一、操作数据库
1. 登录数据库服务器
mysql -u root -p
若遇到问题:‘mysql’ 不是内部或外部命令,也不是可运行的程序 或批处理文件。将mysql.exe文件所在路径添加到环境变量里
2.查询所有的数据库
show databases;
3.退出数据库服务器
exit;
4.创建、删除数据库
create database 库名; # 创建数据库
drop database 库名; # 删除数据库
二、操作数据表
1.选中某一个数据库进行操作
use 库名;
2.查看所选数据库中所有的数据表
show tables;
3.创建、删除数据表
create table 表名
(
字段1 数据类型,
...
);
drop table 表名; # 删除数据表
4.约束
a.主键约束
(1)单字段主键
通过给某个字段添加约束,该字段的数据唯一且不为空,能够唯一确定一张表中的一条记录
create table user
(
字段1 数据类型 primary key, # 定义列的同时指定主键
...
);
create table user
(
字段1 数据类型, # 定义完所有列后指定主键
...
primary key(字段1)
);
(2)联合主键
只要联合起来不重复即可,但不能为空
create table user
(
字段1 数据类型, # 定义完所有列后指定主键
字段2 数据类型,
...
primary key(字段1, 字段2, ...)
);
(3)忘记创建主键怎么办?
alter table 库名 add primary key(字段1);
(4)删除主键
alter table 库名 drop primary key;
(5)修改主键字段的数据类型
alter table 库名 modify id int primary key;
b.自增约束
create table 表名
(
字段1 数据类型 primary key auto_increment,
字段2 数据类型
);
c.外键约束
外键用来连接两个表一列或者多列的数据。一个表可以有一个或多个外键。外键对应参照完整性,一个表(子表)的外键可以为空值,若不为空值,则每一个外键值必须等于另一个表(父表)中主键的某个值。
注:
①外键首先是本表中的一个字段,可以不是本表的主键,但要对应另一个表的主键,且关联字段的数据类型必须匹配
②定义外键后,不允许删除在另一个表中具有关联性的行
③关联指相关表之间的联系,通过相同的属或属性组来表示。
create table 表1(
字段1 数据类型 primary key,
字段2 数据类型
);
create table 表2(
字段1 数据类型 primary key,
字段2 数据类型,
字段3 数据类型,
[constraint 外键名] foreign key(字段3) references 主表名(表1主键字段1)
);
d.唯一性约束
唯一性约束要求字段的值唯一,允许为空,但只能出现一个空值
(1)语法规则
create table user
(
字段1 数据类型 unique, # 定义列的同时指定唯一约束
...
);
create table user
(
字段1 数据类型, # 定义完所有列后指定唯一约束
...
unique(字段1)
);
(2)忘记创建唯一约束怎么办?
alter table 表名 add unique(字段1);
(3)删除唯一约束
alter table 表名 drop index 字段1;
(4)使用modify添加唯一约束
alter table 表名 modify 字段1 数据类型 unique;
e.非空约束
修饰的字段不能为空NULL
create table 表1(
字段1 数据类型 not null,
字段2 数据类型
);
f.默认约束
当我们插入某字段值时,如果没有赋值,则使用默认值
create table 表名
(
字段1 数据类型,
字段2 数据类型,
字段3 数据类型 default 默认值
);
5.查看数据表结构
a.查看表基本结构
包括字段名、字段数据类型、是否为空,是否为主键,是否有默认值,其他(自增约束)
describe 表名;
b.查看表详细结构
show create table 表名\g; # \g是为了结果更加直观,易于查看
6.查看数据表记录
select * from 表名;
7.往数据表添加数据记录
insert into 表名 values('字段1','字段2'...);
8.添加字段
alter table 表名 add 新字段 字段类型 first; # 在表的第一列添加新字段
alter table 表名 add 新字段 字段类型 after 字段; # 将新字段添加到指定的字段后面
alter table 表名 add 新字段 字段类型 not null; # 添加新字段,且不为空
如果没有first/after,则默认将新字段设置为数据表的最后列
9.修改表名
alter table 旧表名 rename 新表名;
10.修改字段的数据类型
alter table 表名 modify 字段名 新数据类型;
12.修改字段名
alter table 表名 change 旧字段名 新字段名 新数据类型; # 新数据类型不可省
13.删除字段
alter table 表名 drop 字段;
14.修改字段的排列位置
alter table 表名 modify 字段1 字段类型 first; # 将字段1修改为表的第一列
alter table 表名 modify 字段1 字段类型 after 字段2; # 将字段1插入到字段2后面
15.更改表的存储引擎
存储引擎是MySQL中的数据存储在文件或者内存中时采用的不同技术实现
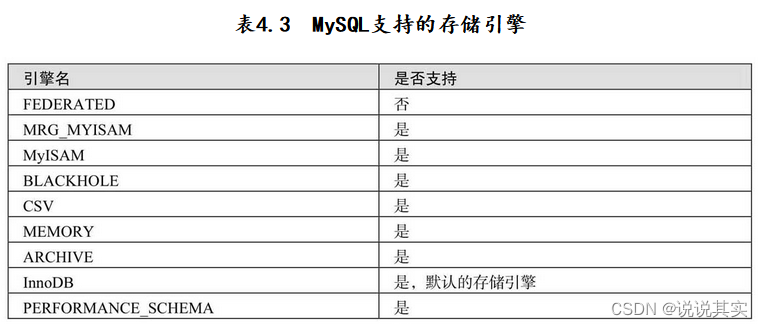
alter table 表名 engine=更改后的存储引擎名;
16.删除表的外键约束
alter table 表名 drop foreign key 外键约束名;
17.删除主表
先删除外键约束,再删除主表
alter table 表名 drop foreign key 外键约束名;
drop table 主表;
18.查看数据库、数据表的默认编码
show variables like 'character_set_databese'; # 查看数据库的默认编码
show create table 表名\G;
12.删改查数据记录
删
delete from 库名 where 字段名=‘字段数据’;
改
update 库名 set 字段名=‘字段数据’ where 字段名=‘字段数据’;
查
select * from 库名 where字段名=‘字段数据’;
13.查看警告
show warnings;
三、MySQL常用数据类型
1.数值
a.整数类型
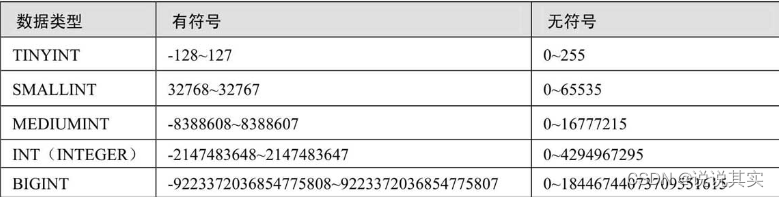
数据类型的显示宽度
id int(11); # 11表示该数据类型指定的显示宽度
# 显示宽度和数据类型的取值范围是无关的。显示宽度只是指明MySQL最大可能显示的数字个数,并不能限制取值范围和占用空间。数值的位数小于指定的宽度时会由空格填充;如果插入了大于显示宽度的值,只要该值不超过该类型整数的取值范围,数值依然可以插入,而且能够显示出来。
create table tmp1( # 每一种类型默认的宽度
x tinyint, # 4
y smallint, # 6
z mediumint, # 9
m int, # 11
n bigint # 20
);
b.浮点数和定点数类型
MySQL中使用浮点数和定点数来表示小数。浮点数类型有两种:单精度浮点类型(FLOAT)和双精度浮点类型(DOUBLE)。定点数类型只有一种:DECIMAL。
浮点数类型和定点数类型都可以用(M,N)来表示
。其中,M称为精度,表示总共的位数;N称为标度,表示小数的位数。
在长度一定的情况下,浮点数能表示更大的数据范围。由于浮点数容易产生误差,因此对精确度要求比较高时,建议使用DECIMAL来存储。另外,两个浮点数进行减法和比较运算时也容易出问题,因此在进行计算的时候,一定要小心。进行数值比较时,最好使用DECIMAL类型。

