接着
https://blog.51cto.com/mapengfei/2554700
输出到kafka和文件,这2种都是只支持追加模式,那要实现 撤回模式(Retract)和更新插入模式(upsert),大部分场景是在操作数据库中,像mysql,es,mongo等,这里实现下输入到mysql和es
再贴一下集中模式的区别:
-
追加模式(Append)–文件系统只支持追加模式
表只做插入操作,和外部连接器只交换插入(insert)消息 -
撤回模式(Retract)–先删除再插入,实现更新操作
表和外部连接器交换添加(Add)和撤回(Retract)消息 - 插入操作(insert)编码为add消息;删除(delete)编码为retract消息;更新(update)编码为上一条的retract和下一条的add消息
-
更新插入模式(upsert)
更新和插入都被编码为upsert消息;删除编码为delete消息
输出到mysql
启动一个mysql服务器,新建数据库test_mafei,里面建一张表用来存储输出数据
DROP TABLE IF EXISTS `sensor_count`;
CREATE TABLE `sensor_count` (
`id` varchar(1000) COLLATE utf8_unicode_ci DEFAULT NULL,
`counts` bigint(20) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;
SET FOREIGN_KEY_CHECKS = 1;
2 上代码(关于环境准备可以参考之前的文章)
package com.mafei.apitest.tabletest
import org.apache.flink.streaming.api.scala._
import org.apache.flink.table.api.DataTypes
import org.apache.flink.table.api.scala._
import org.apache.flink.table.descriptors.{Csv, Elasticsearch, FileSystem, Json, Schema}
object MysqlOutputTest {
def main(args: Array[String]): Unit = {
//1 、创建环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val tableEnv = StreamTableEnvironment.create(env)
//2、读取文件
val filePath = "/opt/java2020_study/maven/flink1/src/main/resources/sensor.txt"
tableEnv.connect(new FileSystem().path(filePath))
.withFormat(new Csv()) //因为txt里头是以,分割的跟csv一样,所以可以用oldCsv
.withSchema(new Schema() //这个表结构要跟你txt中的内容对的上
.field("id", DataTypes.STRING())
.field("timestamp", DataTypes.BIGINT())
.field("temper", DataTypes.DOUBLE())
).createTemporaryTable("inputTable")
val sensorTable = tableEnv.from("inputTable")
//做简单转换
