(译)Pose Flow: Efficient Online Pose Tracking
摘要
无约束视频中的多人关节姿态跟踪是一个既重要又具有挑战性的问题。本文沿着自顶向下的方法,提出了一种基于姿态流的像样高效的姿态跟踪器。首先,我们设计了一个在线优化框架来建立跨帧姿势和形状姿势流的关联(PF-Builder)。其次,设计了一种新的位姿流非最大值抑制算法(PF-NMS),有效地减少了冗余位姿流和时态不相交位姿流的重链接。大量实验表明,我们的方法在两个标准位姿跟踪数据集(分别为[12]和[8])上分别优于
13 mAP 25 MOAT
和
6 mAP 3 MOAT
。此外,在处理单个帧中检测到的姿态时,姿态跟踪器的额外计算非常小,保证了在线
10FPS
跟踪。我们的源代码是公开的
1
。
1 介绍
近年来,由于在人类行为理解和场景分析中的广泛应用,人体姿态估计得到了极大的发展。目前,主流的研究领域已经从单一预定位人的姿态估计[6,14]发展到复杂无约束场景下的多人姿态估计[3,7]。除了个人图像中的静态人体关键点之外,视频中的姿态估计也成为一个突出的话题[17,22]。此外,从整个视频中提取的人体姿态轨迹是一种高层次的人类行为表征[19,20],自然为我们提供了一个强大的工具来处理一系列的视觉理解任务,如动作识别[5]、人的再识别[18,24]、人与物体的交互[9]和许多下游的实际应用。应用,如视频监控和运动视频分析。
为此,发展了多人姿态跟踪方法,其主要方法可分为自上而下[8]和自下而上[11,12]。==自上而下的方法,也称为两步方案,首先检测每个帧中的人的提议,独立估计每个框中的关键点,然后根据相邻帧中框对之间的相似性在整个视频中跟踪人的框,这就是为什么它也被称为检测和跟踪方法[8]。==相比之下,
自底向上的方法,也被称为连接方案,首先在每一帧中生成一组联合检测候选,构建时空图,然后求解一个整数线性规划,将该图分割成与每个人的似是而非的人体姿势轨迹相对应的子图。
1.自顶向下是:在每帧中 检测 人的proposals→关键点→相邻帧相似性 跟踪整个视频;
2.自下而上是:在每帧中 生成 关键点候选点→时空图→求解整数线性规划将时空图分为子图→每个子图对应人体姿势轨迹。
目前,自顶向下的方法在精度( mAP和MOAT)和跟踪速度方面都大大优于自底向上的方法,因为自底向上的方法由于仅仅利用二阶身体部位相关性而失去全局姿态视图,这直接导致关键点的模糊分配,如图1a)所示。此外,联合方案计算量大,无法扩展到长视频,因此无法进行在线跟踪。因此,自上而下的方法可能是一个更有前途的方向。然而,按照这一方向,仍然存在许多挑战。如图1b)c)d)所示,由于帧退化(例如由于快速运动而模糊)、截断或遮挡,单个帧中的姿态估计可能不可靠。为了解决这个问题,我们需要关联跨帧检测实例来共享时间信息,从而减少不确定性。

*
图1:先前姿态估计方法的失败案例,绿色为地面真实,红色为假案例。a)任务不明确。b)缺失检测。c)人为截断。d)人为阻塞
本文提出了一种高效、体面的在线姿态跟踪方法。除了使用改进的RMPE[7]作为姿态估计外,我们提出的方法还包括两种新的技术,即姿态流建立(PF-Builder)和姿态流非极大值抑制(PF-NMS)。首先,我们关联表示同一个人的交叉帧姿态。为了达到这一目的,我们在一个由时间视频滑动窗口选取的短视频片段中,根据姿态建议迭代地构造姿态流。我们设计了一个有效的目标函数来寻找姿态流,而不是贪婪匹配。此优化设计有助于稳定姿态流并关联不连续的姿态流(由于缺少检测)。第二,不同于传统的在帧级应用NMS的方案,PF-NMS在NMS处理中以姿态流为单位。这样,在NMS过程中充分考虑了时间信息,大大提高了系统的稳定性。我们的方法对不同的姿态估计器是通用的,并且只需要很少的额外计算来跟踪。在给定单个帧中检测到的姿态的情况下,我们的方法可以以10 FPS的速度跟踪姿态。