不论是定点数还是浮点数类型,如果用户指定的精度超出精度范围,则会四舍五入。
create table tmp2(
x float(5, 1),
y double(5,1),
z decimal(5,1)
);
insert into tmp2 values(5.12, 5.15, 5.123); # x和y正常四舍五入,有z字段数值被截断的警告
select * from tmp2; # 5.1 5.2 5.1
2.日期/时间
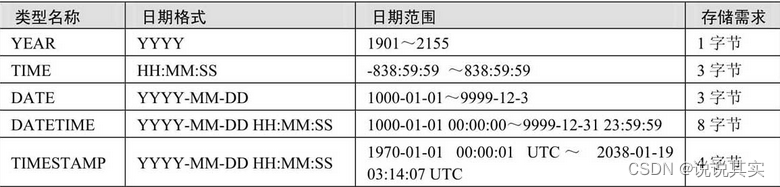
a. YEAR
create table tmp3(y year);
# 以4位字符串或者4位数字格式表示的YEAR,范围为‘1901’~‘2155’
insert into tmp3 values(2010), ('2010'); # 2010 2010
# 以2位字符串格式表示的YEAR,范围为‘00’到‘99’。‘00’~‘69’和‘70’~‘99’范围的值分别被转换为2000~2069和1970~1999范围的YEAR值。‘0’与‘00’的作用相同。插入超过取值范围的值将被转换为2000。
insert into tmp3 values('0'), ('00'), ('77'), ('10'); # 2000 2000 1977 2010
# 以2位数字表示的YEAR,范围为1~99。1~69和70~99范围的值分别被转换为2001~2069和1970~1999范围的YEAR值。注意:在这里0值将被转换为0000,而不是2000。
insert into tmp3 values(0), (78), (11); # 0000 1978 2011
b. TIME
(1)‘D HH:MM:SS’格式
‘HH:MM:SS’、‘HH:MM’、‘D HH:MM’、‘D HH’或‘SS’。这里的D表示日,可以取0~34之间的值。在插入数据库时,D被转换为小时保存,格式为“D*24+HH”。
create table tmp4(t time);
insert into tmp4 values('10:05:05'), ('23:23'), ('2 10:10'), ('3 02'), ('10'); # 10:05:05 23:23:00 58:10:00 74:00:00 00:00:10
insert into tmp4 values(current_time), (now()); # 插入系统当前时间
(2)‘HHMMSS’格式
101112’被理解为‘10:11:12’;不合法时,存储时将变成00:00:00
c. DATE
(1)‘YYYY-MM-DD’或者‘YYYYMMDD’字符串格式
取值范围为‘1000-01-01’~‘9999-12-3’。
(2)YY-MM-DD’或者‘YYMMDD’字符串格式 和 YY-MM-DD或者YYMMDD数字格式
‘00’~‘69’和‘70’~‘99’范围的值分别被转换为2000~2069和1970~1999范围的YEAR值
(3)使用CURRENT_DATE或者NOW(),插入当前系统日期
d. DATETIME
(1)‘YYYY-MM-DD HH:MM:SS’或者‘YYYYMMDDHHMMSS’字符串格式
取值范围为‘1000-01-01 00:00:00’~‘9999-12-323:59:59’
(2)‘YY-MM-DD HH:MM:SS’或者‘YYMMDDHHMMSS’字符串格式
(3)以YYYYMMDDHHMMSS或者YYMMDDHHMMSS数字格式表示的日期和时间
(4)NOW(),插入当前系统日期
e.TIMESTAMP
格式与DATETIME相同,显示宽度固定在19个字符,日期格式为YYYY-MM-DD HH:MM:SS,在存储时需要4字节。TIMESTAMP列的取值范围小于DATETIME的取值范围,为‘1970-01-01 00:00:01’UTC~‘2038-01-1903:14:07’UTC。其中,UTC(Coordinated Universal Time)为世界标准时间,因此在插入数据时,要保证在合法的取值范围内。
3.字符串
MySQL支持两类字符型数据:文本字符串和二进制字符串(比如图片和声音)。文本字符串类型是指CHAR、VARCHAR、TEXT、ENUM和SET。
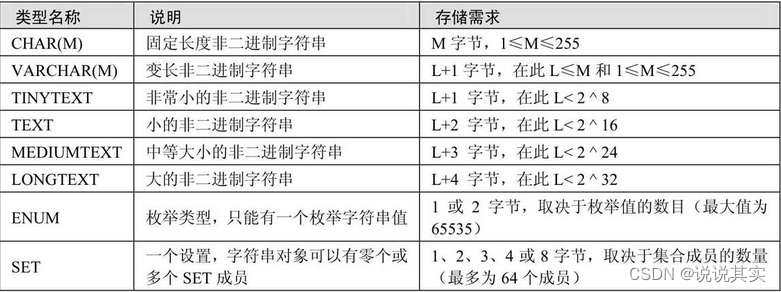
+2 +3 +4个字节是干嘛???
a.文本字符串类型
varchar、text、blob都是变长类型,其实际占用的空间为字符串的实际长度加1( 其中+1是字符串结束字符)
(1)CHAR和VARCHAR类型
CHAR(M)为固定长度字符串,在定义时指定字符串列长。尾部的空格被删除。
VARCHAR(M)是长度可变的字符串,M表示最大列长度。VARCHAR在值保存和检索时尾部的空格仍保留。
CHAR是固定长度,所以它的处理速度比VARCHAR的速度要快,但是它的缺点是浪费存储空间,所以对存储不大但在速度上有要求的可以使用CHAR类型,反之可以使用VARCHAR类型来实现。
(2)TEXT类型
TEXT列保存非二进制字符串,如文章内容、评论等。当保存或查询TEXT列的值时,不删除尾部空格。
(3)ENUM类型
ENUM是一个字符串对象,其值为表创建时在列规定中枚举的一列值。列表值所允许的成员值从1开始编号。枚举最多可以有65535个元素。语法格式如下:
字段名 ENUM(值1','值2',...,'值n')
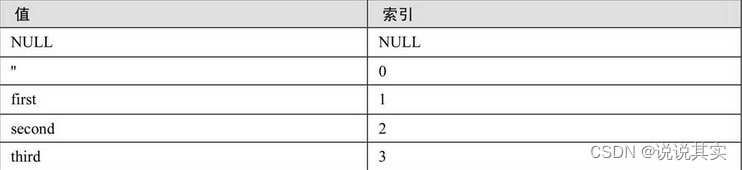
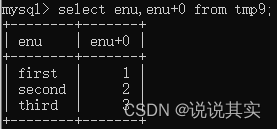
create table tmp9(
enu enum('first', 'second', 'third')
);
insert into tmp9 values('first'), ('second'), ('third');
select enu,enu+0 from tmp9;
注:enum默认值,若enum列声明为null,默认值为null;若声明为not null,默认值为列表第一个元素
(4)SET类型
SET是一个字符串对象,可以有零或多个值。SET列最多可以有64个成员
语法格式如下:
字段名 set(值1','值2',...,'值n')
create table tmp11(
s set('a', 'b', 'c', 'd')
);
insert into tmp11 values ( 'a'),( 'a,b,a'),( 'c,a,d ' ); # a a,b a,c,d 对于SET来说,如果插入的值为重复的,则只取一个,例如插入“a,b,a”,则结果为“a,b”;如果插入了不按顺序排列的值,则自动按顺序插入,例如插入“c,a,d”,结果为“a,c,d”
b.二进制字符串类型

