注:欢迎关注本人分享有关个性化推荐系统公众号:Tiany_RecoSystem
转发一篇关于DeepFM的公式推导的博客:
论文精读-DeepFM – CSDN博客blog.csdn.net
以及DeepFM的实现参考链接:
Jachin:推荐系统中使用ctr排序的f(x)的设计-dnn篇之DeepFM模型zhuanlan.zhihu.com
以及其他DeepFM的理论实践:
Python程序员:推荐系统遇上深度学习(三)–DeepFM模型理论和实践
目前的CTR预估模型,实质上都是在“利用模型”进行特征工程上狠下功夫。传统的LR,简单易解释,但特征之间信息的挖掘需要大量的人工特征工程来完成。由于深度学习的出现,利用神经网络本身对于隐含特征关系的挖掘能力,成为了一个可行的方式。DNN本身主要是针对于高阶的隐含特征,而像FNN(利用FM做预训练实现embedding,再通过DNN进行训练,有时间会写写对该模型的认识)这样的模型则是考虑了高阶特征,而在最后sigmoid输出时忽略了低阶特征本身。
鉴于上述理论,目前新出的很多基于深度学习的CTR模型都从wide、deep(即低阶、高阶)两方面同时进行考虑,进一步提高模型的泛化能力,比如DeepFM。
很多文章只是简单对论文进行了翻译,本文重点则在于详细分析模型原理,包括给出论文中略过的模型推导细节,鉴于本人小白,因此如有问题,欢迎各位大牛指出改正。之后会尝试复现论文,当然得等我安好tensorflow再说= =。好了废话不多说,下面开始装逼。
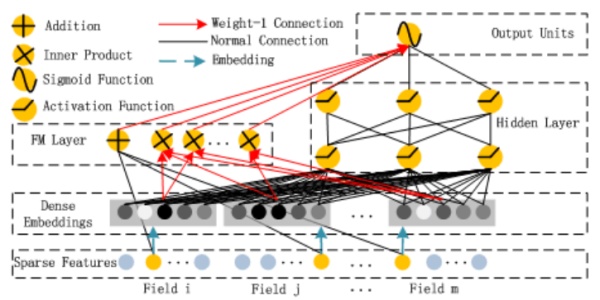
首先给出论文模型图,由于文章画的很好,就直接贴图了:
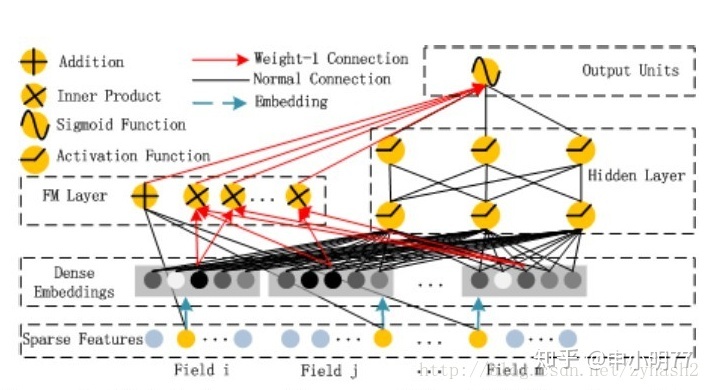
可以看到,整个模型大体分为两部分:FM和DNN。简单叙述一下模型的流程:借助FNN的思想,利用FM进行embedding,之后的wide和deep模型共享embedding之后的结果。DNN的输入完全和FNN相同(这里不用预训练,直接把embedding层看NN的一个隐含层),而通过一定方式组合后,模型在wide上完全模拟出了FM的效果(至于为什么,论文中没有详细推导,本文会稍后给出推导过程),最后将DNN和FM的结果组合后激活输出。
embedding和FM
之所以放在一样说,主要是模型在embedding的过程中,也是借助了FM的方式, 通过隐向量与X的内积运算,将稀疏的X向量转化为K维度的稠密向量,即得到embedding向量数据,用于接下来DNN的输入以及FM的输出,首先说明下二阶FM的形式:
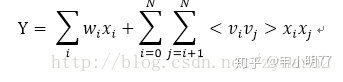
其中向量V就是对应特征的隐向量(不太懂FM可以先学习下该算法)。而在目前很多的DNN模型中,都是借助了FM这种形式来做的embedding,具体推导如下:
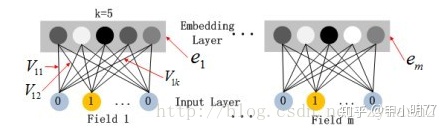
由于CTR的输入一般是稀疏的,因此在第一层隐含层之前,引入一个嵌入层来完成将输入向量压缩到低维稠密向量,
嵌入层(embedding layer)的结构如上图所示。当前网络结构有两个有趣的特性:
1)尽管不同field的输入长度不同,但是embedding之后向量的长度均为K
2)在FM里得到的隐变量Vik现在作为了嵌入层网络的权重,通过FM里面的二阶运算,将稀疏的X输入向量压缩为低纬度的稠密向量
