我们知道,innodb的一个页是16K(16*1024=16384字节),如果一条记录占的字节数大于16K,意味着一个页无法装下一条记录,这种情况下mysql是如何处理的呢?
在回答这个问题之前我们先来做一个实验:
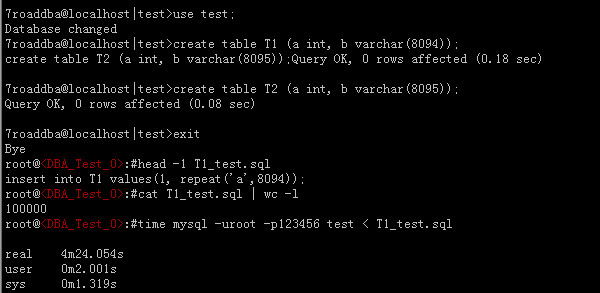
我们创建了两张表,分别是T1和T2,T1和T2唯一的区别是在于b字段一个是varchar(8094),另一个是varchar(8095),然后我们有一个T1_test.sql文件,该文件包含有10W行“insert into T1 values(1,repeat(‘a’,8094));”条sql语句,我们导入到表里花费了4分24秒。
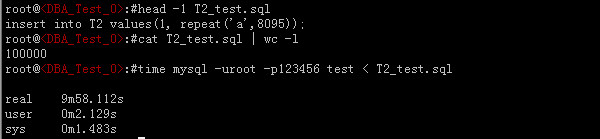
接着我们把T2_test.sql导入T2表中(T2.test.sql同样也包含了10W行类似的sql语句),花费了9分58秒!
我们再来看这两个表文件的空间占用情况(本实例开启了innodb_file_per_talbe):

可以看到T1表占用804M,T2表占用空间1.9G,空间及时间差异均超过2倍。
为什么相差一个字符时间和空间相差会如此巨大呢?下面我们一起剖析下。
在innodb存储引擎里,将一条记录中的某些数据存储在真正的数据页面之外称之为行溢出数据,一般认为blob、text这类的大对像列的存储会把数据存放在数据页面之外。但从上述我们的实验看出,除了blob、text这类大对像列以外,varchar类型似乎也会采用行溢出的方法来存储数据。
Innodb存储引擎表是索引组织的,即B+树的结构,因此每个页中至少应该有两个行记录(否则失去了B+树的意义,变成链表了),如果页中只能存放下一条记录,那么InnoDB存储引擎会自动将行数据存放到溢出页中,以使每个页最少能存放两个行记录或以上。
下面借助姜承尧先生写的py_innodb_page_info工具来证实T2发生了行溢出(点击这里可取得该工具源代码)
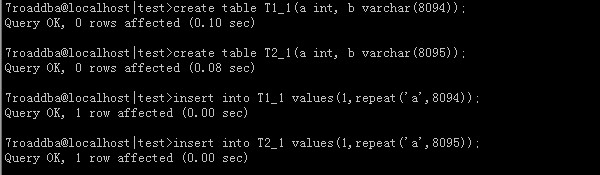
为了更清晰的分析原因,下面我们分别创建T1_1和T2_1表,其b字段也相差1字符,然后分别往这两个表插入一条记录,如下图所示:
此时我们通过py_innodb_page_info工具分析T1_1表的情况
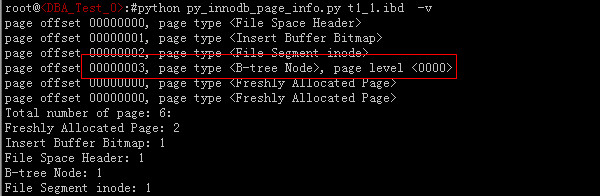
上图说明表T1_1只包含了一个B-tree,我们再看看T2_1的情况:
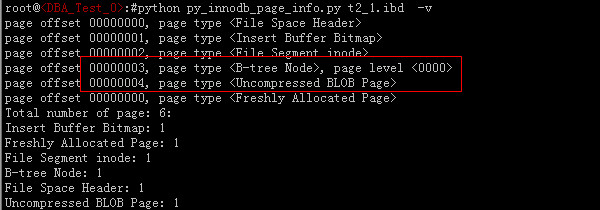
我们看到T2_1表比T1_1表多了一页“Uncompressed BLOB Page”的页,这也充分说明了插到T2_1个的记录分了两页存储,其中一页是BLOB页。
在上述的实验中,我们故意采取了两个字段,一个字段是4字节的int,另一个字段是varchar(8094),两者加起来即8098,也就说,当一个表的字段总大小数大于8098时,插入一条记录即会分裂成两页存储,故无论时间还是空间方面都大打折扣,有兴趣的读者可尝试下用一个或多个字段大小总和<=8098及>8098来做对比。
大家在实验过程中要注意一点的是,当varchar小于255时,会额外用1个字节来记录该记录的实际长度,当varchar大于255时会用2个字节,因为时使用多个变长字段实验时,要注意其总大小要加上该空间。例如:“create table A1(a int, b varchar(2000), c varchar(3000), d varchar(3090));”那么此时的临界值就是4+2000+3000+3090=8090,因为相对于我们上述的实验,A1这个表多了两个大于255的varchar字段,因此需要额外的2+2=4字节来记录变长字段。