(1)BIT类型
BIT类型是位字段类型。M表示每个值的位数,范围为1~64。如果M被省略,默认为1。如果为BIT(M)列分配的值的长度小于M位,就在值的左边用0填充。
create table tmp12(b bit(4));
insert into tmp12 values(2), (9), (15);
select bin(b+0) from tmp12; # 10 1001 1111 bin()函数将数字转换为二进制
(2)BINARY和VARBINARY类型
BINARY和VARBINARY类型类似于CHAR和VARCHAR,不同的是它们包含二进制字节字符串。
BINARY类型的长度是固定的,指定长度之后,不足最大长度的,将在它们右边填充‘\0’补齐以达到指定长度。VARBINARY类型的长度是可变的,指定好长度之后,其长度可以在0到最大值之间,实际占用的空间为字符串的实际长度加1。
create table tmp13(
b binary(3),
vb varbinary(3)
);
insert into tmp13 values(5, 5);
select length(b), length(vb) from tmp13; # 3 1
(3)BLOB类型 存储图片、音频信息
BLOB是一个二进制大对象,用来存储可变数量的数据。BLOB类型分为4种:TINYBLOB、BLOB、MEDIUMBLOB和LONGBLOB,它们可容纳值的最大长度不同。
BLOB列存储的是二进制字符串(字节字符串),TEXT列存储的是非二进制字符串(字符字符串)。BLOB列没有字符集,并且排序和比较基于列值字节的数值;TEXT列有一个字符集,并且根据字符集对值进行排序和比较。
四、常见运算符
1.算术运算符
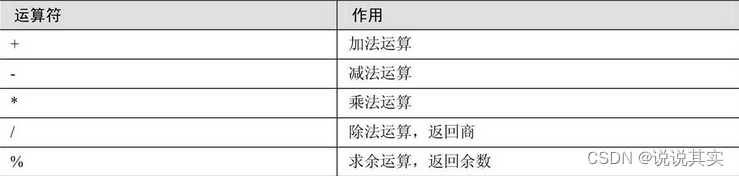
2.比较运算符
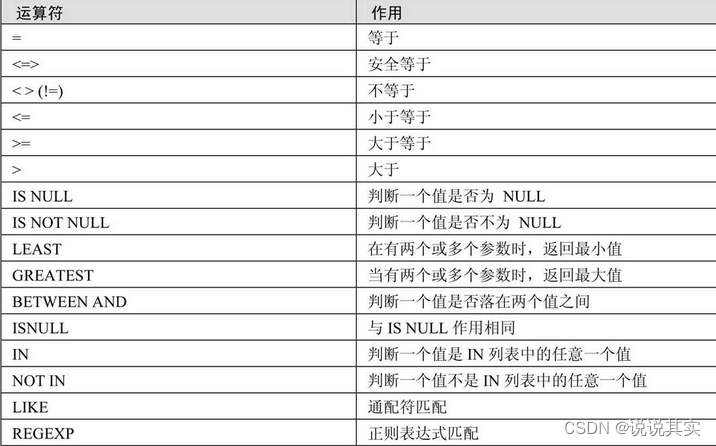
a.=
若有一个或两个参数为NULL,则比较运算的结果为NULL
若用字符串和数字进行相等判断,则MySQL可以自动将字符串转换为数字
b.<=>
两个操作数均为NULL时,其返回值为1
c.BETWEEN AND
语法格式为:
expr BETWEEN min AND max
d.LEAST
语法格式为:LEAST(值1,值2,…,值n)。在有两个或多个参数的情况下,返回最小值。有NULL,则返回NULL。
e.GREATEST
语法格式为:GREATEST(值1,值2,…,值n)。在有两个或多个参数的情况下,返回最大值。有NULL,则返回NULL。、
f.LIKE
LIKE运算符用来匹配字符串,语法格式为:expr LIKE匹配条件。如果expr满足匹配条件,则返回值为1(TRUE);如果不匹配,则返回值为0(FALSE)。expr或匹配条件中任何一个为NULL,则结果为NULL。
LIKE运算符在进行匹配时,可以使用下面的两种通配符:
(1)‘%’,匹配任何数目的字符,甚至包括零字符。
(2)‘_’,只能匹配一个字符。
select 'stud' like '%d', 'stud' like 't____', 'stud' like NULL; # 1 0 NULL
g.REGEXP
用来匹配字符串,语法格式为:expr REGEXP匹配条件。如果expr满足匹配条件,返回1;如果不满足,则返回0。若expr或匹配条件任意一个为NULL,则结果为NULL。REGEXP运算符在进行匹配时,常用的有下面几种通配符:
(1)‘^’匹配以该字符后面的字符开头的字符串。
(2)‘$’匹配以该字符后面的字符结尾的字符串。
(3)‘.’匹配任何一个单字符。
(4)“[…]”匹配在方括号内的任何字符。例如,“[abc]”匹配“a”“b”或“c”。为了命名字符的范围,使用一个‘-’。“[a-z]”匹配任何字母,而“[0-9]”匹配任何数字。
(5)‘
’匹配零个或多个在它前面的字符。例如,“x
”匹配任何数量的‘x’字符,“[0-9]
”匹配任何数量的数字,而“
”匹配任何数量的任何字符。
select 'ssky' REGEXP '^s', 'ssky' REGEXP 'y$', 'ssky' REGEXP '[s]*';
3.逻辑运算符