为了验证该框架的有效性,我们在2个标准姿态跟踪数据集:
PoseTrack Dataset
[12]和
PoseTrack Challenge Dataset
[2]上进行了大量的实验。我们提出的方法明显优于最新的方法[8],在PoseTrack Challenge 验证集中达到58.3%的MOTA和66.5%的mAP,在测试集中达到51.0%的MOTA和63.0%的mAP。
2 相关工作
2.1 图像中的多人姿态估计
近年来,图像中的多人姿态估计技术有了很大的发展。对于不同的姿态估计管道,相关工作可以分为图分解和多阶段技术。DeeperCut[10]等图分解方法将多人姿态估计问题重新定义为一个划分和标记公式,并用整数线性规划求解该图分解问题。这些方法的性能在很大程度上取决于基于深度视觉表示的强部件检测器和有效的优化策略。然而,由于缺乏全局上下文和结构信息,它们的身体部位检测器的性能往往是脆弱的。OpenPose[3]引入了Part Affinity Fields (PAFs)来将身体部位与图像中的个体关联起来,但是在群组中仍然会出现不明确的赋值。
为了解决这一局限性,多级流水线[4,7]将多人姿态估计问题分为人体检测阶段、单人姿态估计阶段和后处理阶段。优势多阶段结构的主要区别在于人体检测器和单人姿态估计网络的不同选择。近年来,随着目标检测和单人姿态估计技术的显著进步,多阶段方法的潜力得到了极大的挖掘。现在,多阶段框架已经处于上述方法的中心,在几乎所有的基准数据集中都取得了最新的性能,例如MSCOCO[13]和 MPII[1]。
2.2 视频中的多人关节跟踪
基于上述多人姿态估计器,将其从静止图像扩展到视频是很自然的。CVPR’17中 PoseTrack[12]和 ArtTrack[11]主要介绍了多人姿态跟踪挑战,并在 2D DeeperCut[10]的基础上,通过将空间关节图扩展到时空图,提出了一种新的图形划分公式。尽管通过解决最小成本的多切割问题可以保证合理的结果,但是手工制作的图形模型对于不可见类型的场景的长剪辑是不可伸缩的。值得注意的是,优化这个复杂的IP需要每个视频几十分钟,甚至用最先进的解决方案来实现。
因此,另一个研究方向是探索更有效和可伸缩的自上而下的方法,首先对每个帧进行多人姿态估计,然后根据外观相似性和检测框之间的时间关系将其连接起来。但仍需妥善处理的问题有:1)如何在融合相邻帧信息的情况下正确过滤冗余框;2)如何利用时间信息产生鲁棒的姿态轨迹;3)如何在不受尺度方差干扰的情况下,将具有相同身份的人体框连接起来。
尽管最近的一项工作3D Mask R-CNN[8]试图解决这些问题,但它并没有将姿态流作为一个单元,该工作旨在通过利用3D人体管中的时间信息来校正关键点的位置。此外,该跟踪器只是将跟踪问题简化为一个最大权二部匹配问题,并用贪婪算法或匈牙利算法求解。此二部图的节点是两个相邻帧中的人类边界盒。这种配置没有考虑运动和姿势信息,这对于跟踪偶尔被截短的人是至关重要的。为了解决这一局限性,同时保持其效率,我们提出了一种新的姿态流生成器,将姿态流生成器和姿态流非极大值抑制 (Pose Flow Builder and Pose Flow NMS)相结合。
