因公众号更改推送规则,请点“在看”并加“星标”第一时间获取精彩技术分享
点击关注#互联网架构师公众号,领取
架构师全套资料
都在这里

大家好,我是互联网架构师!
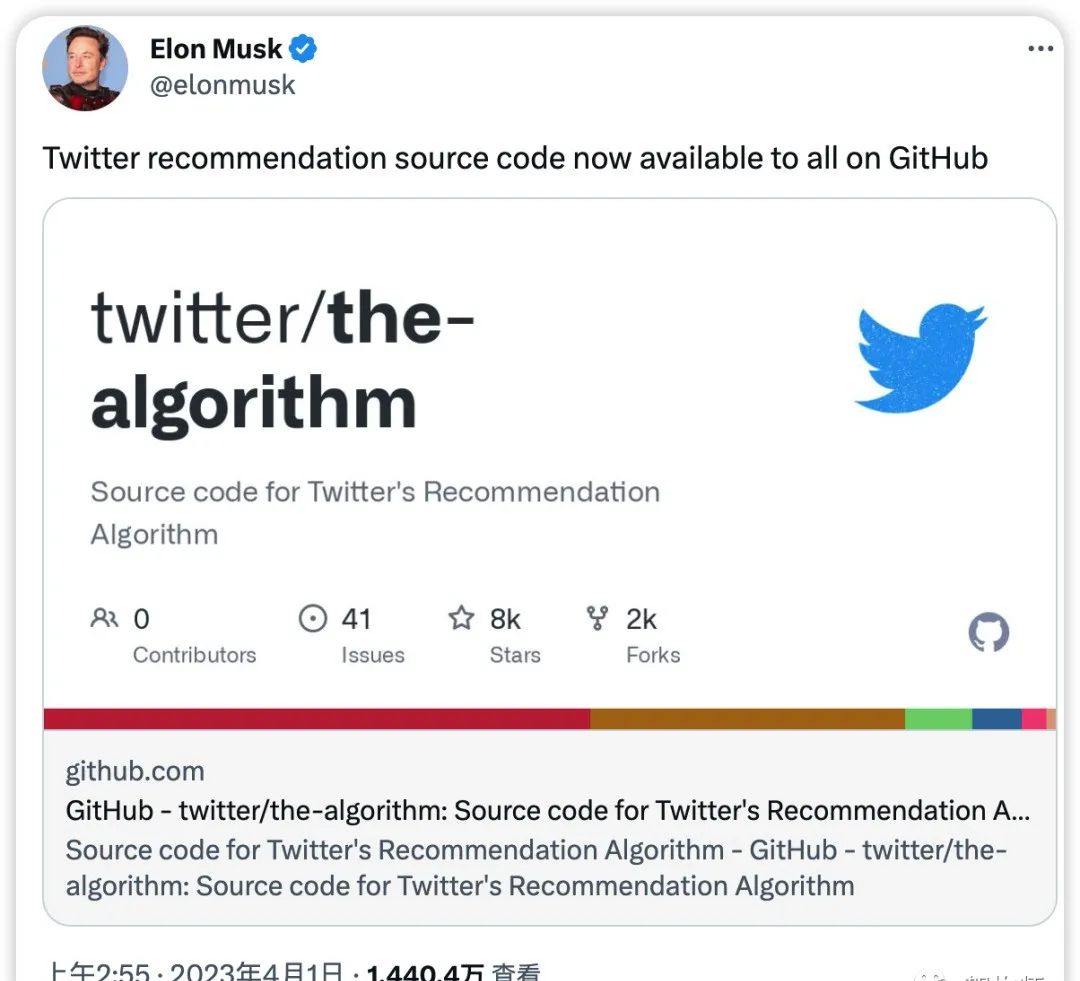
就在昨天,正如马斯克一再承诺的那样,Twitter 已将其部分源代码正式开源,其中包括在用户时间线中推荐推文的算法。截止发文时,该项目在 GitHub 已收获 24k+ 个 Star,4.2k的frok。
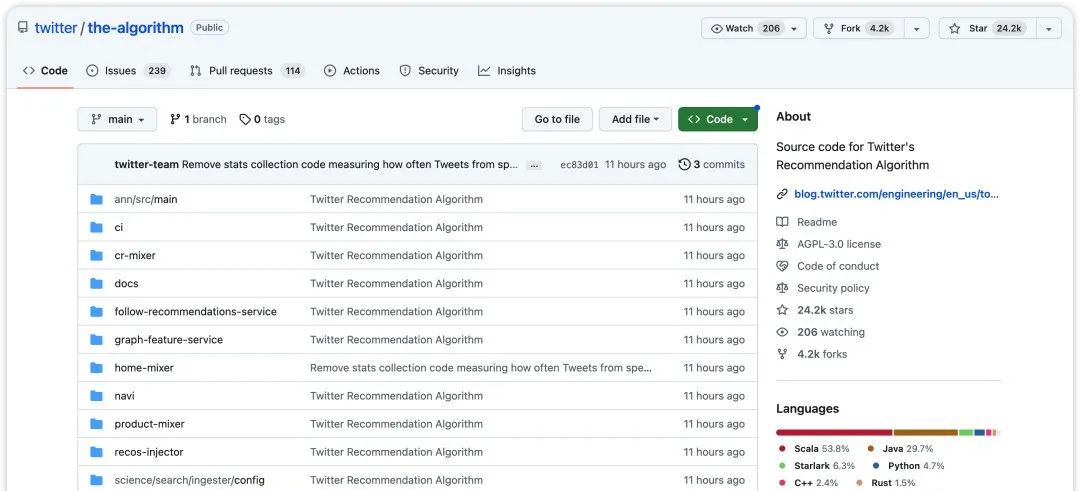
GitHub 地址:https://github.com/twitter/the-algorithm