4.位运算符

5.运算符优先级
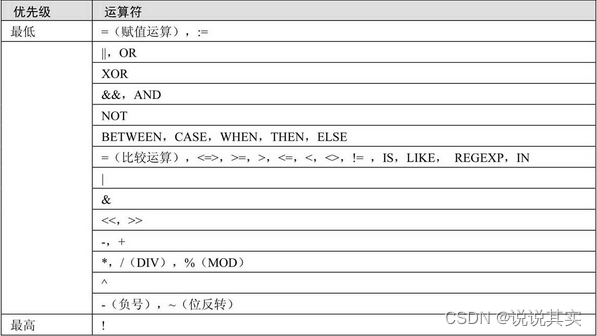
五、MySQL函数
1.数学函数
a.绝对值函数ABS(x)和返回圆周率的函数PI()
PI(),默认的显示小数位数是6位。
b.平方根函数SQRT(x)和求余函数MOD(x,y)
平方根函数SQRT(x),返回非负数x的二次方根
求余函数MOD(x,y),MOD()对于带有小数部分的数值也起作用,它返回除法运算后的精确余数。
c.获取整数的函数CEIL(x)、CEILING(x)和FLOOR(x)
CEIL(x)和CEILING(x)的意义相同,返回不小于x的最小整数值,返回值转化为一个BIGINT。
向上取整
FLOOR(x)返回不大于x的最大整数值,返回值转化为一个BIGINT。
向下取整
d.获取随机数的函数RAND()和RAND(x)
随机数函数RAND(x)返回一个随机浮点值v,范围在0到1之间(0 ≤ v ≤ 1.0)。
随机数函数RAND(x)的参数相同时,将产生相同的随机数,不同的x产生的随机数值不同。
e.函数ROUND(x)、ROUND(x,y)和TRUNCATE(x,y)
ROUND(x)返回最接近于参数x的整数,对x值进行四舍五入。
ROUND(x,y)返回最接近于参数x的数,其值保留到小数点后面y位,若y为负值,则将保留x值到小数点左边y位。 round(232.38, -2)为200
TRUNCATE(x,y)返回被舍去至小数点后y位的数字x。若y的值为0,则结果不带有小数点或不带有小数部分。若y设为负数,则截去(归零)x小数点左起第y位开始后面所有低位的值。
f.符号函数SIGN(x)
符号函数SIGN(x)返回参数的符号,x的值为负、零或正时返回结果依次为-1、0或1。
g.幂运算函数POW(x,y)、POWER(x,y)和EXP(x)
幂运算函数POW(x,y)、POWER(x,y)返回x的y次乘方的结果值。EXP(x)返回e的x乘方后的值。
h.对数运算函数LOG(x)和LOG10(x)
对数运算函数LOG(x)返回x的自然对数,x相对于基数e的对数。LOG10(x)返回x的基数为10的对数。
i.角度与弧度相互转换的函数RADIANS(x)和DEGREES(x)
RADIANS(x)将参数x由角度转化为弧度。DEGREES(x)将参数x由弧度转化为角度。
j.正弦函数SIN(x)和反正弦函数ASIN(x)
正弦函数SIN(x)返回x正弦,其中x为弧度值。反正弦函数ASIN(x)返回x的反正弦,即正弦为x的值。若x不在-1到1的范围之内,则返回NULL。
k.余弦函数COS(x)和反余弦函数ACOS(x)
余弦函数COS(x)返回x的余弦,其中x为弧度值。反余弦函数ACOS(x)返回x的反余弦,即余弦是x的值。若x不在-1~1的范围之内,则返回NULL。
l.正切函数、反正切函数和余切函数
正切函数TAN(x)返回x的正切,其中x为给定的弧度值。反正切函数ATAN(x)返回x的反正切,即正切为x的值。余切函数COT(x)返回x的余切。
注:在有错误产生时,数学函数将会返回空值NULL。
2.字符串函数
a.计算字符串字符数的函数和字符串长度的函数
计算字符串字符数的函数CHAR_LENGTH(str)返回值为字符串str所包含的字符个数。一个多字节字符算作一个单字符。
计算字符串长度的函数ENGTH(str)返回值为字符串的字节长度,使用utf8(UNICODE的一种变长字符编码,又称万国码)编码字符集时,一个汉字是3字节,一个数字或字母算1字节。
b.合并字符串函数CONCAT(s1,s2,…)、CONCAT_WS(x,s1,s2,…)
合并字符串函数CONCAT(s1,s2,…)连接参数产生的字符串,可以有一个或多个参数。有NULL,则返回值为NULL。如果所有参数均为非二进制字符串,则结果为非二进制字符串。如果自变量中含有任一二进制字符串,则结果为一个二进制字符串。
CONCAT_WS(x,s1,s2,…)中,CONCAT_WS代表CONCAT With Separator,是CONCAT()的特殊形式。第一个参数x是其他参数的分隔符,分隔符的位置放在要连接的两个字符串之间。分隔符可以是一个字符串,也可以是其他参数。如果分隔符为NULL,则结果为NULL。
函数会忽略任何分隔符参数后的NULL值。
select contact_ws('*', 'lst', 'null', '3rd'); # lst*3rd
c.替换字符串的函数INSERT(s1,x,len,s2)
替换字符串的函数INSERT(s1,x,len,s2)返回字符串s1,其子字符串起始于s1的x位置,开始长度为len的字符串s2取代。如果x超过字符串长度,则返回值为原始字符串。若任何一个参数为NULL,则返回值为NULL。
d.字母大小写转换函数
LOWER (str)或者LCASE (str)可以将字符串str中的字母字符全部转换成小写字母。
UPPER(str)或者UCASE(str)可以将字符串str中的字母字符全部转换成大写字母。
e.获取指定长度的字符串的函数LEFT(s,n)和RIGHT(s,n)
获取指定长度的字符串的函数:LEFT(s,n)和RIGHT(s,n)LEFT(s,n)返回字符串s开始的最左边n个字符;RIGHT(s,n)返回字符串str最右边的n个字符。
f.填充字符串的函数LPAD(s1,len,s2)和RPAD(s1,len,s2)
填充字符串的函数LPAD(s1,len,s2)返回字符串s1,从左边开始填充字符串s2到len字符长度。假如s1的长度大于len,则返回值被缩短至len字符。
LPAD(s1,len,s2)返回字符串s1,从右边开始填充字符串s2到len字符长度。假如s1的长度大于len,则返回值被缩短至len字符
select lpad('hello', 4, '??'), lpad('hello', 10, '?*'); # hell ?*?*?hello
g.删除空格的函数LTRIM(s)、RTRIM(s)和TRIM(s)
LTRIM(s)返回字符串s,字符串左侧空格字符被删除。
RTRIM(s)返回字符串s,字符串右侧空格字符被删除。
TRIM(s)删除字符串s两侧的空格。
h.删除指定字符串的函数TRIM(s1 FROM s)
TRIM(s1 FROM s)删除字符串s中两端所有的子字符串s1。s1为可选项,在未指定情况下,删除空格。
i.重复生成字符串的函数REPEAT(s,n)
REPEAT(s,n)返回一个由重复的字符串s组成的字符串,字符串s的数目等于n。若n<=0,则返回一个空字符串。若s或n为NULL,则返回NULL。
j.空格函数SPACE(n)和替换函数REPLACE(s,s1,s2)
SPACE(n)返回一个由n个空格组成的字符串。
REPLACE(s,s1,s2)使用字符串s2替代字符串s中所有的字符串s1。
k.比较字符串大小的函数STRCMP(s1,s2)
STRCMP(s1,s2):若所有的字符串均相同,则返回0;若根据当前分类次序,第一个参数小于第二个,则返回-1;其他情况返回1。
l.获取子串的函数SUBSTRING(s,n,len)和MID(s,n,len)
SUBSTRING(s,n,len)从字符串s返回一个长度为len的子字符串,起始于位置n。也可能对n使用一个负值,即倒数第n个字符,而不是字符串的开头位置。
MID(s,n,len)与SUBSTRING(s,n,len)的作用相同。
匹配子串开始位置的函数LOCATE(str1,str)、POSITION(str1 IN str)和INSTR(str, str1)3个函数的作用相同,返回子字符串str1在字符串str中的开始位置。
m.匹配子串开始位置的函数
LOCATE(str1,str)、POSITION(str1 IN str)和INSTR(str, str1)3个函数的作用相同,返回子字符串str1在字符串str中的开始位置。
n.字符串逆序的函数REVERSE(s)
REVERSE(s)将字符串s反转,返回的字符串的顺序和s字符串顺序相反。
o.返回指定位置的字符串的函数
ELT(N,字符串1,字符串2,字符串3,…,字符串N):若N = 1,则返回值为字符串1;若N=2,则返回值为字符串2;以此类推;若N小于1或大于参数的数目,则返回值为NULL。
p.返回指定字符串位置的函数FIELD(s,s1,s2,…,sn)
FIELD(s,s1,s2,…,sn)返回字符串s在列表s1,s2,…,sn中第一次出现的位置,在找不到s的情况下,返回值为0。如果s为NULL,则返回值为0,原因是NULL不能同任何值进行同等比较。
q.返回子串位置的函数FIND_IN_SET(s1,s2)
FIND_IN_SET(s1,s2)返回字符串s1在字符串列表s2中出现的位置,字符串列表是一个由多个逗号‘,’分开的字符串组成的列表。如果s1不在s2或s2为空字符串,则返回值为0。如果任意一个参数为NULL,则返回值为NULL。这个函数在第一个参数包含一个逗号‘,’时将无法正常运行。
