每天给你送来NLP技术干货!
来自:圆圆的算法笔记
作者:Fareise
最近谷歌提出了最新多模态预训练方法CoCa,
在图像分类、图文检索、看图说话、VQA等多个任务都取得了SOTA效果
。CoCa可以说融合了历史图像模型、多模态模型训练范式为一体,融合了多种训练范式的优点,具有非常广泛的适用场景。同时,模型的核心结构和设计思路也比较优雅简洁。下面带大家了解一下这篇谷歌最新多模态工作。

论文标题
:CoCa: Contrastive Captioners are Image-Text Foundation Models
下载地址
:https://arxiv.org/pdf/2205.01917.pdf
1
Vision-Language的3种模型
文中首先概括了目前解决图像或多模态问题的3种经典结构,分别是single-encoder model、dual-encoder model、encoder-decoder model。而CoCa融合了这3种模型各自的优势。
-
Single-encoder model
:这指的最基本的图像分类模型,只有一个图像encoder,通过这个encoder生成图像表示,将表示映射到各个类别中实现图像分类。这种方法已经在CV领域经过多年研究,通过在大量图像上训练图像encoder,再迁移到下有任务的模式,取得了非常出色的效果。然而它的问题在于,需要依赖大规模人工标注样本,并且由于拟合的目标为类别标签,无法使用自然语言信息,无法解决vision-language等多模态问题。
-
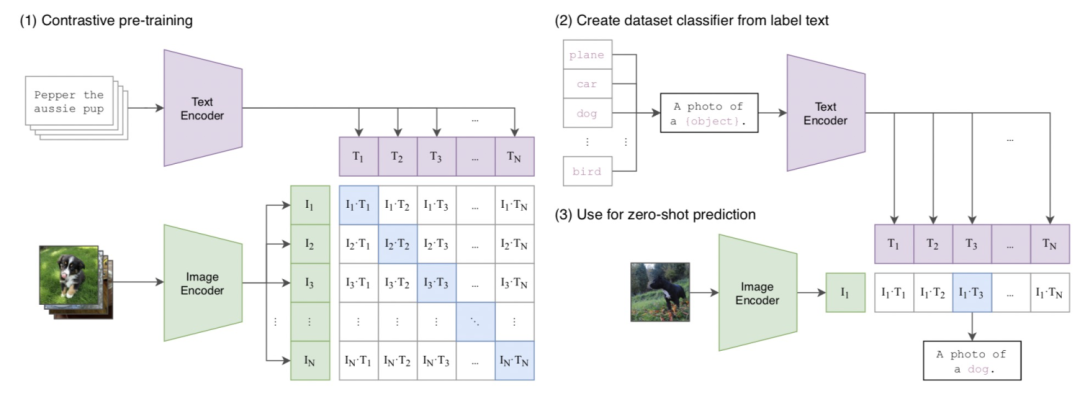
Dual-encoder model
:指的是CLIP这一条线上的研究。利用海量从网络上搜集的图像-文本pair对,利用一个image encoder和一个text encoder分别对图像和文本独立编码,再以对比学习为优化目标训练模型(CLIP细节可以参考历史文章
如何发挥预训练CLIP的最大潜力?
