今天是刘小爱自学Java的第62天。
感谢你的观看,谢谢你。
话不多说,继续数据库的学习:

使用了数据库可视化工具Navicat,感觉真香。
比在Dos窗口中操作方便多了,那个黑乎乎的窗口真心不习惯,并且也有提示。
今天详细地学习下数据记录的查询,同时最后对这几天的知识点做一个总结。
一、基本查询
select,选择选取的意思,在数据库之中可以理解成查询。
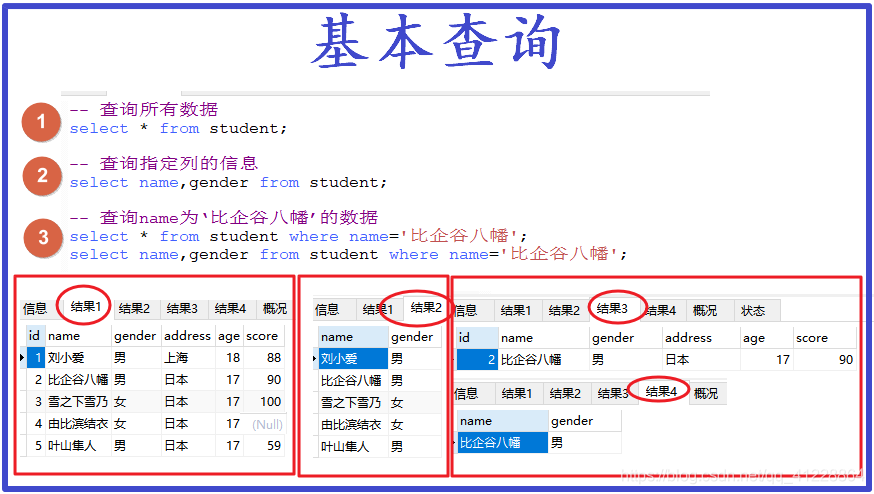
①查询所有数据
select * from student;
*即代表了所有数据,格式为:
select * from+表名
②查询指定列的信息
select name,gender from student;
查询表中name,gender这两列的所有数据,格式为;
select+列名,列名,列名+from+表名
列名之间用逗号隔开。
③条件查询
select * from student where name=“比企谷八幡”;
查询表中name为“比企谷八幡”的所有数据,其中也可以选择部分列的数据,格式不再赘述。
总之where后面填写判断条件。
其中还有运算符相关的查询操作:

①查询成绩不及格的同学
select * from student where score<60;
即score<60的所有数据。
②查询成绩不等于90的同学
不等于在SQL中有三种表示方式:
- not score=90;
- score!=90;
- score<>90;
③查询成绩在80和90之间的数据
也就是80<=score<=90,在SQL中有两种方式:
- between 80 and 90;
- score>=80 and score<=90;
and,即并且的意思。
④查询成绩为88,95,100的同学
在SQL中有两种方式:
- score in(88,95,100);
- score=88 or score=95 or score=100;
or,即或者的意思。
上述均为条件查询,也就是用where来说明判断条件,只不过条件中设计到了运算
二、模糊查询、滤重和别名
除了上述的基本查询之外,还有模糊查询:
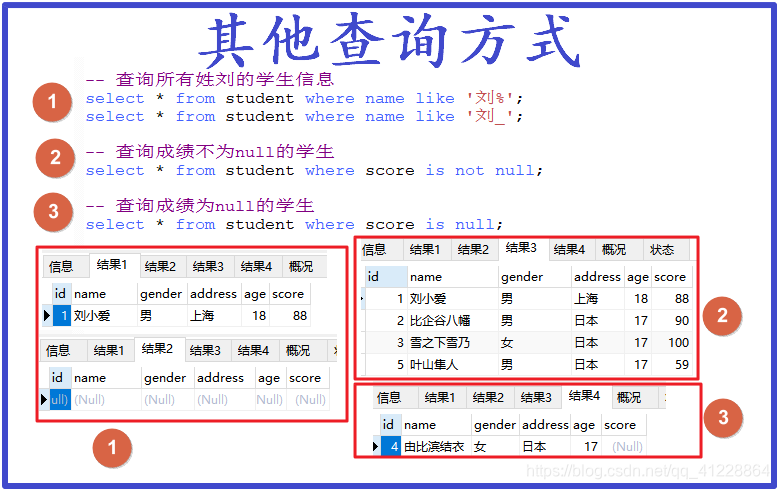
①模糊查询
like,像的意思,可以用来模糊查询:
- name like ‘刘%’;其中%表示1个或多个;
- name like ‘刘_’;其中_表示1个。