select find_in_set('Hi', 'hihi,Hey,Hi,bas'); # 3
r.选取字符串的函数MAKE_SET(x,s1,s2,…,sn)
MAKE_SET(x,s1,s2,…,sn)函数按x的二进制数从s1,s2,…,sn中选取字符串。例如5的二进制是0101,这个二进制从右往左的第1位和第3位是1,所以选取s1和s3。s1,s2,…,sn中的NULL值不会被添加到结果中。
3.日期和时间函数
a.获取当前日期的函数和获取当前时间的函数
CURDATE()和CURRENT_DATE()函数的作用相同,将当前日期按照‘YYYY-MM-DD’或YYYYMMDD格式的值返回,具体格式根据函数在字符串或是数字语境中而定。
“CURDATE()+0”将当前日期值转换为数值型。
CURTIME()和CURRENT_TIME()函数的作用相同,将当前时间以‘HH:MM:SS’或HHMMSS的格式返回,具体格式根据函数在字符串或是数字语境中而定。
“CURTIME()+0”将当前时间值转换为数值型。
b.获取当前日期和时间的函数
CURRENT_TIMESTAMP()、LOCALTIME()、NOW()和SYSDATE() 4个函数的作用相同,均返回当前日期和时间值,格式为‘YYYY-MM-DD HH:MM:SS’或YYYYMMDDHHMMSS,具体格式根据函数在字符串或数字语境中而定。
c.UNIX时间戳函数
UNIX_TIMESTAMP(date)若无参数调用,则返回一个UNIX时间戳(‘1970-01-01 00:00:00’GMT之后的秒数)作为无符号整数。其中,GMT(Green wich mean time)为
格林尼治标准时间
。若用date来调用UNIX_TIMESTAMP(),它会将参数值以‘1970-01-01 00:00:00’GMT后的秒数的形式返回。date可以是一个DATE字符串、DATETIME字符串、TIMESTAMP或一个当地时间的YYMMDD或YYYYMMDD格式的数字。
FROM_UNIXTIME(date)函数把UNIX时间戳转换为普通格式的时间,与UNIX_TIMESTAMP (date)函数互为反函数。
d.返回UTC(世界标准时间)日期的函数和返回UTC时间的函数
UTC_DATE()函数返回当前UTC(世界标准时间)日期值,其格式为‘YYYY-MM-DD’或YYYYMMDD,具体格式取决于函数是否用在字符串或数字语境中。UTC_DATE()函数返回值为当前时区的日期值。
UTC_TIME()返回当前UTC时间值,其格式为‘HH:MM:SS’或HHMMSS,具体格式取决于函数是否用在字符串或数字语境中。UTC_TIME()返回当前时区的时间值。
e.获取月份的函数MONTH(date)和MONTHNAME(date)
MONTH(date)函数返回date对应的月份,范围值为1~12。
MONTHNAME(date)函数返回日期date对应月份的英文全名。
SELECT MONTH(2020-02-13'); # 2
SELECT MONTHNAME('2018-02-13'); # February
f.获取星期的函数DAYNAME(d)、DAYOFWEEK(d)和WEEKDAY(d)
DAYNAME(d)函数返回d对应的工作日的英文名称,例如Sunday、Monday等。
DAYOFWEEK(d)函数返回d对应的一周中的索引(位置,1表示周日,2表示周一,…,7表示周六)。
WEEKDAY(d)返回d对应的工作日索引:0表示周一,1表示周二,…,6表示周日。
g.获取星期数的函数WEEK(d)和WEEKOFYEAR(d)
WEEK(d)计算日期d是一年中的第几周。WEEK()的双参数形式允许指定该星期是否起始于周日或周一,以及返回值的范围是否为0~53或1~53。若Mode参数被省略,则使用default_week_format系统自变量的值(默认为0)
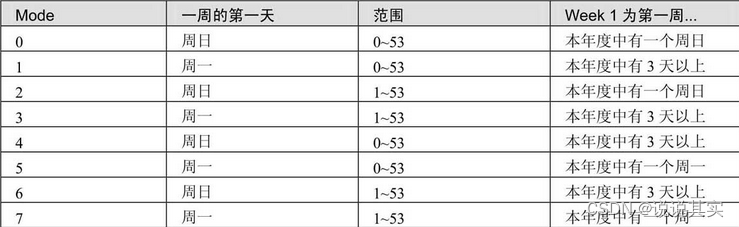
WEEKOFYEAR(d)计算某天位于一年中的第几周,范围是1~53,相当于WEEK(d,3)。
h.获取天数的函数DAYOFYEAR(d)和DAYOFMONTH(d)
DAYOFYEAR(d)函数返回d是一年中的第几天,范围是1~366。
DAYOFMONTH(d)函数返回d是一个月中的第几天,范围是1~31。
i.获取年份、季度、小时、分钟和秒钟的函数
YEAR(date)返回date对应的年份,范围是1970~2069。
QUARTER(date)返回date对应的一年中的季度值,范围是1~4。
MINUTE(time)返回time对应的分钟数,范围是0~59。
SECOND(time)返回time对应的秒数,范围是0~59。
j.获取日期的指定值的函数EXTRACT(type FROM date)
SELECT EXTRACT (YEAR FROM '2018-07-02')AS col1, # 提取年
EXTRACT (YEAR MONTH FROM '2018-07-1201:02:03')AS col2, # 提取年与月
EXTRACT (DAY_MINUTE FROM '2018-07-1201:02:03')AS col3; # 提取日、小时、分钟
k.时间和秒钟转换的函数
TIME_TO_SEC(time)返回已转化为秒的time参数。转换公式为:小时
3600+分钟
60+秒。
SEC_TO_TIME(seconds)返回被转化为小时、分钟和秒数的seconds参数值,其格式为‘HH:MM:SS’或HHMMSS,具体格式根据该函数是否用在字符串或数字语境中而定。
l.计算日期和时间的函数
计算日期和时间的函数有DATE_ADD()、ADDDATE()、DATE_SUB()、SUBDATE()、ADDTIME()、SUBTIME()和DATE_DIFF()。
DATE_ADD(date,INTERVAL expr type),date是一个DATETIME或DATE值,用来指定起始时间。expr是一个表达式,用来指定从起始日期添加或减去的时间间隔值。对于负值的时间间隔,expr可以以一个负号‘-’开头。type为关键词,指示了表达式被解释的方式。
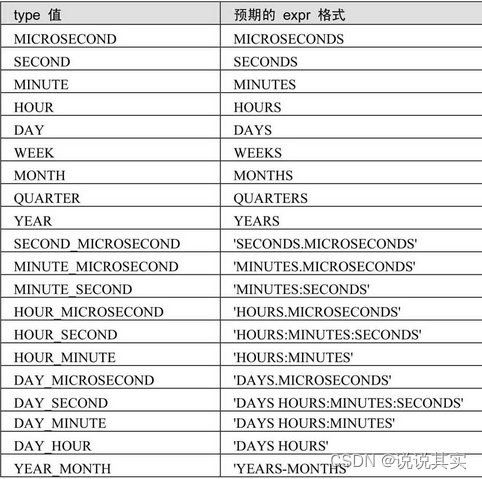
DATE_ADD(date,INTERVAL expr type)和ADDDATE(date,INTERVAL expr type)两个函数的作用相同,执行日期的加运算。
select DATE_ADD('2010-12-31 23:59:59', INTERVAL 1 SECOND), # 将时间增加1秒后返回,结果都为‘2011-01-0100:00:00’
DATE_ADD('2010-12-31 23:59:59', INTERVAL '1:1'MINUTE_SECOND); # 将指定时间增加1分1秒后返回,结果为‘2011-01-01 00:01:00’
DATE_SUB(date,INTERVAL expr type)或者SUBDATE(date,INTERVAL exprtype)两个函数的作用相同,执行日期的减运算。
select DATE_SUB('2011-01-02', INTERVAL 31 DAY), # 将日期值减少31天后返回,结果都为“2010-12-02”
DATE_SUB('2011-01-0100:01:00',INTERVAL '0 0:1:1' DAY_SECOND); # 函数将指定日期减少1天,时间减少1分1秒后返回,结果为“2010-12-31 23:59:59”
ADDTIME(date,expr)函数将expr值添加到date,并返回修改后的值,date是一个日期或者日期时间表达式,而expr是一个时间表达式。
SELECT ADDTIME('2000-12-31 23:59:59','1:1:1'); # 将“2000-12-31 23:59:59”的时间部分值增加1小时1分钟1秒后的日期变为“2001-01-01 01:01:00”
SUBTIME(date,expr)函数将date减去expr值,并返回修改后的值。其中,date是一个日期或者日期时间表达式,而expr是一个时间表达式。
DATEDIFF(date1,date2)返回起始时间date1和结束时间date2之间的天数。date1和date2为日期或日期时间表达式。计算中只用到这些值的日期部分。
SELECT DATEDIFF('2010-12-31 23:59:59','2010-12-30'); # 1
m.将日期和时间格式化的函数
DATE_FORMAT(date,format)根据format指定的格式显示date值

