计算机系统结构 第四章:数据级并行:向量体系结构和GPU
本章知识结构图:
什么是数据级并行
数据级并行通常用于大规模数据处理的场景,比如:科学计算、图形图像处理。
数据级并行与SPMD
-
无论是矩阵运算还是图形图像处理,其共性是
对大量的数据施加同种变换
——数据级并行(DLP) - 从软件的角度,在编程模型上,我们期待SPMD:从软件的角度上来讲,用单个程序,可以处理不同的数据。
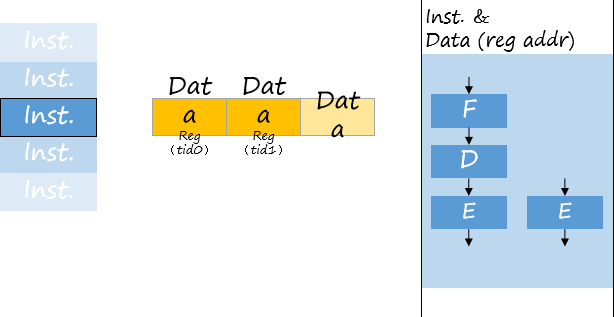
那么把一个SPMD的程序分别放在SISD的机器上,以及MIMD的机器上,会怎么样?
-
在SISD上,和我们之前见过的指令流水线一样,以流水线的方式完成指令级的并行, F(取指令)、D(译码读寄存器)、E(执行)……(单核,单线程,串行化执行:把MD拆成多次SD,变为SISD)
耗时
-
在MIMD上,每个core都在执行指令流,也就是多个指令流水线在多个core上同时进行 F、D、E……等。(多核,多线程,并行化执行:把SP的每条I多次重复,变为MIMD)
耗电
数据级并行——传统器件的问题
- 分析传统的标量CPU流水线可知,取址、译码等操作逻辑复杂,且开销不低;
- 对于SPMD任务,无论是在SISD还是MIMD(多核)器件上运行,其取址、译码操作都是有冗余的。
数据级并行——SIMD
SIMD器件:更多的ALU (Execute);更少的Fetch和Decode
- 更少的Fetch和Decode(甚至其他流水部件)意味着什么?——更少的器件,更低的能耗和时间开销
- 更多的ALU意味着什么?——一次流水能处理更多数据,速度更快
- 增加数据寄存器的数量来一次存储更多数据,以减少存储器访问延迟
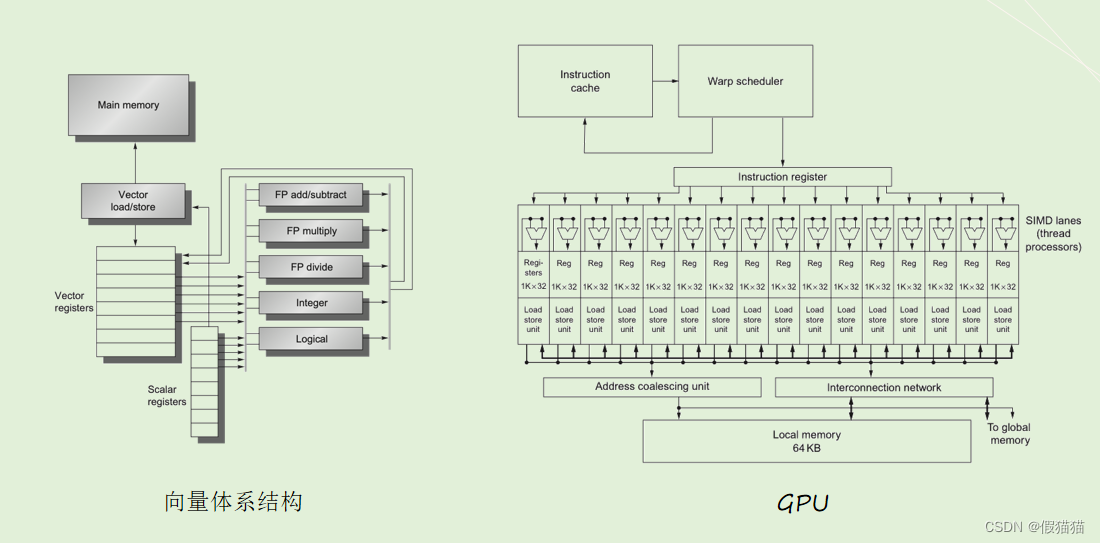
向量体系结构与GPU系统结构的差别
向量体系结构——“窄而深”
- 指令流水线深,ALU宽度窄
- 单次指令流水后能处理更多数据,掩盖不必要的流水线时间
GPU——“宽而浅”
- 指令流水线浅,ALU宽度宽
- 流水本身比较简单,直接对更多的数据进行并行计算,同一时刻处理更多数据
向量体系结构
向量这种数据结构,以及向量的运算,和我们对SIMD的期待不谋而合。
向量的串行化计算方式
以计算 D=A×(B+C) 为例,A、B、C、D均为长度为N的向量
- 横向计算
- 纵向计算
- 纵横(分组)计算
向量的计算方式 – 1. 横向计算
-
向量计算是按行的方式从左到右横向地进行
先计算: d1←a1×(b1+c1)
再计算: d2←a2×(b2+c2)
……
最后计算: dN←aN×(bN+cN) -
组成循环程序进行处理
ki←bi+ci
di←ki×ai
数据相关:N 次 功能切换:2N 次 - 这种计算方式是在标量处理器上对向量的一般计算方式,数据相关和功能切换随着向量长度增长而增长,硬件开销过大,并不是最优的向量计算方式,不适合于向量处理机的并行处理。
向量的计算方式 – 2. 纵向计算
- 向量计算是按列的方式从上到下纵向地进行。
-
先计算
k1←b1+c1