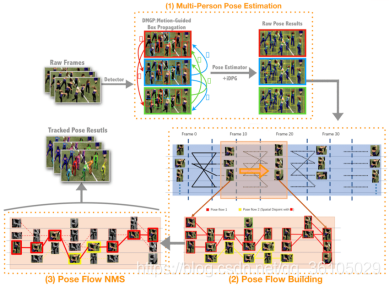
*
图2:总体管道:1)姿态估计器。2)姿态流生成器。3)姿态流NMS。首先,我们估计多人姿势。其次,我们通过最大化整体置信度来构建姿态流,并通过姿态流NMS来净化它们。最后得到合理的多姿态轨迹。
3 我们提议的方法
在本节中,我们将介绍我们的姿势跟踪管道。如前所述,pose flow是指在不同帧中指示同一个人实例的一组姿势。如图2所示,我们的框架包括两个步骤:Pose Flow Building和Pose Flow NMS。首先,我们通过在时间序列上最大化整体置信度来建立姿态流。其次,利用姿态流网络管理系统减少冗余姿态流,重新链接不相交姿态流。
3.1 初步
在本节中,我们将介绍一些将在我们的框架中使用的基本度量和工具。
帧内姿态距离(Intra-Frame Pose Distance)
:定义帧内姿势距离,以测量帧中两个姿势
P
1
P_1
P
1
和
P
2
P_2
P
2
之间的相似度。我们采用[7]中定义的姿态距离。我们将
p
1
n
p_1^n
p
1
n
和
p
2
n
p_2^n
p
2
n
分别表示为
P
1
P_1
P
1
和
P
2
P_2
P
2
位姿的第n个关键点,n∈{1,2…,N},N是一个人的关键点数,
B
(
p
1
n
)
B(p_1^n)
B
(
p
1
n
)
是以
p
1
n
p_1^n
p
1
n
为中心的人体框,
c
1
n
c_1^n
c
1
n
是
p
1
n
p_1^n
p
1
n
的得分。
t
a
n
h
tanh
t
a
n
h
函数是用来抑制低分数的关键点。软匹配函数定义为:
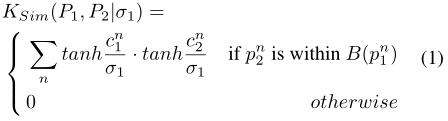
关键点之间的空间相似性:
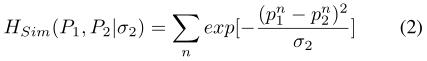
结合eq.1和eq.2最终相似度为:
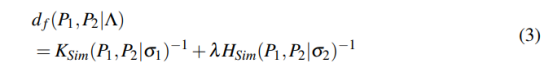
w
h
e
r
e
Ʌ
=
{
σ
1
,
σ
2
,
λ
}
where Ʌ= \{ σ_1,σ_2,λ \}
w
h
e
r
e
Ʌ
=
{
σ
1
,
σ
2
,
λ
}
这些参数可以用数据驱动的方式确定。
**帧间姿态距离(Inter-frame Pose Distance):**帧间姿势距离是测量一帧中的姿势
P
1
P_1
P
1
和下一帧中的另一个姿势
P
2
P_2
P
2
之间的距离。
我们需要导入时间匹配来测量两个交叉帧姿势表示同一个人的可能性。提取围绕
p
1
n
p_1^n
p
1
n
和
p
2
n
p_2^n
p
2
n
的边界框,并将其表示为
B
1
n
B_1^n
B
1
n
和
B
2
n
B_2^n
B
2
n
。根据标准PCK[1],框大小为10%人体边界框大小。我们评估了
B
1
n
B_1^n
B
1
n
和
B
2
n
B_2^n
B
2
n
的相似性。给定从
B
1
n
B_1^n
B
1
n
中提取的
f
1
n
f_1^n
f
1
n
深度匹配特征[16]点,我们可以找到
f
2
n
f_2^n
f
2
n
是
B
2
n
B_2^n
B
2
n
中的匹配点。匹配百分比
f
1
n
f
2
n
\frac{f_1^n}{f_2^n}
f
2
n
f
1
n
可以表示
B
1
n
B_1^n
B
1
n
和
B
2
n
B_2^n
B
2
n
的相似性。因此
P
1
P_1
P
1
和
P
2
P_2
P
2
之间的帧间姿势距离可以表示为:

3.2 改进的多人姿态估计