SELECT DATE_FORMAT ( '1997-10-04 22:23:00','%w %M %Y')AS col1,DATE_FORMAT ( '1997-10-04 22:23:00', '$D %y %a %d %m %b %j')AS col2; # Saturday 0ctober 1997 ; 4th 97 Sat 04 10 0ct 277
TIME_FORMAT(time,format)根据表达式format的要求显示时间time。表达式format指定了显示的格式。因为TIME_FORMAT(time,format)只处理时间,所以format只使用时间格式。
GET_FORMAT(val_type, format_type)返回日期时间字符串的显示格式,val_type表示日期数据类型,包括DATE、DATETIME和TIME;format_type表示格式化显示类型,包括EUR、INTERVAL、ISO、JIS、USA。
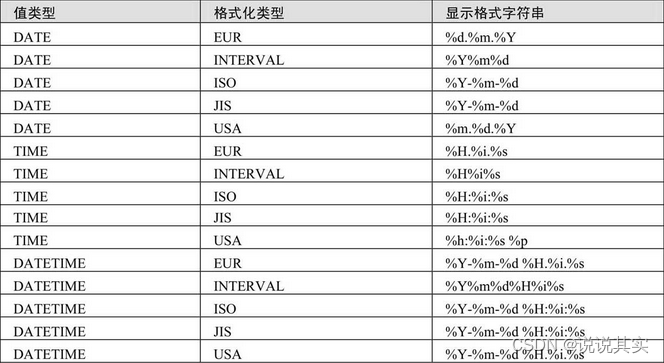
4.条件判断函数
5.系统信息函数和加密函数
二、数据表设计
1.第一范式1NF
每一字段都不可再分
2.第二范式2NF
满足1NF的前提下,除主键外的的每一列都必须完全依赖于主键
若不完全依赖,只可能发生在联合主键的情况下
create table myorder(
product_name varchar(20),
customer_name varchar(20),
primary key(product_id,customer_id)
);
本例子中product_name只依赖product_id;customer_name只依赖customer_id;需要拆表
create table myorder(
order_id int primary key,
product_id int,
customer_id int
);
create table product(
id int primary key,
name varchar(20)
);
create table customer(
id int primary key,
name varchar(20)
);
3.第三范式3NF
满足2NF的前提下,除主键列的其他列间不能有传递依赖关系
create table myorder(
order_id int primary key,
product_id int,
customer_id int,
customer_phone varchar(15)
);
本例子中存在customer_phone依赖于customer_id,customer_id又依赖于order_id,需要拆表
create table myorder(
order_id int primary key,
product_id int,
customer_id int
);
create table customer(
id int primary key,
name varchar(20),
phone varchar(20)
);
三、查询练习
1.数据准备
学生表Student
学号
姓名
性别
出生年月日
所在班级
create table student(
sno varchar(20) primary key,
sname varchar(20) not null,
ssex varchar(10) not null,
sbirthday datetime,
class varchar(20)
);
insert into student values(‘101’,‘曾华’,‘男’,‘1977-09-01’,‘95033’);
insert into student values(‘102’,‘匡明’,‘男’,‘1975-10-02’,‘95031’);
insert into student values(‘103’,‘王丽’,‘女’,‘1976-01-23’,‘95033’);
insert into student values(‘104’,‘李军’,‘男’,‘1976-02-20’,‘95033’);
insert into student values(‘105’,‘王芳’,‘女’,‘1975-02-10’,‘95031’);
insert into student values(‘106’,‘陆君’,‘男’,‘1974-06-03’,‘95031’);
insert into student values(‘107’,‘张三’,‘男’,‘1977-03-23’,‘95032’);
insert into student values(‘108’,‘李四’,‘男’,‘1976-07-19’,‘95032’);
insert into student values(‘109’,‘王五’,‘男’,‘1977-08-21’,‘95033’);
教师表Teacher
教师编号
教师名字
教师性别
出生年月日
职称
所在部门
create table teacher(
tno varchar(20) primary key,
tname varchar(20) not null,
tsex varchar(10) not null,
tbirthday datetime,
prof varchar(20) not null,
depart varchar(20) not null
);
insert into teacher values(‘804’,‘李诚’,‘男’,‘1958-12-02’,‘副教授’,‘计算机系’);
insert into teacher values(‘856’,‘张旭’,‘男’,‘1969-03-12’,‘讲师’,‘电子工程系’);
insert into teacher values(‘825’,‘王萍’,‘女’,‘1972-05-05’,‘助教’,‘计算机系’);
insert into teacher values(‘831’,‘刘冰’,‘女’,‘1977-08-14’,‘助教’,‘电子工程系’);
课程表Course
课程号
课程名称
教师编号
create table course(
cno varchar(20) primary key,
cname varchar(20) not null,
tno varchar(20) not null,
foreign key(tno) references teacher(tno)
);
insert into course values(‘3-105’,‘计算机导论’,‘825’);
insert into course values(‘3-245’,‘操作系统’,‘804’);
insert into course values(‘6-166’,‘数字电路’,‘856’);
insert into course values(‘9-888’,‘高等数学’,‘831’);
成绩表Score
学号
课程号
成绩
create table score(
sno varchar(20) not null,
cno varchar(20) not null,
degree decimal,
foreign key(sno) references student(sno),
foreign key(cno) references course(cno),
primary key(sno,cno)
);
insert into score values(‘103’,‘3-105’,‘92’);
insert into score values(‘103’,‘3-245’,‘86’);
insert into score values(‘103’,‘6-166’,‘85’);
insert into score values(‘105’,‘3-105’,‘88’);
insert into score values(‘105’,‘3-245’,‘75’);
insert into score values(‘105’,‘6-166’,‘79’);
insert into score values(‘109’,‘3-105’,‘76’);
insert into score values(‘109’,‘3-245’,‘68’);
insert into score values(‘109’,‘6-166’,‘81’);
2.查询student表的所有记录
select * from student;

