是模型权重文件,不能直接被预测引擎直接加载预测,所以我们通常会在训练完之后,找到合适的 checkpoint 并将其转换为 inference 模型。需要构建训练引擎,之后保存 inference 模型即可。 在paddleclas模型库的 tools/export_model.py 中提供了完整的示例,只需执行下述命令即可完成转换:python tools/export_model.py \ --m=模型名称 \ --p=persistable 模型路径 \ --o=model和params保存路径详情请参考:
分类预测框架 — PaddleClas 文档
bmpaddle转换Paddle Paddle模型
BMPADDLE是针对Paddle Paddle的模型编译器,可以将模型文件(inference.pdmodel,inference.pdiparams)编译成 BMRuntime 所需的文件。而且在编译的同时,可选择将每一个操作的NPU模型计算结果和CPU的计算结果进行对比,保证正确性。
命令行格式:
python3 -m bmpaddle [--model=<path>] \
[--input_names=<string>] \
[--shapes=<string>] \
[--descs=<string>] \
[--output_names=<string>] \
[--net_name=<name>] \
[--opt=<value>] \
[--dyn=<bool>] \
[--outdir=<path>] \
[--target=<name>] \
[--cmp=<bool>] \
[--mode=<string>] \
[--enable_profile=<bool>] \
[–list_ops]
python模式:
import bmpaddle
## compile fp32 model
bmpaddle.compile(
model = "/path/to/model(directory)", ## Necessary
outdir = "xxx", ## Necessary
target = "BM1684", ## Necessary
shapes = [[x,x,x,x],[x,x,x]], ## Necessary
net_name = "name", ## Necessary
input_names=["name1","name2"], ## Necessary, when .h5 use None
output_names=["out_name1","out_name2"], ## Necessary, when .h5 use None
opt = 2, ## optional, if not set, default equal to 1
dyn = False, ## optional, if not set, default equal to False
cmp = True, ## optional, if not set, default equal to True
enable_profile = True ## optional, if not set, default equal to False
)
注意:
–model 参数指定到模型所在文件夹那一级,但要特别注意,PaddlePaddle模型有2种:组合式(combined model)和非复合式(uncombined model);组合式就是*model + 权重,__model__文件夹下有很多文件,每一个文件是一层,这种模型必须用
model
;如果是非组合式,一定要把模型名称修改为 *.pdmodel和 *.pdiparams
shapes和descs中的变量顺序、名称要和实际模型一致,不能写错。
对于模型中带nms操作的,并且cmp==true时descs参数必填;对于int32类型,范围不能填重复的值,比如608*608的输入,要填608,609,但生效的就是608;对于float类型,则没有这个限制;对于不填的输入,其取值范围默认都是0-1。
使用bmpaddle转换模型时应该如何填写参数?descs 参数是选填还是必填?
示例:
python3 -m bmpaddle --model=model/ --input_names="image,im_size" --shapes="[1, 3, 608, 608],[1, 2]" --target="BM1684" --cmp=true --descs="[1,int32,608,609]"
注意:
- –-model参数到模型所在文件夹那一级;paddle模型有2种:组合式(combined model)和非复合式(uncombined model);组合式就是__model__ + 权重,__model__文件夹下有很多文件,每一个文件是一层,这种模型名称必须用__model__;如果是非组合式,要用.pdmodel和.pdiparams;
- shapes和descs中的变量顺序、名称要和实际模型一致,不能写错;
- 关于descs 参数是选填还是必填?对于模型中带nms的目标检测网络,并且cmp==true时descs必填,并且对于多输入时的其他输入(比如paddle检测模型中通常都会有的im_size参数),必须写明。对于没有填的输入,默认会产生0-1的随机数,比如输入图像,可以不填;当类型为int32时,不能填重复的值,故写608,609,但生效的就是608;float类型没这个限制;
- paddle-ocr-detection开比对会有误差累计,报错。另外有的模型算子中有很多累加或除法,由于误差累计会导致超出允许的比对误差阈值,转换中断报错;还有的有排序操作,小误差会导致顺序不同。这些都会导致转换中断,可以关闭cmp,不进行数据比对,到业务层面验证转换后模型的精度。