val simpleTramsformTable = sensorTable
.select("id,temper")
.filter("id='sensor1'")
//聚合转换
val aggTable = sensorTable
.groupBy('id)
.select('id, 'id.count as 'count)
//直接打印输出效果:
simpleTramsformTable.toAppendStream[(String, Double)].print("simpleTramsformTable: ")
// 写到mysql中
val sinkMysql : String =
"""
|create table mysqlOutput (
| id varchar(20) not null,
| counts bigint not null
| ) with (
| 'connector.type' = 'jdbc',
| 'connector.url' = 'jdbc:mysql://10.0.0.97:3306/test_mafei',
| 'connector.table' = 'sensor_count',
| 'connector.driver' = 'com.mysql.jdbc.Driver',
| 'connector.username' = 'root',
| 'connector.password' = ''
| )
|""".stripMargin
tableEnv.sqlUpdate(sinkMysql)
aggTable.insertInto("mysqlOutput")
env.execute("esOutputTest")
}
}
代码结构及运行效果
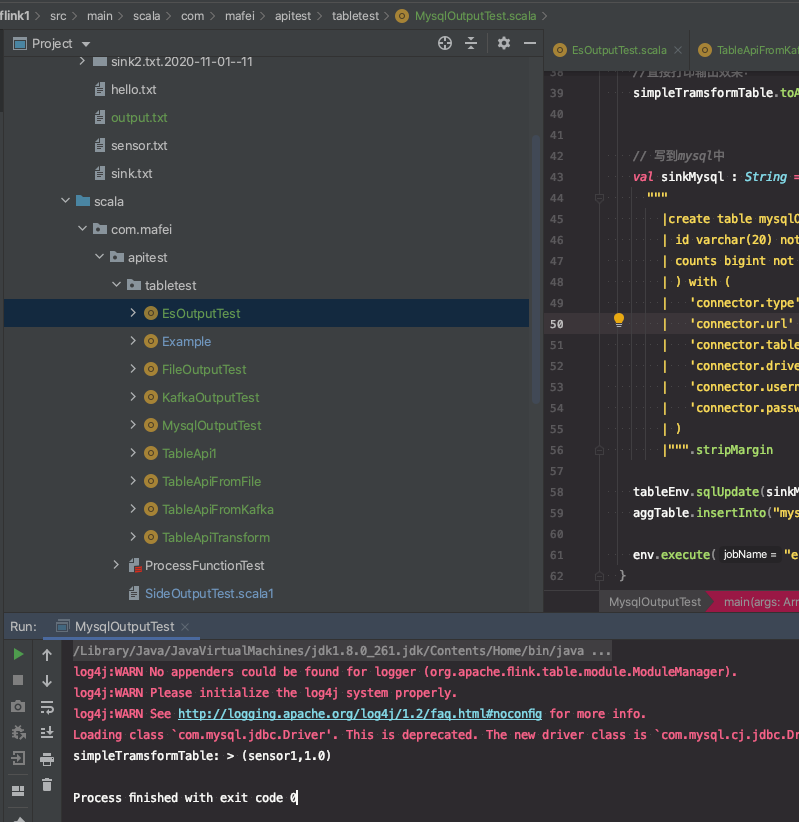
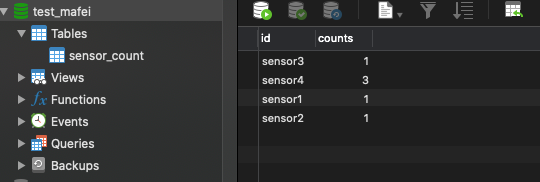
mysql中的数据
第二种,输出到elasticsearch中
在pom.xml中增加依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>1.10.1</version>
</dependency>package com.mafei.apitest.tabletest
import org.apache.flink.streaming.api.scala._
import org.apache.flink.table.api.{DataTypes, Table}
import org.apache.flink.table.api.scala._
import org.apache.flink.table.descriptors.{Csv, Elasticsearch, FileSystem, Json, Schema}
object EsOutputTest {
def main(args: Array[String]): Unit = {
//1 、创建环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val tableEnv = StreamTableEnvironment.create(env)
//2、读取文件
val filePath = "/opt/java2020_study/maven/flink1/src/main/resources/sensor.txt"
tableEnv.connect(new FileSystem().path(filePath))
.withFormat(new Csv()) //因为txt里头是以,分割的跟csv一样,所以可以用oldCsv