其中第一个只要以刘开头即可以,第二个以刘开头的两个字。
②查询成绩不为null的学生
score is not null;
这很好理解,从字面意思就能看出来。
③查询成绩为null的学生
score is null;
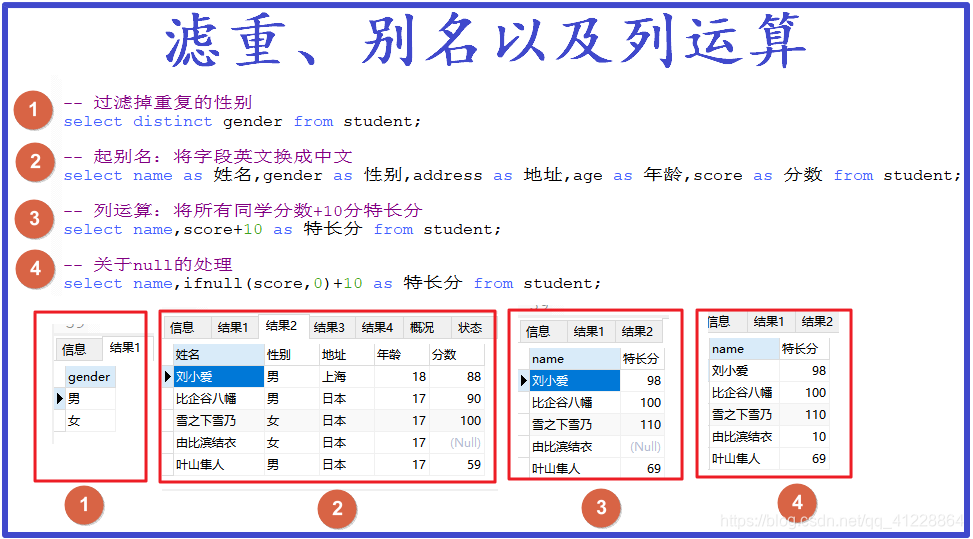
①过滤掉重复的数据
distinct,清楚的、不同的意思,在这里可以理解成过滤,格式如下:
select distinct+列名+from+表名
其中列名可以有多个。
②给列名起别名
可以给列名起一个别名,格式如下:
select 列名 as 别名+from+表名
就算取别名了,
数据库里的列名是没有改变的。
它就是一个渲染效果,所以as后面接什么都可以,字符串也不用加引号。
其中as也可以省略,但最好不省略。
③列运算
这个也好理解,直接在查询列名上+10即可。
其中有一行数据score=null,在SQL中:
null与任何数相加都为nul
l。(有点类似于Java中的字符串)
④关于null的处理
ifnull(列名,默认值) ,如果列名为空,给它一个默认值,图中默认值为0,这样就能参与运算了。
三、排序查询及聚合函数
1排序查询
order,订单、排序的意思,在数据库中order就是排序的意思,和前面我们学的sort是一样的。
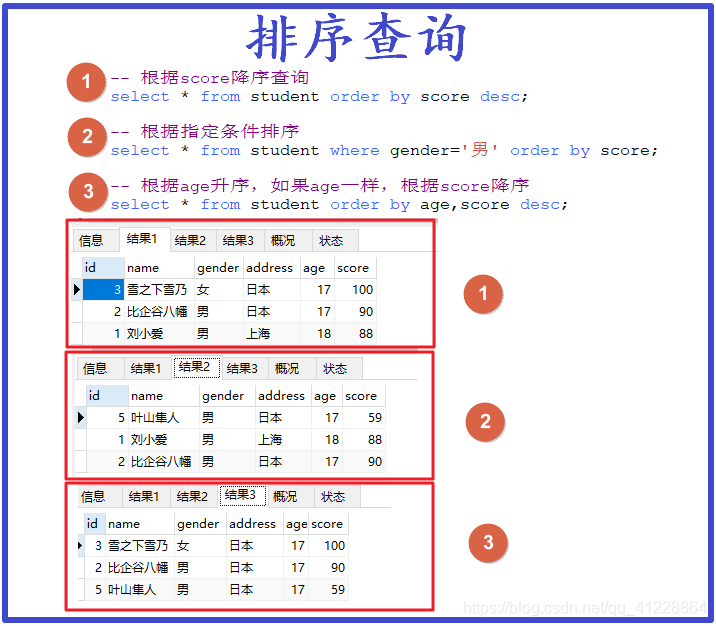
①根据score排序查询
select * from+表名+order by+列名+desc
- desc,在这里是降序的意思。
- asc,即为升序。
②根据指定条件排序
现在只对男生排序,故加一个where条件判断。
注意:
where是紧接着
from+表名
后面的,这是语法。
其中因为是升序,所以可以省略不写
②根据年龄、分数组合排序
多重排序,先根据前面的条件排序,再根据后面的条件排序。
2聚合函数
SQL语言中定义了部分的函数,可以对查询结果进行操作,也就是聚合函数。

①统计数量
count,数数的意思,即统计表示数据数量。
- count(*):*代表所有,即查询所有数据,结果为5。
- count(score):score这一列因为有一行数据为null,所以不计算在内,
②统计班上的总分
sum,求和的意思。
- sum(score):分数这一列所有的数据求和。
- sum(score+age):(分数+年龄这两列)所有的数据求和。
③统计班上的平均分
avg,求平均数的意思,很好理解。