我们采用RMPE[7]作为多人姿态估计器,以更快的R-CNN[15]作为人体检测器,以PRMs[21]作为单人姿态估计器的沙漏网络。我们的管道准备采用不同的人类探测器和姿态估计器。
数据增广(Data AugmentationData Augmentation)
:在视频场景中,人们总是进出视频采集区域,导致截取问题。为了处理人类的截断问题,我们提出了一种改进的深度建议生成器(idpg)作为数据增强方案。idpg的目标是在训练过程中使用随机裁剪策略产生截短的人体提议。具体地说,我们将人类实例区域随机分成四分之一或半个人。因此,这些随机裁剪建议将用作增强训练数据。我们观察到RMPE在应用于视频帧时的改进。
运动传播(Motion-guided propagation)
:由于运动模糊和遮挡等原因,人体检测过程中经常会出现漏检现象。如表4.1所示,这将增加人员ID开关(IDs↓),显著降低最终跟踪MOTA的性能。我们的想法是通过交叉帧匹配技术将框建议传播到上一帧和下一帧。也就是说,盒子提议是三倍。这样,一些漏检的方案恢复的几率很高,召回率也大大提高(冗余框将通过以下步骤过滤掉)。我们使用的交叉帧匹配技术是deepmatching[16]。
3.3 姿态流建立
首先对每个帧进行姿态估计。姿态流是通过在帧之间关联表示同一个人的姿势来构建的。直接向前的方法是通过在下一帧中选择最近的姿势来连接它们,给定度量
d
c
(
P
1
,
P
2
)
d_c(P1,P2)
d
c
(
P
1
,
P
2
)
。然而,由于帧级姿态检测的识别错误和虚警,这种贪婪方案的效果较差。另一方面,如果将图割模型应用于时空域,将导致计算量大、解不在线。因此,本文提出了一种高效体面的高质量位姿流生成方法。
我们将
P
i
j
P_i^j
P
i
j
表示为第j帧的第i个姿势,其候选关联集表示为
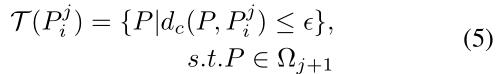
其中
Ω
j
+
1
Ω_{j+1}
Ω
j
+
1
是在(j+1)帧处的姿势集。在论文中,我们通过交叉验证设置了
ε
=
1
25
\varepsilon=\frac{1}{25}
ε
=
2
5
1
。
τ
(
P
i
j
)
\tau(P_i^j)
τ
(
P
i
j
)
表示在下一帧中为
P
i
j
P_i^j
P
i
j
设置的可能的对应姿势。在不丧失通用性的前提下,讨论了
P
i
t
P_i^t
P
i
t
的跟踪问题,并考虑了从t帧到(t+T)帧的位姿流建立问题。为了优化姿态选择,我们将以下目标函数最大化
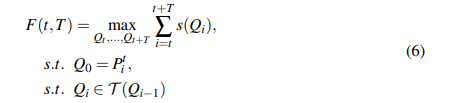
其中
s
(
Q
i
)
s(Qi)
s
(
Q
i
)
是输出
Q
i
Q_i
Q
i
置信度的函数,定义为
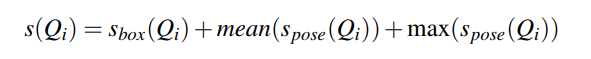
其中
S
b
o
x
(
P
)
S_{box}(P)
S
b
o
x
(
P
)
、
m
e
a
n
(
S
p
o
s
e
(
P
)
)
mean(S_{pose}(P))
m
e
a
n
(
S
p
o
s
e
(
P
)
)
和
m
a
x
(
S
p
o
s
e
(
P
)
)
max(S_{pose}(P))
m
a
x
(
S
p
o
s
e
(
P
)
)
分别是此人体建议中所有关键点的人体框得分、平均得分和最大得分。最佳的
{
Q
t
,
.
.
.
,
Q
t
+
T
}
\{Q_t,…,Q_{t+T}\}
{
Q
t
,
.
.
.
