深度置信网络
如果,把
hidden
layers
的层数增加,可以得到
DBM
;如果在靠近
visible layer
的部分使用贝叶斯置信网络
(
有向图模型,限制层中结点之间没有连接
)
,在最远离可视层的部分使用
RBM
,就可以得到
DBN

训练过程:
1.首先充分训练第一个
RBM
;
2.
固定第一个
RBM
的权重和偏移量,然后使用其隐性神经元的状态,作为第二个
RBM
的输入向量;
3.
充分训练第二个
RBM
后,将第二个
RBM
堆叠在第一个
RBM
上方;
4.
重复上述的三个步骤多次;
5.
在输出层采用多项式概率分布来近视正确的标注
y
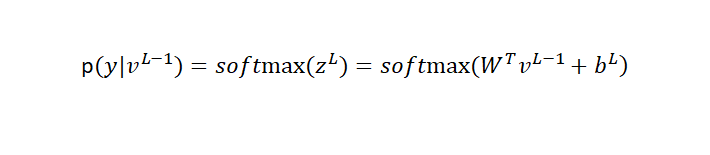
调优过程
:
使用
Wake-Sleep
算法进行调优
1.
除了顶层
RBM
,其他层
RBM
的权重被分成向上的认知权重和向下生成权重;
2.Wake
阶段:认知过程,通过外界的特征和向上的权重
(
认知权重
)
产生每一层的抽象表示
(
结点状态
),
并且使用梯度下降修改层间的下行权重
(
生成权重
)
3.Sleep
阶段:生成过程,通过顶层表示和向下权重,生成底层的状态,同时修改层间向上的权重。
降
噪自动编码器预训练

鉴别性预训练
(DPT)
逐层
BP
,首先使用标注鉴别性训练一个单隐层
DNN
,直到全部收敛,接着在
v1
层和输出层之间插入一个新的随机化的隐藏层,再次利用鉴别性训练整个网络直到完全收敛,一直这样重复训练直到达到所需的隐藏层。
DPT
目标
是调整权重使其接近一个较好的局部最优点。但是
DPT
不具有生成性
DBN
预训练中的正则化效果,
DPT
最好在获得大量训练数据的时候使用。
混合预训练

所有的预训练的目的都是为了调整DNN中的权重矩阵w,使其在开始时就达到一个比较好的状态,其训练出来的结果也会使得比随机初始权重好的效果,使其达到一个优化的效果。
参考:<<Automatic Speech Recognition A Deep Learning Approach>>