核心问题:
现有模型要么是利用基于路径的语义相关性作为直接特征进行推荐
(这里的直接特征direct feature 给出了参考论文 1⃣️基于元路径的latent feature 来表示用户与不同类型路径上的项目之间的连接,2⃣️两个对象的基于路径的相似度是基于给定的连接这两个对象的元路径的相似度评价,所以说都是没有考虑对具体路径进行编码,只是利用路径从而得到对用户/项目表示的丰富)
要么就是基于路径的相似性进行一些转换来学习有效的转换特征,然后利用这么转换特征来增强用户和项目的表示进行推荐
问题1:很少学习推荐任务中路径或元路径的显式表示,就是针对整个路径进行最后的final representation embedding
问题2: 他们没有考虑交互中元路径和所涉及的用户-物品对之间的相互影响,直观地说,不同的用户可能对元路径有不同的偏好。即使对于相同的用户,元路径在与不同项目的多次交互中也可能具有不同的语义,元路径本质上是一种type层次上的建立,一种抽象概念,不同用户是在实例中的应用
具体实现:
给出一个用户u和一个项目i,基于元路径的上下文(Meta-path based context)被定义为连接HIN 上两个节点的元路径下的路径实例的聚合集
(1)学习基于元路径的上下文的显式表示
(2)描述<user、meta-path、item>
我们的模型需要学习用户、项目和基于元路径的上下文的表示。 我们提出了一种新的共同关注机制来相互改进基于元路径的上 下文、用户和项目的表示。 首先根据用户-项目对的交互信息改进基于元路径的上下文表示,然后基于改进的基于元路径的上下文表示进一步增强用户和项目表示。
第一步:我们建立了一个查找层,将用户和项目的独热表示转换为低维密集向量

第二步:设置了一个具体优先级的游走来抉择高质量的path instances(相当于构建训练集)
其基本思想是首先利用传统的矩阵分解方 法,在不含元路径信息的情况下,学习具有历史用户-物品交互记录的每个节点的潜在向量。 然后,我们可以通过当前节点和候选出节点之间的相似度来衡 量优先度。 这种优先级得分直接反映了两个节点之间的关联度。
利用学习到的潜在因子,我们可以计算路径实例上两个连续节点之间的成对相似性,然后平均这些相似性来对候选路径实例进行排序。最后,给定一个元路径,我们只保留平均相似度最高的前K个路径实例。
第三步:针对某一个路径实例进行embedding:
路径实例本质上是实体节点的序列,利用CNN来直接学习:
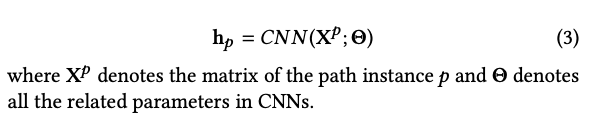
X_p就是concatenating node embeddings。维度是Lx d,L就是路径节点的个数,d是实体嵌入的维度,就是把该路径上的所有实体节点的embedding直接串联。
第四步:就是上述实例的元路径的嵌入表示 Meta-path Embedding,使用Max pooling 操作

第五步:利用两层神经网络学习每个元路径对于用户和项目的注意力:

最终的用户u和项目i交互对之间的元路径上下文表示为:

第六步:得到的元路径上下文表示又可以影响用户/项目的表示,这里也设置一个单层神经网络来学习Meta-path based context分别对用户和项目的注意力:

然后通过以下操作更新原始user和item的embedding:

第七步:结合user、item、context的嵌入生成当前交互表示:

然后送入MLP(两层神经网络)得到最后的复杂表示:
