原文链接:
https://machinelearningmastery.com/impressive-applications-of-generative-adversarial-networks/
简介
如果说目前深度学习最火,应用最多的领域,莫过于 GAN–Generative Adversarial Network,翻译过来就是生成对抗网络,单单从名字上看,你会觉得它就是一个生成模型,看起来就是用于生成图片而已。
实际上,它最开始出现的时候,确实就是用于生成图片,但它可不只是一个生成模型,它实际上是两个网络相互博弈,一个是生成器,也就是生成假图片,另一个就是判别器,用于判断输入图片的真伪,然后目标自然就是让判别器无法判断生成器的图片是真还是假。
当然距离它在 2014 年第一次提出来的时候,已经过去 5 年了,它的应用不仅仅局限在生成图片,越来越多的研究人员把它应用到各个方面,包括图片转换、图像修复、图像超分辨率、风格迁移、文本生成、视频生成等等,今天介绍的这篇文章,就是总结下目前 GANs 可以实现的一些有趣的应用!
文章将这些应用分为以下这些领域,然后会介绍实现该应用的论文,主要是 2016-2018年之间的论文
- 生成图片
- 人脸生成
- 照片生成
- 生成卡通人物
- 图像转换
- 文本到图片的转换
- 语义图片到照片的转换
- 正脸图片生成
- 生成新的人体姿势
- 照片到表情的转换
- 照片编辑
- 图片混合
- 超分辨率
- 图片修复
- 衣服转换
- 视频预测
- 3D 物体生成
1. 生成图片
这是 2014 年最早提出 GANs 的论文 “
Generative Adversarial Networks
” 中所实现的应用,如下图所示,包括生成 MNIST 手写数字数据集、CIFAR10 小物体图片、人脸数据集的图片。

接着 2015 年的论文
Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
,也被称为
DCGAN
实现了稳定使用 CNN 训练 GAN ,其结果如下图所示:

2. 人脸生成
人脸方面的应用本来就是计算机视觉领域最热门也是应用最深、技术最成熟的其中一个方向,GANs 自然也涉及到这方面的应用了。
2017 年的论文 ”
Progressive Growing of GANs for Improved Quality, Stability, and Variation
“,简称
ProGAN
, 可以做到生成非常逼真的人脸,如下图所示

这篇论文还展示了它的其他应用,生成其他物体的实验结果:

另外,2018 年的一份报告 “
The Malicious Use of Artificial Intelligence: Forecasting, Prevention, and Mitigation
” 描述了从 2014 年到 2017 年 GANs 的快速发展,并且以人脸生成作为例子,如下展示这几年人脸生成的结果的变化,确实是越来越逼真了。

3. 照片生成
2018 年的论文“
Large Scale GAN Training for High Fidelity Natural Image Synthesis
” ,也叫作
BigGAN
,在生成真实照片方面做出非常好的结果,如下图所示,当初发表的时候,也是引起很大的关注–
学界 | 史上最强GAN图像生成器,Inception分数提高两倍
.

4. 生成卡通人物
2017年的论文 “
Towards the Automatic Anime Characters Creation with Generative Adversarial Networks
” 则是将 GANs 应用到生成日本动漫人物的人脸方面的应用了,如下图所示

此外也有人应用 GANs 生成宠物小精灵的图片,如下图所示,其项目地址为:

不过最近也有人用 GANs 来生成不同属性的神奇宝贝:

5. 图像转换
图像转换是将 GANs 应用在很多转换的任务上,这里最著名的一篇论文就是2016年的 “
Image-to-Image Translation with Conditional Adversarial Networks
” ,也就是
pix2pixGAN
,它可以实现这些图片的转换:
- 将语义图片转换为街景和建筑的照片
- 卫星照片转成谷歌地图
- 照片从白天转为夜晚的景色
- 黑白照片上色
- 素描图转彩色图片
下面是论文的展示结果,第一行分别就是语义图片转街景、语义图片转建筑图片、黑白图片上色,第二行就是卫星照片转谷歌地图、白天转为夜晚以及素描图片转彩色图片。
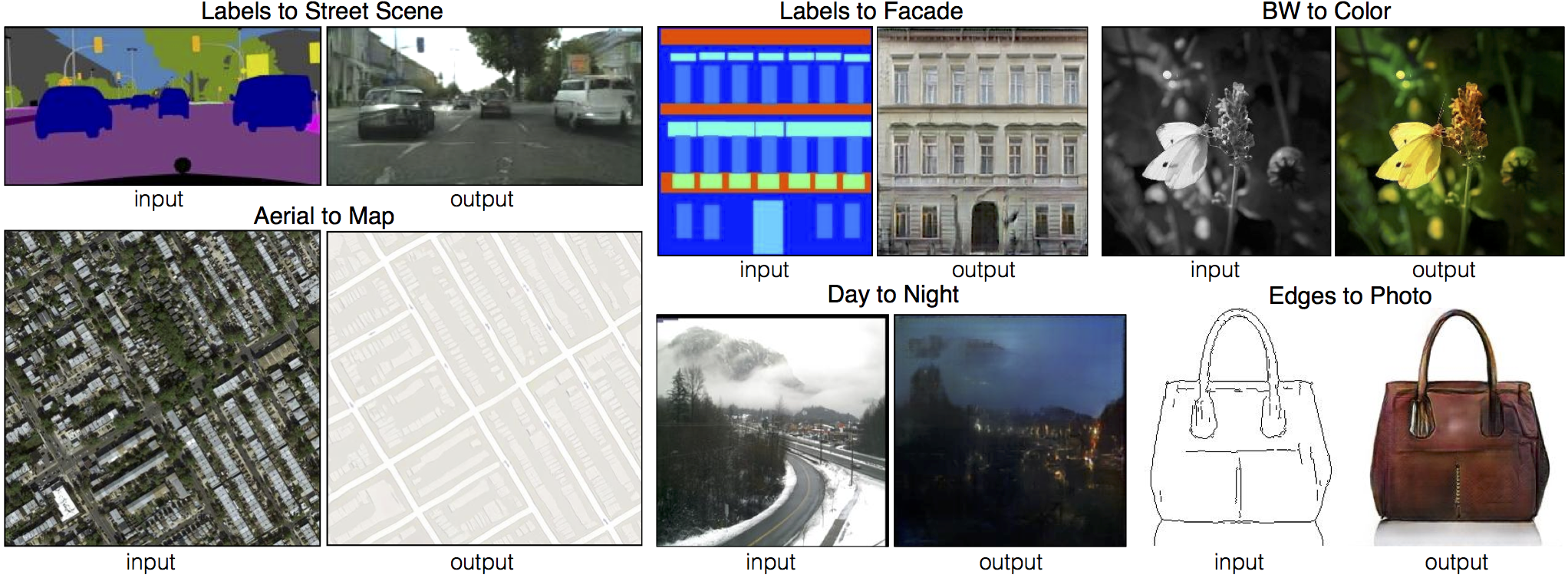
但
pix2pixGAN
对数据集要求是成对,即输入图片和其期望输出图片是一对,但这对数据集要求很高,很多时候并没有这样成对的图片,于是 2017 年有了一篇改进的论文 “
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
”,也就是
CycleGAN
,它只需要原始领域和目标领域的数据集即可,不需要一一对应的成对数据,它可以实现以下几种转换:
- 照片转为艺术画风格
- 普通的马和斑马的转换
- 照片从夏天变为冬天的风格
- 卫星图片转谷歌地图
其实现结果如下所示,第一行就是艺术画和照片转换、斑马和普通马的转换、夏天和冬天季节转换,而第二行、第三行则是具体介绍了每种转换的一个例子。

6. 文本到图片的转换
2016 年的一篇论文 “
StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks
” ,介绍了采用
StackGAN
来实现通过简单的对如鸟类和花朵的文本描述,生成逼真的照片。如下图展示了两个例子,两句话的生成结果,第一句话是描述的是一个头部为红色,然后羽毛从头到尾是逐渐从红色渐变为灰色的鸟,而第二句话描述的是深绿色并有一个短嘴的鸟。

2016年的另外一篇论文 “
Generative Adversarial Text to Image Synthesis
” 则可以实现更多的文本到图片的描述,包括生成鸟类、花朵等等,如下图所示:

其他相似的论文还有:
-
TAC-GAN – Text Conditioned Auxiliary Classifier Generative Adversarial Network
,2017 -
Learning What and Where to Draw
,2016
7. 语义图片到照片的转换
2017年的论文 “
High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs
” 采用了条件 GANs 方法来生成非常逼真的照片,它可以根据给定的语义照片生成对应不同类型的照片:
- 街景照片
- 卧室照片
- 人脸照片
- 给定素描图片生成人脸照片
一个生成街景照片的例子如下图所示:

8. 正脸图片生成
2017 年的论文 “
Beyond Face Rotation: Global and Local Perception GAN for Photorealistic and Identity Preserving Frontal View Synthesis
” 实现了给定非正脸的输入照片,生成正脸的照片结果。这个可以应用在对人脸验证或者人脸识别系统中。
效果如下图所示:

9. 生成新的人体姿势
2017 年论文 “
Pose Guided Person Image Generation
” 实现了可以给定输入图片,然后生成的姿势,如下图所示,输入是正向,侧面或者背面姿势,都可以生成新的姿势,包括正向的生成侧面图片等等;

10. 照片到表情的转换
2016 年的论文–“
Unsupervised Cross-Domain Image Generation
” 使用 GAN 来生成不同领域的图片,比如街景数量到手写字体数据集,然后再生成哪种程度的表情或者是卡通人物的脸。如下所示:

