Druid简介
Druid是一个快速的列式分布式的支持实时分析的数据存储系统;它在处理PB级数据,毫秒级查询,数据实时处理方面,比传统的OLAP系统有了显著的性能改进
官网:
http://druid.io/
ps:阿里巴巴也有一个项目叫Druid,但是它是一个数据库连接池项目
Druid特点
1.列式存储格式
Druid使用面向列的存储,它只需要加载特定查询所需的列,查询速度快
2.可扩展的分布式系统
Druid通常部署在数十到数百台服务器的集群中,并且提供数百万条/秒的摄取率,保留数百万条记录,以及压秒级到几秒钟的查询延迟
3.大规模的并行处理
Druid可以再整个集群中进行大规模的并行查询
4.实时或批量摄取
Druid可以实时摄取数据(实时获取的数据可立即用于查询)或批量处理数据
5.自愈,自平衡,易操作
集群扩展和缩小,只需要添加或删除服务器,集群将在后台自动重新平衡,无需任何停机时间
6.数据进行了有效的预聚合或预计算,查询速度快
7.数据的结果应用了Bitmap压缩算法
Druid应用场景
1.适用于清洗好的记录实时录入,但不需要更新操作
2.适用于支持宽表,不用join的方式(也就是一张单表)
3.适用于可以总结出基础的统计指标,用一个字段表示
4.适用于实时性要求高的场景
5.适用于对数据质量的敏感度不高的场景
Druid对比Impala/Presto/Spark SQL/Kylin/Elasticsearch
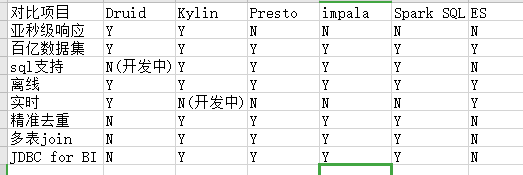
1.Druid
是一个实时处理时序数据的OLAP数据库,因为它的索引首先按照时间分片,查询的时候也是按照时间线去路由索引
2.Kylin
核心是cube,cube是一种预计算技术,基本思路是预先对数据作多维索引,查询时只扫描索引而不访问原始数据从而提速
3.Presto
它没有使用MapReduce,大部分场景下比hive快一个数量级,其中关键是所有的处理都在内存中完成
4.impala
基于内存运算,速度快,支持的数据源没有Presto多
5.spark sql
基于spark平台上的一个OLAP框架,基本思路是增加机器来并行计算,从而提高查询速度
6.ES
最大的特点是使用了倒排索引解决索引问题;根据研究,ES在数据获取和聚集用的资源比在Druid高
7.框架选型
1)从超大数据的查询效率来看
Druid>kylin>presto>spark sql
2)从支持的数据源种类来讲
presto > spark sql > kylin>Druid
Druid框架原理
这个文章讲得可以:
https://blog.csdn.net/hellobabygogo3/article/details/79782756
Druid数据结构
与Druid架构相辅相成的是其基于DataSource与Segment的数据结构,它们共同成就了Druid的高性能优势。
Druid的DataSource相当于关系型数据库中的表(table),DataSource包括:
1.时间列:表明每行数据的时间值,默认使用UTC时间格式且精准到毫秒级别
2.维度列:维度来自于OLAP的概念,用来标识数据行的各类别信息
3.指标列:是用于聚合和计算的列,通常是一些数字,计算操作通常包括count,sum等

无论是实时数据消费还是批量数据处理,Druid在基于DataSource结构存储数据时即可选择对任意的指标进行聚合操作;该聚合操作主要基于维度列与实践范围两方面的情况
Druid在数据存储时便可对数据进行聚合操作是其一大特点,使得Druid不仅能够节省存储空间,而且能够提高聚合查询的效率
DataSource是一个逻辑概念,Segment却是数据的实际物理存储格式,Druid将不同时间范围的数据存储在不同的Segment数据库中,这就是所谓的数据横向切割;按照时间横向切割数据,避免了全表查询,极大的提高了效率
在Segment中,也采用面向列进行数据压缩存储(bitmap压缩技术),这就是所谓的数据纵向切割
Druid安装(单机版)
1.安装包下载
从https://imply.io/get-started 下载最新版本安装包
2.安装部署
imply集成了Druid,提供了Druid从部署到配置到各种可视化工具的完整的解决方案
3.将imply-3.2.0.tar.gz上传到master的/home/hadoop-jrq/bigdata目录下,并解压
tar -zxvf imply-3.2.0.tar.gz
4.imply-3.2.0名称为imply
mv imply-3.2.0/ imply
5.修改配置文件
1)修改Druid的ZK配置
vi imply/conf/druid/_common/common.runtime.properties
修改如下内容
druid.zk.service.host=master:2181,slave1:2181,slave2:2181
2)修改启动命令参数,使其不校验不启动内置ZK
vi imply/conf/supervise/quickstart.conf
修改如下内容
:verify bin/verify-java
#:verify bin/verify-default-ports
#:verify bin/verify-version-check
:kill-timeout 10
#!p10 zk bin/run-zk conf-quickstart
6.启动
1)启动Zookeeper,三台服务器
zkServer.sh start
2)启动imply
bin/supervise -c conf/supervise/quickstart.conf
ps:每启动一个服务均会打印出一条日志。可以通过imply/var/sv/查看服务启动时的日志信息
7.web界面的使用
比较简单,就不写了