.withSchema(new Schema() //这个表结构要跟你txt中的内容对的上
.field("id", DataTypes.STRING())
.field("timestamp", DataTypes.BIGINT())
.field("temper", DataTypes.DOUBLE())
).createTemporaryTable("inputTable")
val sensorTable = tableEnv.from("inputTable")
//做简单转换
val simpleTramsformTable = sensorTable
.select("id,temper")
.filter("id='sensor1'")
//聚合转换
val aggTable = sensorTable
.groupBy('id)
.select('id, 'id.count as 'count)
//直接打印输出效果:
simpleTramsformTable.toAppendStream[(String, Double)].print("simpleTramsformTable: ")
// 写到es中
tableEnv.connect( new Elasticsearch()
.version("7")
.host("localhost", 9200, "http")
.index("sensor_test")
.documentType("temperature")
)
.inUpsertMode()
.withFormat(new Json())
.withSchema(
new Schema()
.field("id", DataTypes.STRING())
.field("count", DataTypes.BIGINT())
)
.createTemporaryTable("esOutputTable")
aggTable.insertInto("esOutputTable")
env.execute("esOutputTest")
}
}
代码结构及运行效果:
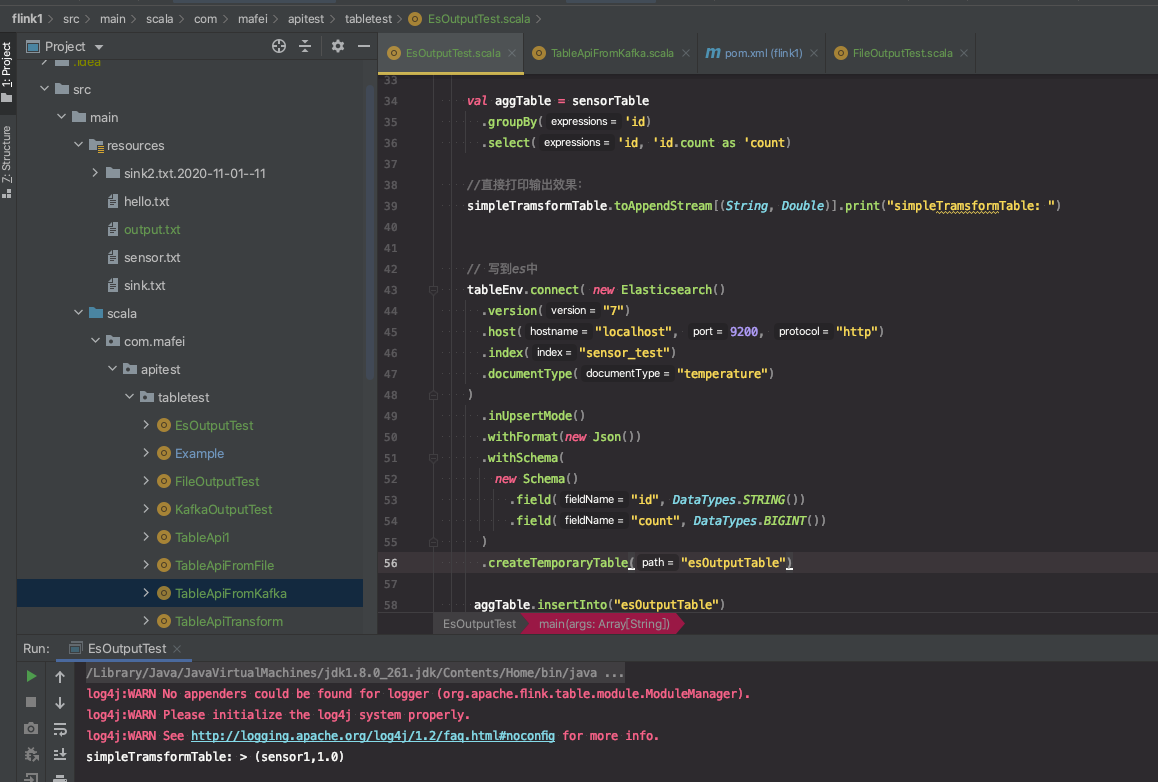
查es的数据:
# 查看下es有多少索引,可以看到多了个sensor_test的索引
[root@node71 yum.repos.d]# curl http://127.0.0.1:9200/_cat/indices
yellow open sensor_test stoACXcQRl66Xnpcu4e4AQ 1 1 4 2 10.6kb 10.6kb
# 查询数据
[root@node71 yum.repos.d]# curl http://127.0.0.1:9200/sensor_test/_search?pretty
{
"took" : 86,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "sensor_test",
"_type" : "_doc",
"_id" : "sensor1",
"_score" : 1.0,
"_source" : {
"id" : "sensor1",
"count" : 1
}
},
{
"_index" : "sensor_test",
"_type" : "_doc",
"_id" : "sensor2",
"_score" : 1.0,
"_source" : {
"id" : "sensor2",
"count" : 1
}
}
}
]
}
}
版权声明:本文为oMaFei原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。