11. 照片编辑
CVPR 2018 的论文 “
StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
” 实现了对照片编辑,主要是对人脸属性的编辑,如下图所示,它可以修改人脸的一些属性,包括头发颜色、表情、性别、年龄变化等,这都取决于训练集是否包含对应的标签。

starGAN 已经开源,项目地址是:
https://github.com/yunjey/stargan
其他相似的论文有:
-
Invertible Conditional GANs For Image Editing
,2016 -
Coupled Generative Adversarial Networks
,2016 -
Neural Photo Editing with Introspective Adversarial Networks
,2016 -
Image De-raining Using a Conditional Generative Adversarial Network
,2017
下面几篇主要是针对人脸年龄变化:
-
Face Aging With Conditional Generative Adversarial Networks
,2017 -
Age Progression/Regression by Conditional Adversarial Autoencoder
,2017
12. 图片混合
2017年的论文
GP-GAN: Towards Realistic High-Resolution Image Blending
采用 GANs 来实现图片的混合操作,即融合多张图片的不同元素,如下图所示,它是将图 a 中间部分融合到图 b 同样位置。

13. 超分辨率
图像超分辨率技术指的是根据
低分辨率图像生成高分辨率图像
的过程,该技术希望根据已有的图像信息重构出
缺失的图像细节
。
ECCV 2018 的论文–
ESRGAN: Enhanced super-resolution generative adversarial networks
提出的 ESRGAN,即增强型超分辨率生成对抗网络,它可以将真实的细节添加到低分辨率的图像中,因此产生更精细的画面。其实现的结果如下所示:

ESRGAN 的项目地址:
https://github.com/xinntao/ESRGAN
不仅可以实现对图片的超分辨率,对视频的超分辨率也有人采用 GANs 技术进行实现–
Temporally Coherent GANs for Video Super-Resolution (TecoGAN)
,这篇论文首次提出了一种对抗和循环训练方法,以监督空间高频细节和时间关系。具体介绍可以查看下面这篇文章的介绍:
其他实现超分辨率的论文有:
-
Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
,2016 -
High-Quality Face Image SR Using Conditional Generative Adversarial Networks
,2017 -
Analyzing Perception-Distortion Tradeoff using Enhanced Perceptual Super-resolution Network
,2018
14. 图片修复
2019 年的论文
EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning
对图片的修复分为两步,边缘生成然后进行图像补全,具体介绍可以看下:
女神被打码了?一笔一划脑补回来,效果超越Adobe | 已开源
其效果如下,分别展示了六个例子,图 a 是需要修复的图片,图 b 就是中间生成的边缘图,图 c 是最终修复的结果。

项目地址:
https://github.com/knazeri/edge-connect
其他论文有:
-
Image Inpainting via Generative Multi-column Convolutional Neural Networks
,2018 -
Generative Image Inpainting with Contextual Attention
, 2018 -
High-resolution image inpainting using multi-scale neural patch synthesis
,CVPR 2017 -
Generative Face Completion
,2017 -
Context Encoders: Feature Learning by Inpainting
,2016
15. 2d试衣
2017 年的论文–
The Conditional Analogy GAN: Swapping Fashion Articles on People Images
,尝试采用 GANs 实现 2d 试衣的效果,论文给出结果如下,它是给定一个模特和对应需要更换的衣服,然后实现替换模特身上的衣服。

国外有人根据这篇文章进行一些修改,写了篇博客介绍,并且开源了其代码,其结果如下所示:
Github 地址:
https://github.com/shaoanlu/Conditional-Analogy-GAN-keras

目前来看,这个技术还不是非常成熟。
其他相似的论文:
-
INSTAGAN
,2018,Github:
https://github.com/sangwoomo/instagan
16. 视频预测
2016 年的论文–
Generating Videos with Scene Dynamics
介绍了如何用 GANs 实现视频预测,主要是应用于静态场景里面的元素,如下图所示:

17. 3D 物体生成
2016 年的论文–
Learning a Probabilistic Latent Space of Object Shapes via 3D Generative-Adversarial Modeling
介绍了如何通过 GAN 生成新的三维物体,比如椅子、车、沙发、桌子等等,如下图所示:

2016年的另一篇论文–
3D Shape Induction from 2D Views of Multiple Objects
也同样实现给定一张多个视角的二维物体图片,生成三维物体,如下图所示:

小结
更多的关于 GANs 的应用,还可以阅读下面的文章和 Github 项目
-
gans-awesome-applications: Curated list of awesome GAN applications and demo
. -
Some cool applications of GANs
, 2018. -
GANs beyond generation: 7 alternative use cases
, 2018.
参考
欢迎关注我的微信公众号–
算法猿的成长
,或者扫描下方的二维码,大家一起交流,学习和进步!