)。CLIP模型在zero-shot图像分类任务,以及图文匹配和检索等问题上取得出色成绩,但是由于CLIP是图像和文本独立编码,且编码过程中并没有任何图像和文本侧的交叉,只在最后计算cosine相似度,缺少图像和文本的融合表示,因此不适用于VQA等需要对图像和文本联合理解的任务(在我们上期更新的微软亚研院的工作,利用prompt的方法使CLIP也在VQA上取得不错的效果)。
-
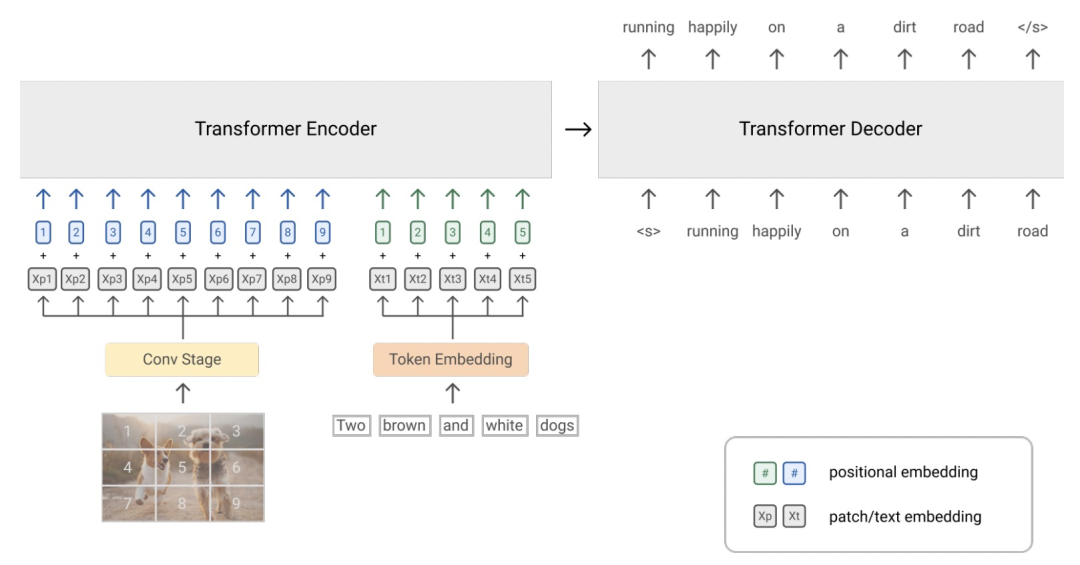
Encoder-decoder model
:这种模型使用encoder-decoder的结构,encoder侧对图像进行编码,在decoder侧学习一个跨模态的语言模型,预测图像对应的文本。这种生成式方法天然适用于看图说话任务,并且图像和文本在encoder-decoder的attention交互有助于融合多模态信息,适用于多模态理解相关任务。而缺点在于,没有像CLIP一样生成单独的文本表示,不能灵活应用到图文匹配任务中。
2
CoCa核心结构
CoCa融合了上面3种模型结构,既能生成图像侧和文本侧独立的表示(CLIP),又能进行更深层次的图像、文本信息融合以及文本生成(Encoder-decoder),适用于更广泛的任务。