- avg(score):分数这一列求平均值。
- avg(score+age):分数+年龄这两列求平均值。
- sum(score)/count(*):总分除以总人数求平均值。
这两种的区别在于第一种如果数据为null,不加入运算,第二种将nul的数据也加入运算了。
④保留小数点数
round(avg(score),2);2,即表示保留小数点数为2位,可自行设点想要保留的小数点数。
此外,还有两个聚合函数:
- max(score):求分数这列的最大值。
- min(score):求分数这列的最小值。
用法和上述一样,就不再赘述了。
再次强调
:
- null是不参与运算的。
- 可以使用ifnull(列名,默认值)给null设定一个默认值。
四、分组查询及查询语句执行顺序
1分组查询
group,分组的意思,关键单词为group by。

①分男女组查询平均分
根据性别gender分组查询。
格式
为:select+列名+from+表名+group by+列名
②根据特定条件分组查询平均分
前面的学习也知道了,
where
后面专门是接
查询条件
的,但是在分组查询中一般用having代替,其放在group by后面。
2查询语句执行顺序
用一个例子来说明执行顺序,如下图:

①from+表名
这是第1步,表中的所有数据。
②where+指定条件
这是第2步,查询出指定条件的数据。
其中起别名:as+别名
这是第2.5步,介于第1步和第2步之间。
所以where后面不能接别名,因为别名都还没有执行。
③group by+列名
这是第3步,按照指定列名分组。
其中聚合函数:avg(列名)
这是第3.5步,聚合函数是介于第3步和第4步之间。
所以分组不能接聚合函数。
④having+条件
这是第4步,所以having后的查询条件,既可以有别名,也可以有聚合函数。
而where就不行,因为where执行的太早了。
⑤select+查询语句
这是第5步,查询出对应的数据,也就是结果集。
⑥order by+列名+desc|asc
查询语句是最后执行的,所以也可以接别名。
面试题:where 和 having 的区别
- having 通常与group by(分组查询)结合使用。
- where 是在分组之前进行过滤的,having 是在分组之后进行过滤的。
-
having 可以接聚合函数和别名,where都
不可以
。也就是说having的查询条件比where更广。
查询时,如非必要,用where的效率更高。
为什么?
where先执行,先将数据筛选之后会减少计算量。
后续再进行其他条件判断,这样可以提高查询效率。
最后
对这几天知识点做一个总结:
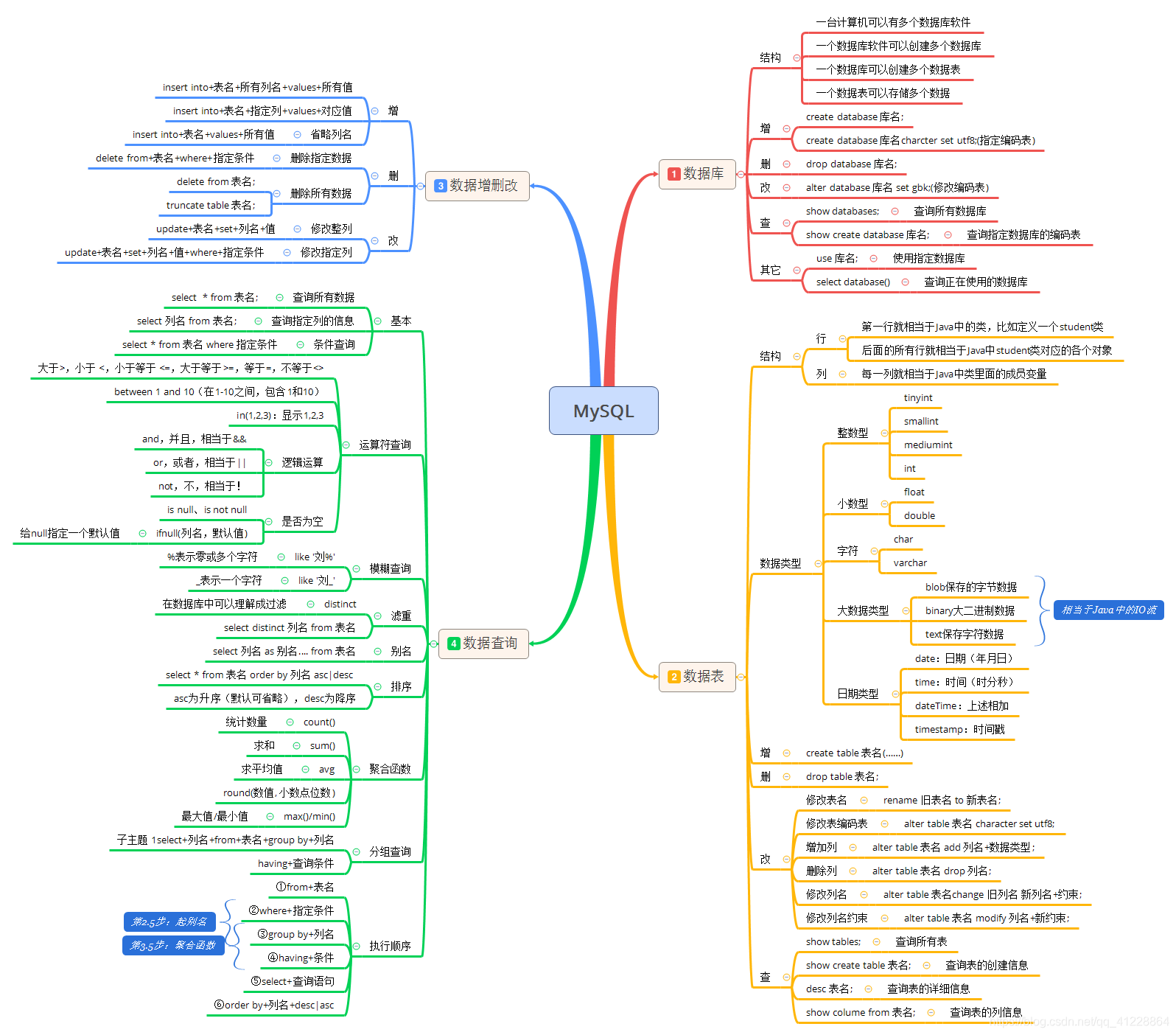
谢谢你的观看。
如果可以的话,麻烦帮忙点个赞,谢谢你。