这里的第二点如何理解呢,假设我们的k=5,首先,对于输入的一条记录,经过one-hot编码后,同一个field 只有一个位置是1,那么在由输入得到dense vector的过程中,输入层只有一个神经元起作用,得到的dense vector其实就是输入层到embedding层该神经元相连的五条线的权重,即vi1,vi2,vi3,vi4,vi5。这五个值组合起来就是我们在FM中所提到的Vi。在FM部分和DNN部分,这一块是共享权重的,对同一个特征来说,得到的Vi是相同的。
同样借助原文的图,这里k表示隐向量的维数,Vij表示第i个特征embeding之后在隐向量的第j维。假设我已经给出了V矩阵,

其中第5-15个特征是同一个field经过one-hot编码后的表示,这是隐向量按列排成矩阵,同时,它也可看作embedding层的参数矩阵,按照神经网络前向传播的方式,embedding后的该slot下的向量值应该表示为:

可以看到这个结果就是一个5维的向量,而这个普通的神经网络传递时怎么和FM联系到一起的,仔细观察这个式子可以发现:
- 当特征X进行了离散化或者one-hot编码后,所以对于每一个field的特征而言,截断向量X都只有一个值为1,其他都为0。那么假设上述slot的V中,j为7的特征值为1,那么矩阵相乘之后的结果为:
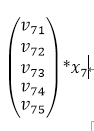
从结果中可以看到,实质上,每个slot在embedding后,其结果都是one-hot后有值的那一维特征所对应的隐向量,FNN也是同样如此。看到这里,在来解释模型中FM部分是如何借助这种方式得到的。回到模型的示意图,可以看到在FM测,是对每两个embedding向量做内积,那么我们来看,假设两个slot分别是第7和第20个特征值为1:
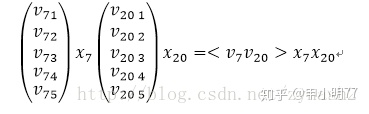
是不是感觉特别熟悉,没错,这个乘积的结果就是FM中二阶特征组合的其中一例,而对于所有非0组合(embedding向量组合)求和之后,就是FM中所有二阶特征的部分,这就是模型中FM部分的由来。
2. 当特征X并没有专门one-hot编码,包含类别和数值变量时,对于输入数据,获取到feature_index, feature_value格式,此时先通过比如embeddinglookup的方式,获取到隐向量W矩阵中对于的向量组w, 然后w * value,因此第2中特征场景下,相比第1种离散化后的情况,多了一步w与feature_value乘积操作(在特征离散化情况下,value为0,1两种值,因此无需再进行w*value操作)
当然,FM中的一阶特征,则直接在embedding之前对于特征进行组合即可,这个很简单,就不解释了。
模型当中的FM中涉及的参数同样会参与到梯度下降中,也就是说embedding层不会只是初始化使用,实质上这里可以理解为是直接用神经网络来做了embedding,无疑他比FM本身的embedding能力来得更强。
DNN
DNN部分就可说的不多了,依然采用了全连接的深度神经网络的方式,只是在最后激活输出时,会对FM和DNN的结果一起做embedding:
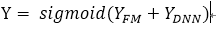
由于像有tensorflow这样的神器存在,搭建一个这样的神经网络模型并非难事(虽然我还没有安好tf),因此大多时候就忽略了模型本身的work方式,比如如何迭代,涉及的参数矩阵包括4个:DNN中每层的W矩阵、DNN中每层的b向量、embedding层的V矩阵(FM的二阶表示V)、FM的一阶表示w。此部分的梯度下降推导笔者会之后补上