,
Q
t
+
T
}
是我们从t帧到(t+T)帧的
P
i
t
P_i^t
P
i
t
姿势流。
分析
: 我们把置信度得分之和
(
∑
i
=
t
t
+
T
s
(
Q
i
)
)
(\sum_{i=t}^{t+T}s(Q_i))
(
∑
i
=
t
t
+
T
s
(
Q
i
)
)
作为目标函数。这种设计有助于我们抵御许多不确定性。当一个人被高度遮挡或模糊时,它的分数很低,因为模型对它没有信心。但是我们仍然可以建立一个姿势流来补偿它,因为我们看的是姿势流的总体置信度得分,而不是一个单独的帧。此外,可以在线计算置信度得分之和。也就是说,
F
(
t
,
T
)
F(t , T)
F
(
t
,
T
)
可由
F
(
t
,
T
−
1
)
F(t , T-1)
F
(
t
,
T
−
1
)
和
s
(
Q
T
)
s(Q_T)
s
(
Q
T
)
确定。
解算器
: eq.6是一个标准的动态规划问题,可以在线求解。在(u-1)帧处,我们有
m
u
−
1
m_{u-1}
m
u
−
1
个可能的姿势,并记录
m
u
−
1
m_{u-1}
m
u
−
1
个最佳姿势的轨迹(分数总和)以达到它们。在第u帧,我们根据先前的
m
u
−
1
m_{u-1}
m
u
−
1
最佳姿态轨迹计算到
m
u
m_u
m
u
可能姿势的最佳路径。相应地,更新
m
u
m_u
m
u
轨迹。
F
(
u
)
F(u)
F
(
u
)
是最佳姿势轨迹的分数之和。
3.3.1停止准则与置信度统一
我们用公式6逐帧处理视频,直到它满足停止标准。我们的标准并不是简单地检查单个帧的置信度,而是观察更多帧来抵抗突然的遮挡和帧退化(例如运动模糊)。因此,当
F
(
t
,
u
+
r
)
-
F
(
t
,
u
)
<
γ
F(t ,u+r)-F(t , u)< γ
F
(
t
,
u
+
r
)
-
F
(
t
,
u
)
<
γ
时,位姿流在u处停止,其中γ由交叉验证确定。这意味着在下面的r帧内的得分之和非常小。只有这样,我们才能确保姿势流真正停止。在我们的论文中,我们将设
r
=
3
r=3
r
=
3
。姿势流停止后,所有关键点的置信度都由平均置信度得分更新。我们认为位姿流应该是基本块,应该用单置信值来表示。这个过程被称为信心统一。
3.4 位姿流NMS
我们希望我们的NMS可以在时空域中执行,而不是单独的帧处理。也就是说,在NMS处理中,我们以位姿流中的位姿为单位,通过空间和时间信息来减少误差。关键步骤是确定表示同一个人的两个姿势流之间的距离。
姿态流距离(Pose Flow Distance):
给定两个位姿流
y
a
y_a
y
a
和
y
b
y_b
y
b
,我们可以提取它们的时间重叠子流。子流表示为
{
P
a
1
,
.
.
.
,
P
a
N
}
a
n
d
{
P
b
1
,
.
.
.
,
P
b
N
}
\{P_a^1,…,P_a^N\}and\{P_b^1,…,P_b^N\}
{
P
a
1
,
.
.
.
,
P
a
N
}
a
n
d
{
P
b
1
,
.
.
.
,
P
b
N
}
其中N是时间重叠帧的数目。也就是说,
P
a
i
a
n
d
P
b
i
P_a^iandP_b^i
P
a
i
a
n
d
P
b
i
是同一帧中的两个姿势。
y
a
y_a
y
a
和
y
b
y_b
y
b
之间的距离可以算作
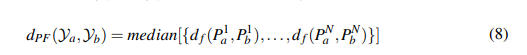
其中
d
f
(
⋅
)
d_f(·)
d
f
(
⋅
)
是等式3中定义的帧内姿势距离。中值度量对于异常值(如遮挡和运动模糊引起的漏检)更为稳健。
姿态流合并(Pose Flow Merging)
: 给定
d
P
F
(
⋅
)
d_{PF}(·)
d
P
F
(
⋅
)
,可以将NMS格式作为对流管道来实现。首先,选择置信度得分最大(置信度统一后)的姿态流作为参考姿态流。利用