前言

马斯克在近日通过Twitter宣布,Twitter将于2023年3月31日开源其核心推荐算法。这一算法是决定用户时间线上推文出现顺序的重要因素。这项举措的目的是增强平台的透明度和开放性,使用户更好地了解Twitter算法的运作方式,同时也为研究人员和开发人员提供了机会,他们可以利用这些代码来开发新工具和新功能,以提升Twitter的用户体验。

关于开源的Twitter的推荐算法

Twitter Recommendation Algorithm是一组服务和任务,负责构建和提供主页时间线。有关算法工作原理的介绍,请参阅我们的技术博客。
技术博客:
https://blog.twitter.com/engineering/en_us/topics/open-source/2023/twitter-recommendation-algorithm
下图描绘了主要服务和工作之间的相互连接。
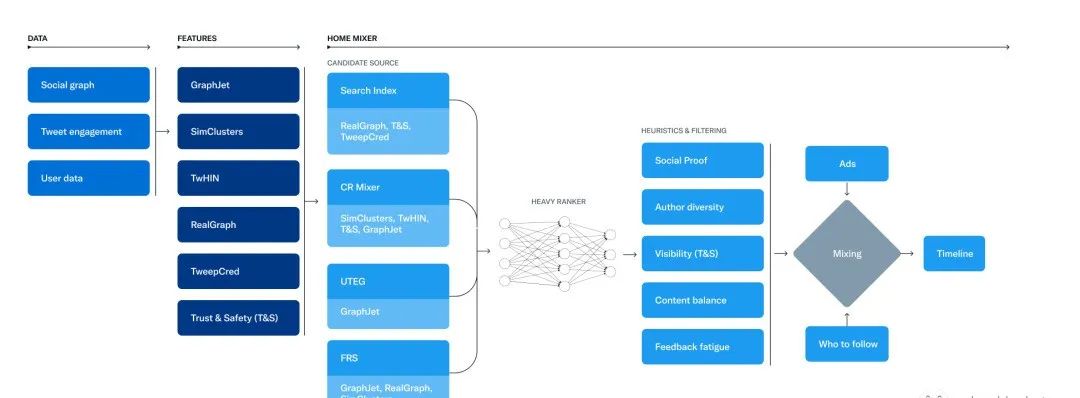
这些是此存储库中包含的推荐算法的主要组件:
| 类型 | 组件 | 说明 |
|---|---|---|
| 功能 | SimClusters | 社区检测和稀疏嵌入到这些社区中。 |
| TwHIN | 用户和推文的密集知识图谱嵌入。 | |
| trust-and-safety-models | 用于检测 NSFW 或滥用内容的模型。 | |
| real-graph | 用于预测 Twitter 用户与其他用户互动的可能性的模型。 | |
| tweepcred | 用于计算Twitter用户声誉的页面排名算法。 | |
| recos-injector | 流事件处理器,用于为基于 GraphJet 的服务构建输入流。 | |
| graph-feature-service | 为一对定向用户提供图形功能(例如,有多少用户 A 关注了来自用户 B 的推文)。 | |
| 数据来源 | search-index | 查找网络内推文并对其进行排名。~50% 的推文来自此候选来源。 |
| cr-mixer | 协调层,用于从基础计算服务中提取网络外推文候选项。 | |
| user-tweet-entity-graph | 维护内存中的用户到推文交互图,并根据此图的遍历查找候选项。这是建立在GraphJet 框架之上的。 | |
| follow-recommendation-service | 为用户提供要关注的账号建议,以及来自这些账号的推文。 | |
