LinkedIn 架构笔记
网址:
http://www.dbanotes.net/arch/linkedin.html
现在是
SNS
的春天,最近又有消息
传言新闻集团准备收购 LinkedIn
。有趣的是,LinkedIn 也是
Paypal 黑帮
成员创建的。在最近一个季度,有两个 Web 2.0 应用我用的比较频繁。一个是
Twitter
,另一个就是
LinkedIn
。
LinkedIn 的
CTO
Jean-Luc Vaillant 在 QCon 大会上做了 ”
Linked-In: Lessons learned and growth and scalability
“ 的报告。不能错过,写一则 Blog 记录之。
LinkedIn 雇员有 180 个,在 Web 2.0 公司中算是比较多的,不过人家自从 2006 年就盈利了,这在 Web 2.0 站点中可算少的。用户超过 1600 万,现在每月新增 100 万,50% 会员来自海外(中国用户不少,也包括
我
).
开篇明义,直接说这个议题不讲”监控、负载均衡”等话题,而是实实在在对这样特定类型站点遇到的技术问题做了分享。LinkedIn 的服务器多是 x86 上的 Solaris ,关键 DB 用的是 Oracle 10g。人与人之间的关系图生成的时候,关系数据库有些不合时宜,而把数据放到内存里进行计算就是必经之路。具体一点说,LinkedIn 的基本模式是这样的:前台应用服务器面向用户,中间是DB,而DB的后边还有计算服务器来计算用户间的关系图的。
问题出来了,如何保证数据在各个
RAM
块(也就是不同的计算服务器)中是同步的呢? 需要一个比较理想的数据总线(DataBus)机制。
第一个方式是用 Timestamp . 对记录设置一个字段,标记最新更新时间。这个解决方法还是不错的—除了有个难以容忍的缺陷。什么问题?就是 Timestamp 是 SQL调用发起的时间,而不是 Commit 的确切时间。步调就不一致喽。
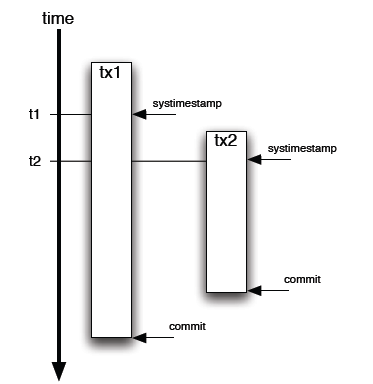
第二个办法,用 Oracle 的 ORA_ROWSCN (还好是 Oracle 10g). 这个伪列包含 Commit 时候的 SCN(System Change Number),是自增的,DB 自己实现的,对性能没有影响。Ora_ROWSCN 默认是数据库块级别的粒度,当然也可做到行级别的粒度。唯一的缺点是不能索引(伪列). 解决办法倒也不复杂:增加一个 SCN 列,默认值”无限大”。然后用选择比某个 SCN 大的值就可以界定需要的数据扔到计算服务器的内存里。
ORA_ROWSCN 是 Oracle 10g 新增的一个特性,不得不承认,我过去忽略了这一点。我比较好奇的是,国内的 Wealink、联络家等站点是如何解决这个关系图的计算的呢?