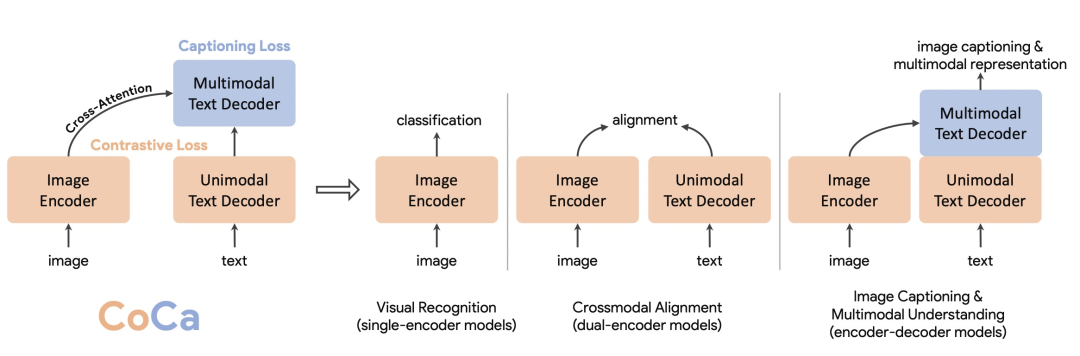
CoCa的整体结构包括3个部分:一个encoder(Image Encoder)和两个decoder(Unimodal Text Decoder、Multimodal Text Decoder)
。Image Encoder采用一个图像模型,例如ViT等。Unimodal Text Decoder在这里起到CLIP中text encoder的作用,是一个不和图像侧信息交互的文本解码器。Unimodal Text Decoder和Image Encoder之间没有cross attention,实际上是一个单向语言模型。最后,Multimodal Text Decoder在单模态文本decoder之上,和图像encoder进行交互,生成图像和文本交互信息,并解码还原对应文本。注意两个文本decoder都是单向的,防止信息泄露。
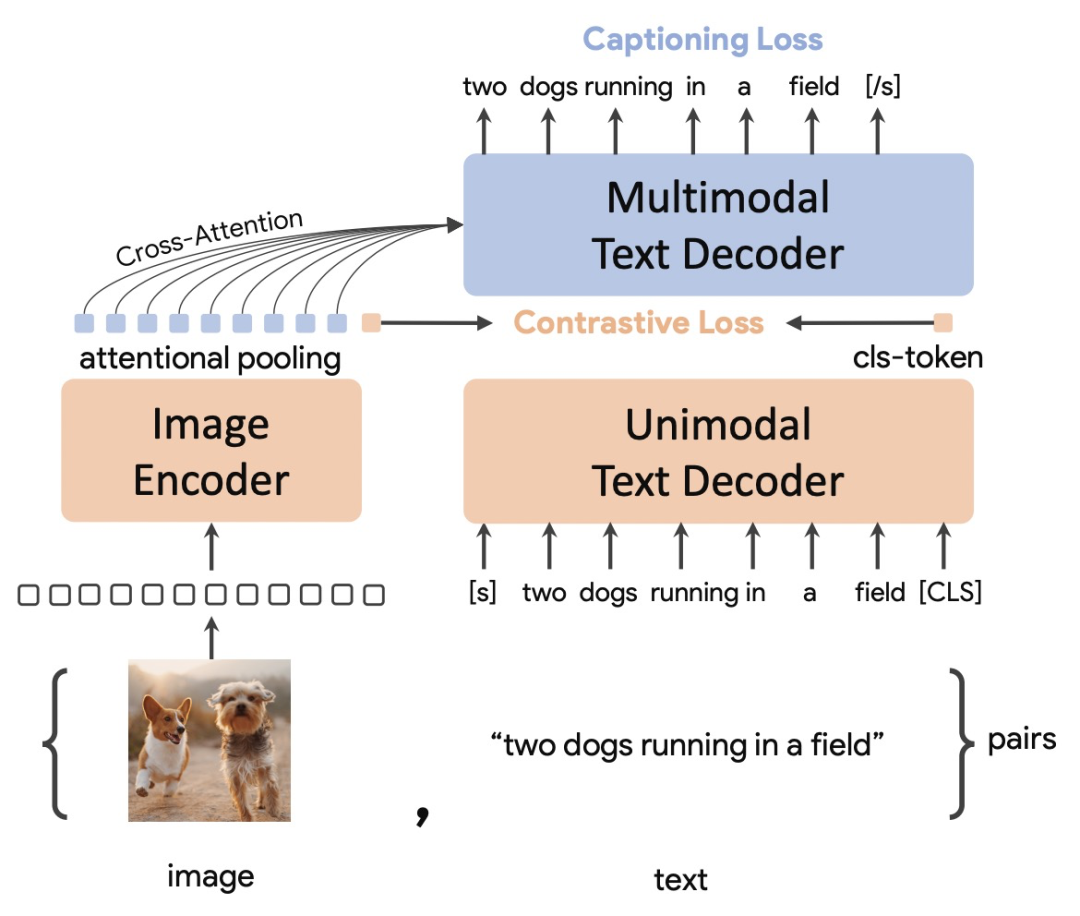
整个模型的loss包括对比学习loss和看图说话loss两个部分。单模态文本decoder生成纯净的文本编码,在末尾添加一个[CLS]提取文本统一表示,和图像侧编码进行对比学习。多模态文本编码部分和图像编码输出进行更深入交互,生成文本预测结果。整个loss可以表示为:
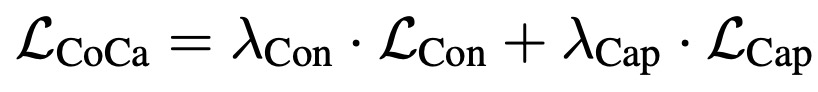
此外,
CoCa采用了attention pooling的方式融合图像侧信息
。图像侧的信息既可以提取一个统一的编码,也可以提取每个token的表示,二者各有不同的适用场景。因此CoCa加了一个attention来获取图像侧表示,对于生成式任务会用一个维度为256的query进行attention,而对比学习则采用维度为1的query提取全局信息。
3
实验结果
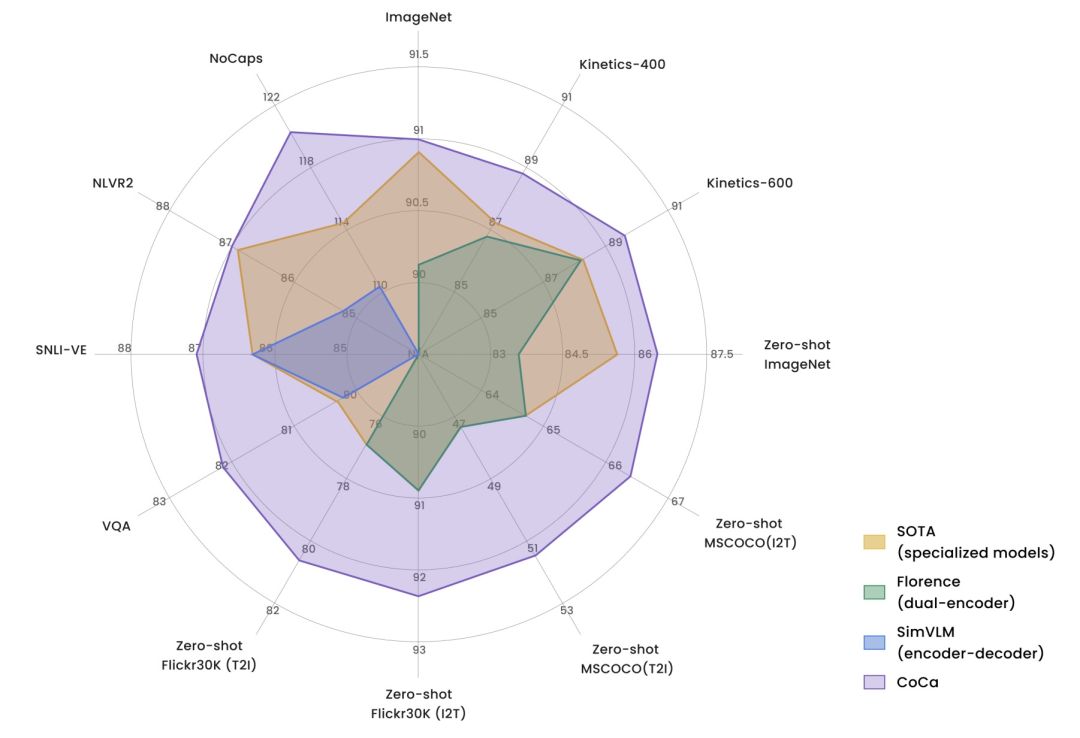
CoCa在图像分类、图文检索、看图说话、VQA等多个任务上取得非常亮眼的效果
。下图是CoCa和3种类型图文模型在多个任务上的效果对比,CoCa的优势非常明显。多个任务和数据集上达到SOTA,在ImageNet上达到91%的效果。
最近文章
EMNLP 2022 和 COLING 2022,投哪个会议比较好?
一种全新易用的基于Word-Word关系的NER统一模型,刷新了14种数据集并达到新SoTA
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套! 后台回复【五件套】
下载二:南大模式识别PPT 后台回复【南大模式识别】整理不易,还望给个在看!