并行度
- Spark之间的并行就是在同一时间内,有多少个Task在同时运行。并行度也就是并行能力的设置,假设并行度设置为6,就是6个task在并行跑,有个6个task的前提下,RDD的分区就被规划为6个分区。
如何设置并行度
-
规划并行度优先级:代码→客户端提交参数→配置文件→默认设置(默认为1,具体会根据文件的分片数来跑)。
-
配置文件中设置
# conf/spark-defaults.conf中设置
spark.default.parallelism 100
# 客户端提交参数
spark-submit --conf "spark.default.parallelism=100"
# 在代码中设置
conf = SparkConf()
conf.set("spark.default.parallelism", "100")
- Tips:全局并行度是推荐设置,不要针对RDD改分区,可能会影响内存迭代管道的构建或者会产生额外的Shuffle。reparation、coalesce、reparationBy等算子避免使用。
如何规划我们自己群集环境的并行度?
- 一般来说我们设置为群集CPU核心的2-10倍(确保最小为2倍,最大一般来说为10倍适度超出也没什么问题)。
-
为什么最少要设置成2倍呢?
- CPU的一个核心同一时间只能干一件事,所以在100个核心的前提下,设置100个并行,就能保证cpu资源100%的利用,但是如果task压力不均衡,某个task先执行完了,就会导致某个CPU核心空闲。如果设置了800个并行,100个在运行,700个在等待,而某个task运行完之后,后续的task继续运行,不会造成CPU空闲,从而最大程度的利用群集的资源。
Spark的任务调度
-
Driver也就是我们通常理解的包工头。它的主要工作就是:
- 1 逻辑DAG的构建
- 2 分区DAG的构建
- 3 Task划分
- 4 将Task分配给Executor(民工)并监控其工作
-
Spark调度流程图:
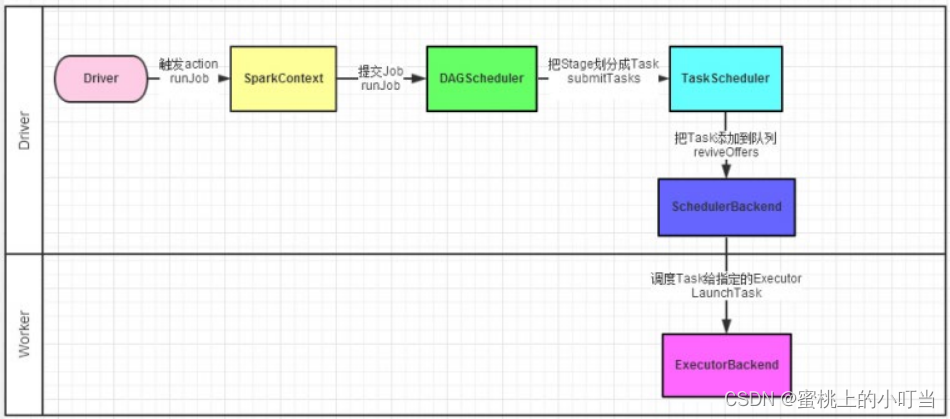
- Driver被构建出来。
- 构建SparkContext(执行环境入口对象)。
- 基于DAG Scheduler(DAG 调度器)构建逻辑Task的分配。
- 基于Task Scheduler(Task 调度器)将逻辑Task分配到各个Executor上干活,并监控它们。
- Worker(Executor)被监控,听它们的指令干活,并且定期汇报执行进度。
-
Driver内的的两个调度组件:
-
DAG 调度器
工作内容:将逻辑DAG图进行处理,最终得到逻辑上的Task划分。 -
Task 调度器
基于DAG Scheduler的产出,来规划这些逻辑的Task,应该在哪个物理Executor上面去运行,并且监控它们。
-
DAG 调度器
版权声明:本文为sinat_31854967原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。