3.查询student表所有记录的sname、ssex、class字段(列)
select sname,ssex,class from student;

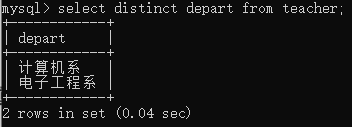
4.查询教师所在部门字段不重复的depart列
select distinct depart from teacher;
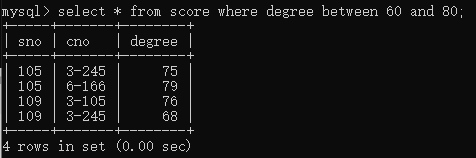
5.查询score表中成绩在60-80之间的所有记录
between…and…:select * from score where degree between 60 and 80;
或者
运算符比较:select * from score where degree>60 and degree<80;
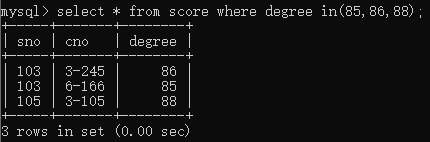
6.查询score表中成绩为86、86或88的所有记录
select * from score where degree in(85,86,88);
7.查询student表“95031”班或者性别为“女”的同学
select * from student where class=‘95031’ or ssex=‘女’;
8.以class降序查询student表的所有记录
select * from student order by class desc;
升序为asc(默认),降序为desc

9.以cno升序、成绩降序查询score表的所有记录
select * from score order by cno asc,degree desc;

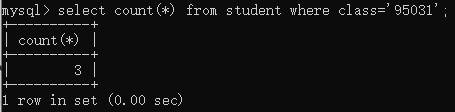
10.查询“95031”班的学生人数
select count(*) from student where class=‘95031’;
11.查询score表中的最高分的学生学号和课程号(子查询或排序)
①子查询
select sno,cno from score where degree=(select max(degree) from score);

②排序:存在一定缺陷
select sno,cno,degree from score order by degree desc limit 0,1;
12.查询每门课的平均成绩
①
select avg(degree) from score where cno=‘3-105’;
select avg(degree) from score where cno=‘3-245’;
select avg(degree) from score where cno=‘6-166’;
select avg(degree) from score where cno=‘9-888’;
②group by分组
select cno,avg(degree) from score group by cno;

13.查询score表中至少有2名学生选修的并以3开头的的课程的平均分数
分组条件与模糊查询
select cno,avg(degree),count(*) from score group by cno having count(cno)>=2 and cno like ‘3%’;

14.查询分数大于70,小于90的sno列
①select sno,degree from score where degree>70 and degree<90;
②select sno,degree from score where degree between 70 and 90;
15.两表查询所有学生的sname、cno、degree列
select sname,cno,degree from student,score where student.sno=score.sno;
16.两表查询所有学生的sno、cname、degree列
select sno,cname,degree from score,course where course.cno=score.cno;
17.三表查询所有学生的sname、cname、degree列
select sname,cname,degree from student,course,score where student.sno=score.sno and course.cno=score.cno;
18.查询“95031”班学生每门课的平均分
子查询+分组
select cno,avg(degree) from score where sno in (select sno from student where class=‘95031’) group by cno;
19.查询成绩选修课程“3-105”并且高于学号“109”,并且选修课程“3-105”的所有同学的记录
子查询
select * from score where cno=‘3-105’ and degree>(select degree from score where sno=‘109’ and cno=‘3-105’);
20.查询成绩高于学号“109”、课程号为“3-105”的成绩的所有记录
子查询
select * from score where degree>(select degree from score where sno=‘109’ and cno=‘3-105’);
21.查询与学号为108、101的同学同年同月出生的所有学生的sno、sname、sbirthday列
year函数和带in关键字的子查询
select sno,sname,sbirthday from student where year(sbirthday) in (select year(sbirthday) from student where sno in(108,101));
22.查询“张旭”教师任课的学生成绩
多层嵌套子查询
select * from score where cno=(select cno from course where tno=(select tno from teacher where tname=‘张旭’));
23.查询选修某课程大于5个学生的教师姓名
select tname from teacher where tno=(select tno from course where cno=(select cno from score group by cno having count(*)>3));
24.查询95033班和95031班全体学生的记录
in表示“或者”关系
select * from student where class in(‘95031’,‘95033’);
25.查询有85分以上的成绩的课程
select cno,degree from score where degree>85;
26.查询“计算机系”教师所教课程的成绩表
select * from score where cno in(select cno from course where tno in (select tno from teacher where depart=‘计算机系’));
27.查询“计算机系”与“电子工程系”不同职称的教师的tname和prof
union求并集
select * from teacher where depart=‘计算机系’ and prof not in(select prof from teacher where depart=‘电子工程系’) union select * from teacher where depart=‘电子工程系’ and prof not in(select prof from teacher where depart=‘计算机系’);