……
kN←bN+cN
再计算
d1←k1×a1
……
dN←kN×aN -
表示成向量指令:
K=B+C
D=K × A
两条向量指令之间:
数据相关:1次 功能切换:1次
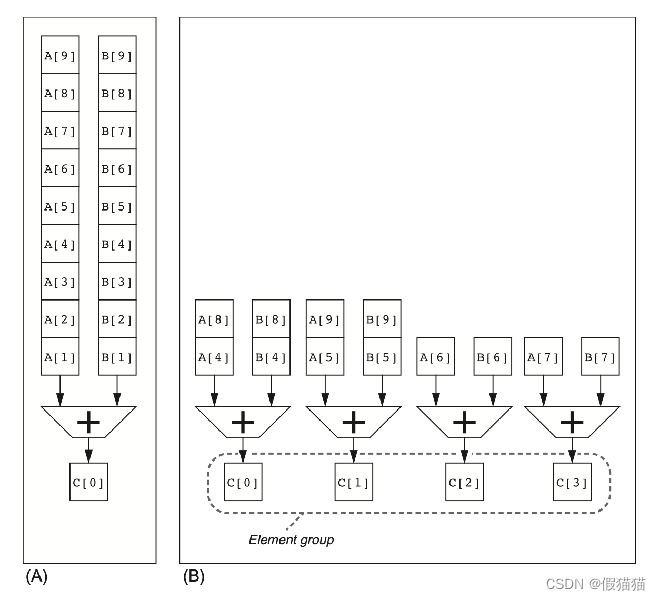
向量的计算方式 – 3. 纵横(分组)计算
-
刚刚的纵向计算方式优化了向量计算的硬件开销,但是每次计算都需要访问到向量中的全部元素;
-
考虑到当前计算机体系结构的存储结构往往是层次化的,指令操作数一般都会加载到寄存器中,而寄存器的数量一般不会太多(相比于可以无限增长的向量长度N来说);
-
结合前面两种计算方式,我们可以使用分组计算的方法。
-
把向量分成若干组,组内按纵向方式处理,依次处理各组。
-
对于上述的例子,设:
N=S × n+r
其中N为向量长度,S为组数,n为每组的长度,r为余数。
若余下的r个数也作为一组处理,则共有S+1组。 -
先算第1组:
k1~n←b1~n+c1~n
d1~n←k1~n×a1~n -
再算第2组:
k(n+1)~2n←b(n+1)~2n+c(n+1)~2n
d(n+1)~2n←k(n+1)~2n×a(n+1)~2n -
依次进行下去,直到最后一组:第S+1组。
-
每组内各用两条向量指令。
数据相关:1次 功能切换:2次
向量体系结构的总结
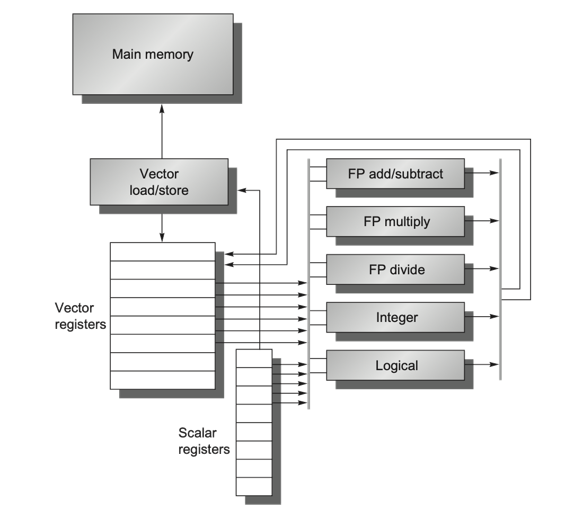
- 根据刚刚探讨的串行化向量计算优化方式,我们得到一种更适用于向量处理的体系结构
- 向量体系结构应当具有很大的顺序寄存器堆 (Register File),可加载更多向量元素以支持纵向计算
- 向量体系结构从内存中收集散落的数据,将其放入寄存器堆中,并对寄存器堆中的数据们进行操作,然后将这些结果放回内存(一次传输一组数据,LD/ST流水化)
- 一条指令能够对一个向量的数据进行操作,也就对向量中诸多独立数据元素进行了操作(纵向计算,功能单元流水化)
向量体系结构的一些优势
- 由于向量的Load与Store是深度流水线化的,大型寄存器堆充当了Buffer的作用,因此其能够掩盖访存延迟并充分利用内存带宽;
- 乱序的超标量处理器往往具有复杂的设计,且乱序程度越高,其复杂性和功耗也会越高,在此方向发展很容易触及Power Wall;
- 将顺序的标量处理器扩展为向量处理器则不会带来复杂度和功耗的大幅升高,且开发者也能很容易适应和转换到向量指令。
实例:VMIPS=标量MIPS+逻辑向量扩展
-
向量寄存器:
- 64bit * 64元素 * 8个VR,足够多读写口
-
向量功能单元:
- 全流水化,每周期1操作
- 需要一个控制单元检测结构冒险和数据冒险
-
向量load/store单元:
- 全流水化,每周期1个字,可操作标量
-
标量寄存器集合:
- 32通用,32浮点,可存地址和数据
- 可以为向量功能单元提供数据,也可以为向量load/store单元提供地址
向量专用特殊寄存器
-
向量长度寄存器VL
- 64位,每一位对应于向量寄存器的一个单元
- VL控制所有向量运算的长度,包括ld/st