| 排名 | light-ranker | 搜索索引用于对推文进行排名的轻度排名模型。 |
| heavy-ranker | 用于对候选人推文进行排名的神经网络。用于选择时间线的主要信号之一 推文发布候选人来源。 | |
| 推文混合和过滤 | home-mixer | 用于构建和服务主页时间线的主要服务。 |
| visibility-filters | 负责过滤 Twitter 内容以支持法律合规性、提高产品质量、增加用户信任度、通过使用硬过滤、可见产品处理和粗粒度降级来保护收入。 | |
| timelineranker | 传统服务,提供来自早鸟搜索索引和 UTEG 服务的相关性评分推文。 | |
| 软件框架 | navi | 高性能,机器学习模型服务,用 Rust 编写。 |
| product-mixer | 用于构建内容源的软件框架。 | |
| twml | 基于 TensorFlow v1 构建的传统机器学习框架。 |
让我们探索这个系统的关键部分,大致按照它们在单个时间线请求期间被调用的顺序,从从Candidate Sources候选来源开始。
候选来源
Twitter 有几个候选源,我们用它们来为用户检索最近和相关的推文。对于每个请求,我们尝试通过这些来源从数亿推文中提取最佳的 1500 条推文。我们从您关注的人(网络内)和您不关注的人(网络外)中寻找候选人。如今,For You 时间轴平均包含 50% 的网络内推文和 50% 的网络外推文,尽管这可能因用户而异。
网内资源
网络内来源是最大的候选来源,旨在提供您关注的用户的最相关、最新的推文。它使用逻辑回归模型根据推文的相关性对您关注的推文进行有效排名。然后将热门推文发送到下一阶段。
对网络内推文进行排名的最重要组成部分是Real Graph。Real Graph 是一种预测两个用户之间参与可能性的模型。您和推文作者之间的 Real Graph 得分越高,我们将包括的他们的推文就越多。
网络内源一直是 Twitter 最近工作的主题。我们最近停止使用 Fanout Service,这是一项已有 12 年历史的服务,以前用于从每个用户的推文缓存中提供网络内推文。我们还在重新设计几年前最后一次更新和训练的逻辑回归排名模型!
网络外资源
在用户网络之外查找相关推文是一个更棘手的问题:如果您不关注作者,我们如何判断某个推文是否与您相关?Twitter 采用两种方法来解决这个问题。