d
P
F
(
⋅
)
d_{PF}(·)
d
P
F
(
⋅
)
,我们将位姿流与参考位姿流进行分组。因此,组中的姿势流将被合并为表示组的更健壮的姿势流。这种新的位姿流(位姿流NMS结果)称为代表位姿流。计算了第t帧中具有代表性姿态流的第i个关键点
x
t
,
i
x_{t,i}
x
t
,
i
的二维坐标和置信度
s
t
,
i
s_{t,i}
s
t
,
i
。
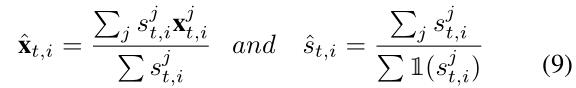
其中
x
t
,
i
j
a
n
d
s
t
,
i
j
x_{t,i}^jands_{t,i}^j
x
t
,
i
j
a
n
d
s
t
,
i
j
为t帧中该组第j姿势流中第i个关键点的二维坐标和置信度得分。如果第j位姿流在第t帧处没有任何位姿,则将设置
s
t
,
i
j
=
0
s_{t,i}^j=0
s
t
,
i
j
=
0
。在等式9中,如果输入为非零,则
ỻ
(
s
t
,
i
j
)
ỻ(s_{t,i}^j)
ỻ
(
s
t
,
i
j
)
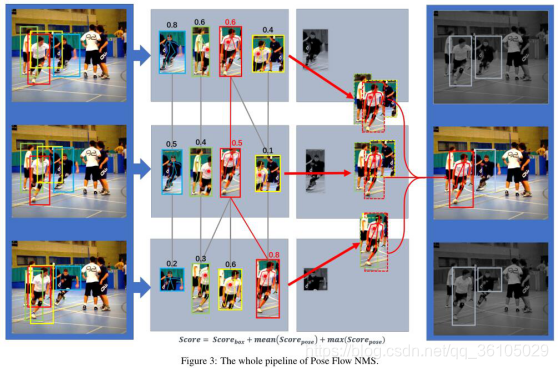
,输出1,否则输出0。该合并步骤不仅可以减少冗余姿态流,而且可以将一些不相交的姿态流重新链接到一个较长且完整的姿态流中。交叉帧姿势合并(关键点级别)的详细信息可以参考图3。
我们重新执行此过程,直到处理完所有姿势流。这个过程是在滑动时间窗中计算的(本文的窗长为L=20)。因此,这是一个在线过程。整个管道如图2所示。
4 实验和结果
4.1 评估和数据集
为了与最先进的自顶向下和自下而上方法进行比较,我们分别评估了
PoseTrack
和
PoseTrack Challenge
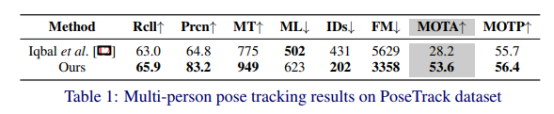
数据集上的框架。文献[12]引入PoseTrack Dataset,对时空图切割方法进行了评价。此数据集中的标记帧来自MPII多人姿势数据集[1]的连续未标记相邻帧。这些选定的视频包含多人,涵盖了复杂情况下的多种活动,如尺度变化、身体截断、严重遮挡和运动模糊等。为了进行公平的比较,我们在30个训练视频上训练改进的RMPE,并像PoseTrack[12]那样在其余30个视频上测试它。表4.1给出了PoseTrack dataset中的跟踪结果,以及表3中的姿态估计结果。结果表明,我们的方法在
13.5mAP和25.4MOTA
上都优于最好的图割方法。
*
表1:posetrack数据集上的多人姿势跟踪结果
PoseTrack Challenge数据集在[2]中发布。像PoseTrack数据集一样被选择和注释,它包含更多的视频。测试数据集评估包括三个任务,但我们只加入了 Task2-Multi-Frame 人体姿态估计、平均精度(mAP)评估和 Task3-Pose跟踪、多目标跟踪精度(MOTA)评估。验证集和PoseTrack Challenge数据集的测试集的跟踪结果如表2所示。我们的方法可以在测试集上获得最新的验证结果和可比较的结果。一些定性结果如图4所示。
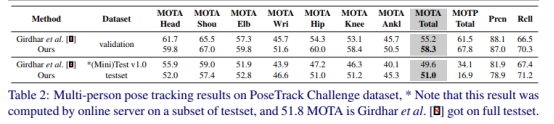
表2:posetrack challenge数据集上的多人姿势跟踪结果,请注意,*该结果是由testset子集上的联机服务器计算的,51.8 MOTA是Girdhar等人的。[8]进入完整测试集
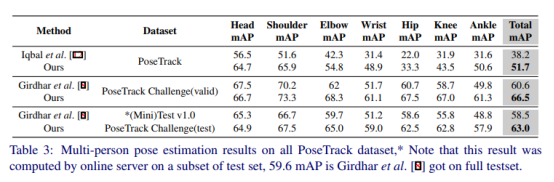
表3:所有posetrack数据集上的多人姿势估计结果,*请注意,该结果是由在线服务器在测试集的子集上计算的,59.6 mAP是Girdhar等人的。[8]进入完整测试集。
时间性能(Time Performance)