- 作用:将软件层程序中实际向量长度N与硬件层向量寄存器中的元素数目64相适配
-
向量屏蔽寄存器VM
- 当向量长度小于64时,或者条件语句控制下对向量某些元素进行单独运算时使用
- 即使maskcode中有大量的0,使用VM的向量指令速度依然远远快于标量计算模式
Vmips向量指令格式
VMIPS指令=MIPS指令+Op1类型+Op2类型.精度
- misp:add.d
- vmips:addvv.d(V1,V2,V3),addvs.d(V1,V2,F0)
向量体系结构的相关概念
- 循环间相关:对一个循环来说,如果各轮迭代之间存在相关性,则称为循环间相关,否则为循环间无关
- 可向量化:针对一组Mips指令描述的循环,如果满足循环间无关,则循环称为可向量化的,编译器可为其生成向量指令。
- 指令编队(convoy):由一组不包含结构冒险的向量指令组成,一个编队中的所有向量指令在硬件条件允许时可以并行执行。
向量体系结构的性能优化
多车道技术
- 刚刚讨论的是向量计算在串行化中尽可能进行优化的结果
- 从并行的角度去考虑,增加功能单元(ALU)的数量也能大大提升向量的计算速度(多车道)
- 这就好像,将一条单车道的窄巷扩宽成四车道的公路,吞吐量自然会提升
链接技术
- 链接技术:当两条指令出现“写后读”相关时,若它们不存在功能部件冲突和向量寄存器(源或目的) 冲突,就有可能把它们所用的功能部件头尾相接,形成一个链接(长)流水线,进行流水处理。
- 链接过程:无链接情况下,后面的功能需要等到前一个功能的n个结果都产生才能开始;而链接情况下,后面的功能只需要等到前一个功能的第一个结果产生就可以开始,即向量数据的生产与向量数据的消费进行延迟的重叠。
- 链接实质:把流水线定向的思想引入到向量执行过程,对两条流水线进行联合控制,没有改变寄存器和运算电路。
进行向量链接的要求
- 保证:无向量寄存器使用冲突和无功能部件使用冲突
- 只有在前一条指令的第一个结果元素送入结果向量寄存器的那一个时钟周期才可以进行链接。
- 当一条向量指令的两个源操作数分别是两条先行指令的结果寄存器时,要求先行的两条指令产生运算结果的时间必须相等,即要求有关功能部件的通过时间相等。
- 要进行链接执行的向量指令的向量长度必须相等,否则无法进行链接。
- 一次链接行为通常仅发生在分组内部,即不对整个N进行链接,而对个分组内的n个向量元素的计算过程进行链接
编队技术
- 几条能在同一个时钟周期内一起开始执行的向量指令集合称为一个编队;
-
同一个编队中的向量指令之间
- 不存在结构冲突;
- 不存在数据冲突;
- 存在数据冲突,但是可以链接。
分段开采技术
- 当向量的长度N大于向量寄存器的长度n时,必须把长向量N分成长度固定为n的段,然后循环分段处理,每一次循环只处理一个向量段。这种技术称为分段开采技术。
- 由系统硬件和编译软件合作完成控制,对程序员是透明的。
向量体系结构的性能影响因素
- 操作数向量的长度
- 向量启动时间
- 操作之间的数据相关,是否采用链接
- 操作之间的结构性相关,发射限制,车道数量,是否采用编队
GPU结构