社交图谱
我们的第一种方法是通过分析您关注的人或具有相似兴趣的人的参与度来估计您会发现什么是相关的。
我们遍历参与图并回答以下问题:
-
我关注的人最近与哪些推文进行了互动?
-
谁喜欢和我相似的推文,他们最近还喜欢什么?
我们根据这些问题的答案生成候选推文,并使用逻辑回归模型对生成的推文进行排名。这种类型的图遍历对于我们的网络外推荐至关重要;我们开发了GraphJet,这是一种图形处理引擎,可维护用户和推文之间的实时交互图,以执行这些遍历。虽然这种用于搜索 Twitter 参与度和关注网络的启发式方法已被证明是有用的(这些目前服务于大约 15% 的家庭时间线推文),但嵌入空间方法已成为网络外推文的更大来源。
嵌入空间
嵌入空间方法旨在回答一个关于内容相似性的更普遍的问题:哪些推文和用户与我的兴趣相似?
嵌入通过生成用户兴趣和推文内容的数字表示来工作。然后,我们可以计算该嵌入空间中任意两个用户、推文或用户-推文对之间的相似度。如果我们生成准确的嵌入,我们可以使用这种相似性作为相关性的替代。
Twitter 最有用的嵌入空间之一是SimClusters。SimClusters 使用自定义矩阵分解算法发现由一群有影响力的用户锚定的社区。有 145,000 个社区,每三周更新一次。用户和推文在社区空间中表示,并且可以属于多个社区。社区的规模从个别朋友组的几千用户到新闻或流行文化的数亿用户不等。这些是一些最大的社区:
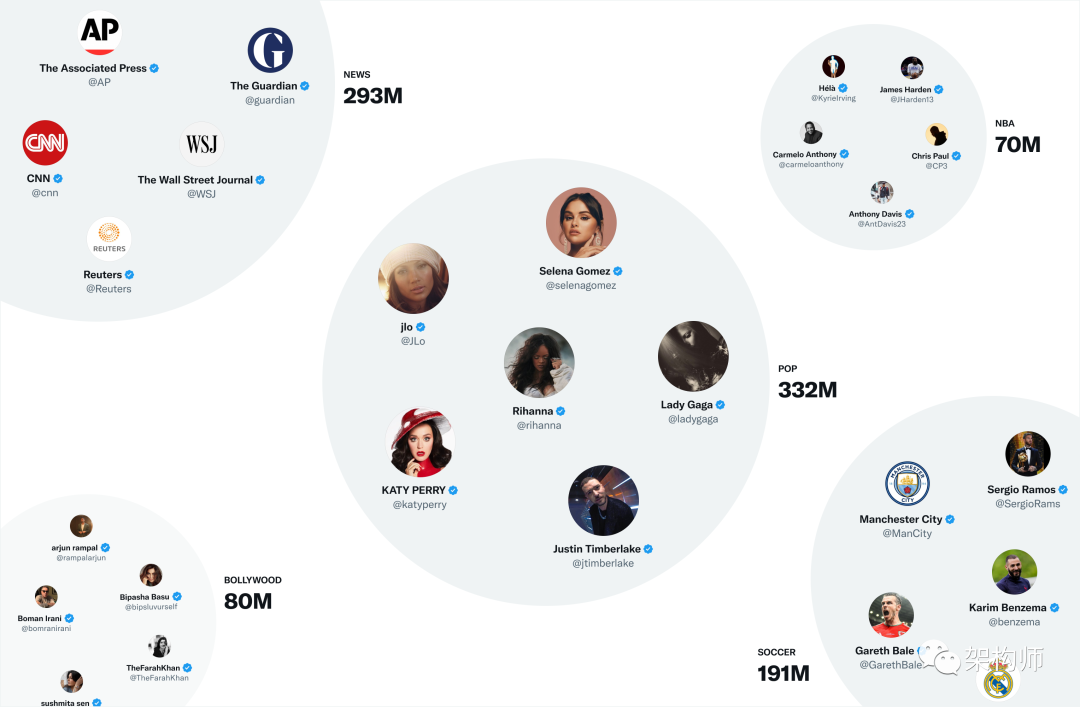
我们可以通过查看推文在每个社区中的当前流行度来将推文嵌入到这些社区中。喜欢推文的社区用户越多,推文与该社区的关联度就越高。

相关链接

-
算法主库:https://github.com/twitter/the-algorithm/
-
ML 模型库:https://github.com/twitter/the-algorithm-ml
-
技术博客:https://blog.twitter.com/engineering/en_us/topics/open-source/2023/twitter-recommendation-algorithm
· END ·
最后,关注公众号互联网架构师,在后台回复:2T,可以获取我整理的 Java 系列面试题和答案,非常齐全。

如果这篇文章对您有所帮助,或者有所启发的话,帮忙扫描上方二维码关注一下,您的支持是我坚持写作最大的动力。
求一键三连点赞、转发、在看。