我们提出的姿态跟踪器是基于在单个帧中产生的姿态。也就是说,它可以应用于不同的多人姿态估计。我们的姿态跟踪器的额外计算非常小,每帧只需要100毫秒。因此,相对于姿态估计的速度而言,它不会成为整个系统的瓶颈。
4.2 培训和测试细节
本文采用基于ResNet152的Faster R-CNN作为人体检测器。由于缺少人工建议注释,我们通过将人的关键点边界沿高度和宽度方向扩展20%来生成人体检测框,用于对人检测器进行微调。在单人姿势估计训练阶段,我们使用在线困难样本挖掘(OHEM)来处理臀部和脚踝等困难关键点。对于每一次迭代,不必在小批量中采样最大的B/N losses,而是选择k个困难示例的最大损失。选择后,SPPE仅从困难关键点更新权重。这些方法增加了少量的计算时间,但显著提高了髋关节和踝关节的估计性能。
4.3 消融研究(Ablation Studies)
我们评估了四个建议组件的有效性:对基于深度匹配的运动引导盒传播(DMGP)、改进的深度建议生成器(IDPG)、姿态流生成器(PF – Builder)和姿态流NMS(PF-NMS)。消融研究是在验证PoseTrack Challenge数据集的基础上进行的,方法是将这些模块从管道中移除或替换为原始解算器,即我们将基于PF的跟踪器替换为[8]使用的基于box IoU的最大权重二分匹配跟踪器(IoU跟踪器)。
PF-Builder和PF-NMS
PF-Builder负责构造姿势流。由于它是全局最优解,如表4所示,即使没有PF-NMS,它也能保证比IoU-Tracker更好的跟踪性能。PF-NMS能够很好地融合冗余的位姿流和不相交的时态流,可以同时对位姿估计和跟踪结果进行平滑 1.9mAP和2.5 MOTA。
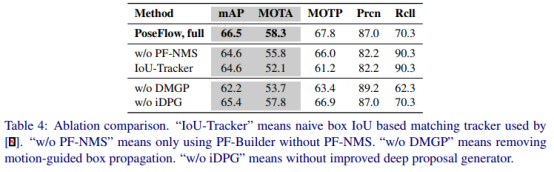
表4:消融比较。“IOU跟踪器”是指[8]使用的基于IOU的原始框匹配跟踪器。“w/o PF-NMS”是指仅使用PF-builder而不使用PF-NMS。“w/o DMGP”是指去除运动引导盒传播。“w/o iDGP”是指没有改进的deep建议生成器。
DMGP和iDPG
DMGP用于双向传播相邻检测框以恢复丢失的检测框,因此该模块可以通过显著降低IDs来提高4.6MOTA的跟踪性能。由于检测的高召回率可以充分利用RMPE框架[7]中PoseNMS模块的强大功能,4.3mAP也因此得到了提高。iDPG的主要目标是更精确地定位困难关键点,因为姿态信息在跟踪过程中也被利用,iDPG最终将结果提高了1.1mAP和0.5MOTA。

*
图4:视频中的一些最终posetracking结果
5 结论
提出了一种可扩展的、高效的自顶向下姿态跟踪器,该跟踪器主要利用时空信息建立姿态流,显著提高姿态跟踪任务。提出了位姿流生成器和位姿流网络管理系统两种新技术。在消融研究中,我们证明PF-Builder、PF-NMS、iDPG和DMGP的结合可以保证姿态跟踪任务的显著改善。此外,我们提出的位姿跟踪器能够以每秒10帧的速度处理视频中的帧(不包括帧中的位姿估计),在实际应用中具有很大的潜力。在未来的研究中,我们将分析基于姿势跟踪器的长期动作识别和场景理解。
参考链接:
论文:
https://arxiv.org/abs/1802.00977
GitHub实现:
https://github.com/MVIG-SJTU/AlphaPose/tree/master/PoseFlow
https://blog.csdn.net/Gavinmiaoc/article/details/89917176
https://blog.csdn.net/github_36923418/article/details/84984772
https://blog.csdn.net/zhangjunhit/article/details/79524796
https://blog.csdn.net/cv_family_z/article/details/79579173