28.查询选修编号为“3-105”课程且成绩至少高于选修编号“3-245”的同学的cno、sno和degree,并按degree从高到低排序
any表示至少一个
select * from score where cno=‘3-105’ and degree>any(select degree from score where cno=‘3-245’) order by degree desc;
29.查询选修编号为“3-105”课程且成绩高于选修编号“3-245”的同学的cno、sno和degree
all表示所有
select * from score where cno=‘3-105’ and degree>all(select degree from score where cno=‘3-245’) ;
30.查询所有教师和同学的name、sex和birthday
select tname as name,tsex as sex,tbirthday as birthday from teacher
union
select sname,ssex,sbirthday from student;
31.查询所有“女”教师和“女”同学的name,sex和birthday
select tname as name,tsex as sex,tbirthday as birthday from teacher where tsex=‘女’
union
select sname,ssex,sbirthday from student where ssex=‘女’;
32.查询成绩比该课程平均成绩低的同学的成绩表
复制表数据做条件查询
select * from score a where degree<(select avg(degree) from score b where a.cno=b.cno);
33.查询所有任课教师的tname和depart
select tname,depart from teacher where tno in(select tno from course);
34.查询至少有两名男生的班号
条件+分组筛选
select class from student where ssex=‘男’ group by class having count(*)>2;
35.查询student表中不姓“王”的同学记录
not like模糊查询取反
select * from student where sname not like ‘王%’;
36.查询student表中每个学生的姓名和年龄
year函数和now函数
select sname,year(now())-year(sbirthday) as ‘年龄’ from student;
37.查询student表中最大和最小的sbirthday日期
max和min函数
select max(sbirthday) as ‘最大’,min(sbirthday) as ‘最小’ from student;
38.以班号和年龄从大到小的顺序查询student表中的全部记录
多字段查询
select * from student order by class desc,sbirthday;
39.查询男教师及其所上课程
select * from course where tno in(select tno from teacher where tsex=‘男’);
40.查询最高分同学的sno、cno和degree列
select * from score where degree=(select max(degree) from score);
41.查询和“李军”同性别的所有同学的sname
select sname from student where ssex=(select ssex from student where sname=‘李军’);
42.查询和“李军”同性别并同班的同学sname
select sname from student where ssex=(select ssex from student where sname=‘李军’) and class=(select class from student where sname=‘李军’);
43.查询所有选修“计算机导论”课程的“男”同学的成绩表
select * from score where cno=(select cno from course where cname=‘计算机导论’) and sno in (select sno from student where ssex=‘男’);
44.查所有同学的sno、cno和grade列按等级查询
按等级查询
create table grade(low int(3),upp int(3),grade char(1));
insert into grade values(90,100,‘A’);
insert into grade values(80,89,‘B’);
insert into grade values(70,79,‘C’);
insert into grade values(60,69,‘D’);
insert into grade values(0,59,‘E’);
select sno,cno,grade from score,grade where degree between low and upp;
四、连接查询
create database testjoin;
create table person(id int,name varchar(20),cardId int);
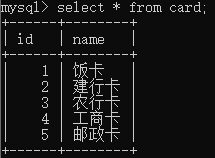
create table card(id int,name varchar(20));
insert into card values(1,‘饭卡’);
insert into card values(2,‘建行卡’);
insert into card values(3,‘农行卡’);
insert into card values(4,‘工商卡’);
insert into card values(5,‘邮政卡’);
insert into person values(1,‘张三’,1);
insert into person values(2,‘李四’,3);
insert into person values(3,‘王五’,6);

1.内连接inner join
两张表中的数据通过某个字段相等,查询出相关记录
select * from person inner join card on person.cardId=card.id;

2.外连接
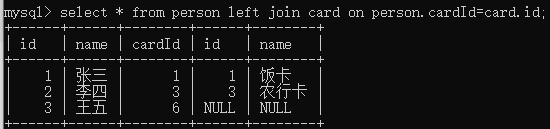
①左连接left join 或者left outer join
把左表的所有数据取出来;右边表的数据,如果有相等的就显示出来,如果没有就会补NULL
select * from person left join card on person.cardId=card.id;
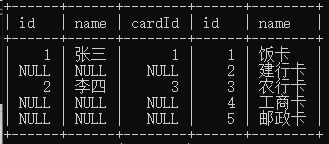
②右连接right join 或者right outer join
把右表的所有数据取出来;左边表的数据,如果有相等的就显示出来,如果没有就会补NULL
select * from person right join card on person.cardId=card.id;
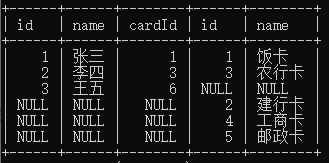
③完全外连接 full join或者full outer join
MySql不支持
select * from person left join card on person.cardId=card.id union select * from person right join card on person.cardId=card.id;
五、事务
1.定义
事务是一个最小的不可分割的工作单元,事务能保证一个业务的完整性。
多条sql语句要么同时成功,要么同时失败。
事务提供给我们一个返回的机会
2.控制事务
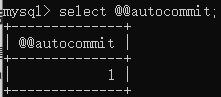
①自动提交:@@autocommit=1
MySql默认是开启事务的,作用是执行一个sql语句的时候效果会立即体现出来,且不能
回滚
(撤销sql语句)。
select @@autocommit;
create database bank;
create table user(id int primary key,name varchar(20),money int);
insert into user values(1,‘a’,1000);
rollback;此时撤销sql语句执行效果没有反应
可以设置mysql自动提交为false,即关闭了mysql的自动提交(commit)
set autocommit=0;
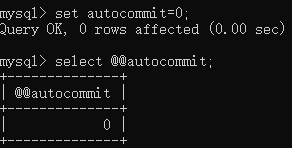
insert into user values(2,‘b’,1000);
rollback;此时撤销sql语句执行效果有反应
②手动提交:commit
再次插入数据
insert into user values(2,‘b’,1000);
手动提交
commit;
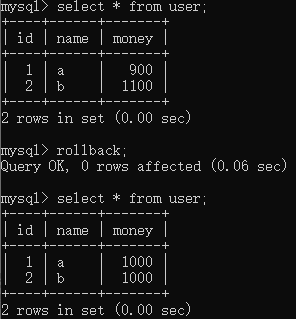
再撤销是不可以的
rollback;
update user set money=money-100 where name=‘a’;
update user set money=money+100 where name=‘b’;
3.手动控制事务
begin或者start transaction都可以帮我们手动开启一个事务
①begin
update user set money=money-100 where name=‘a’;
update user set money=money+100 where name=‘b’;
可以回滚
②start transaction
update user set money=money-100 where name=‘a’;
update user set money=money+100 where name=‘b’;
可以回滚
③想提交可以commit
4.事务的四大特征
A 原子性:事务是最小的单位,不可再分割
C 一致性;事务要求,同一事务中的sql语句,必须保证同时成功或者同时失败
I 隔离性:事务a和事务b执行具有隔离性
D 持久性:事务一旦结束(提交commit或者回滚rollback),就不可以反悔
5.事务的隔离性
隔离级别越高,性能越差,serializable性能特差
①read uncommitted; 读未提交的
事务a和事务b,a事务对数据进行操作,在操作过程中事务没有被提交,但是b事务读到了a事务没有提交的数据,这种情况会出现“脏读”情况
insert into user values(5,‘小红’,1000);
insert into user values(6,‘天猫店’,1000);
小红转给天猫店800元
start transaction;手动开启事务
update user set money=money-800 where name=‘小红’;
update user set money=money+800 where name=‘天猫店’;
如何查看数据库的隔离级别?
8.0:select @@global.transaction_isolation;系统级别
select @@transaction_isolation;会话级别
5.x:select @@global.tx_isolation;系统级别
select @@tx_isolation;会话级别
如何修改隔离级别?
set global transaction isolation level read uncommitted;
②read committed; 读已提交的
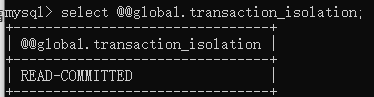
set global transaction isolation level read committed;修改隔离级别
select @@global.transaction_isolation;查看隔离级别
这种情况会出现“不可重复读”情况:第一个人查询完user表后,第二个人往user表中插入新的数据项,第一个人再求数据的平均值会出现问题
③repeatable read; 可以重复读
set global transaction isolation level repeatable read;修改隔离级别
select @@global.transaction_isolation;查看隔离级别
事务a和事务b同时操作一张表,事务a提交的数据,不能被数据b读到,就会出问题,这种现象叫做“幻读”。
④serializable; 串行化
set global transaction isolation level serializable;修改隔离级别
select @@global.transaction_isolation;查看隔离级别
事务a和事务b,事务a提交数据后,事务b查看表,事务a再插入数据就会卡住,进入排队状态(串行化),直到事务b结束事务之后,事务a才可继续(在没有等待超时的情况下)