目录
3、ArrayList源码分析
LinkedList
3、ArrayList源码分析
3.1 ArrayList继承结构和层次关系
LinkedList
3.1 ArrayList继承结构和层次关系
3.4.2、add(int index, E element) :在指定位置插入新元素
3.4.4、E remove(int index)移除指定节点
3.4.5、boolean remove(Object o) 删除链表中的指定节点
3.4.7、 int indexOf(Object o) 根据节点对象,查询下标
3.4.8、 int lastIndexOf(Object o) 从尾至头遍历链表,找到目标元素值为o的节点
1、LinkedList简介
LinkedList是List接口的另一种实现,它的底层是基于
双向链表
实现的,因此它具有插入删除快而查找修改慢的特点。此外,通过对双向链表的操作还可以实现队列和栈的功能。
LinkedList 是
线程不安全的
,需要同步的应用(ConcurrentLinkedDeque高效的队列)。
允许元素为null的双向链表
。
可以作为一个双端队列
。和ArrayList比,没有实现RandomAccess所以其以下标,随机访问元素速度较慢。
因其底层数据结构是链表,所以可想而知,它的
增删只需要移动指针即可,故时间效率较高
。不需要批量扩容,也不需要预留空间,所以空间效率比ArrayList高。
缺点就是需要
随机访问元素时,时间效率很低
,虽然底层在根据下标查询Node的时候,会根据index判断目标Node在前半段还是后半段,然后决定是顺序还是逆序查询,以提升时间效率。不过随着n的增大,总体时间效率依然很低。
2、LinkedList数据结构

其中的节点Node主要由三部分组成;pre:前驱引用,ele1:节点信息,next:后驱引用。还有两个引用,分别指向头结点的first和指向尾结点的last。
3、LinkedList源码分析
3.1 LinkedList继承结构和层次关系
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable{
}结构图更直观些:

分析:
- LinkedList 是一个继承于AbstractSequentialList的双向链表。
- LinkedList 可以被当作堆栈、队列或双端队列进行操作。
- LinkedList 实现 List 接口,所以能对它进行队列操作。
- LinkedList 实现 Deque 接口,能将LinkedList当作双端队列使用。
- LinkedList 实现了Cloneable接口,即覆盖了函数clone(),能克隆。
- LinkedList 实现java.io.Serializable接口,所以LinkedList支持序列化,能通过序列化去传输。
- LinkedList 是非同步的。
3.2、类中属性
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
//元素个数
transient int size = 0;
//指向第一个节点
transient Node<E> first;
//指向最后一个节点
transient Node<E> last;
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
}LinedList的字段比较少,多添加了两个引用first和last用来指向头尾节点,和一个size用来存储节点的个数,这样当计算元素个数的时候,只需要O(1)的时间复杂度。
3.3、构造方法
1)、无参构造
// 默认构造函数
public LinkedList() {
}2)、带集合参数的构造
// 创建一个LinkedList,保护Collection中的全部元素。
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
3.4、核心方法
offer(E e):在链表尾部插入一个元素
offerFirst(E e):JDK1.6版本之后,在头部添加; 特有方法pollFirst():删除头; 特有方法
pollLast():删除尾; 特有方法
poll():查询并移除第一个元素 特有方法
push(E e):与addFirst方法一致
pop():和removeFirst方法一致,删除头
get(int index):按照下标获取元素; 通用方法
getFirst():获取第一个元素; 特有方法
getLast():获取最后一个元素; 特有方法
peek():获取第一个元素,但是不移除; 特有方法
peekFirst():获取第一个元素,但是不移除;
peekLast():获取最后一个元素,但是不移除
add(E e):在链表后添加一个元素; 通用方法
add(int index, E element):在指定位置插入一个元素。
addFirst(E e):在链表头部插入一个元素; 特有方法
addLast(E e):在链表尾部添加一个元素; 特有方法remove() :移除链表中第一个元素; 通用方法
remove(E e):移除指定元素; 通用方法
removeFirst(E e):删除头,获取元素并删除; 特有方法
removeLast(E e):删除尾; 特有方法
add()方法(有六个)
-
boolean add(E e):在
链表后添加一个元素
,如果成功,返回true,否则返回false; -
void add(int index, E element):在
指定位置插入一个元素
。 - void addFirst(E e):在链表头部插入一个元素;
- addLast(E e):在链表尾部添加一个元素;
- boolean addAll(Collection<? extends E> c):将集合元素插入链表中;
- boolean addAll(int index, Collection<? extends E> c)
3.4.1、add(E e)
注意切记
第一:记录下待插入节点的前置节点;
第二:新建节点的前置 分为 空 和 非空 两种情况。
新增时包含元素为空和不为空两种情况
-
记录末尾节点
-
新建末尾节点
-
更新末尾节点
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
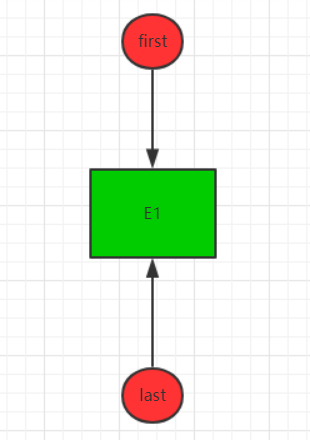
}一开始,first和last都为null,此时链表什么都没有,当第一次调用该方法后,first和last均指向了第一个新加的节点E1:
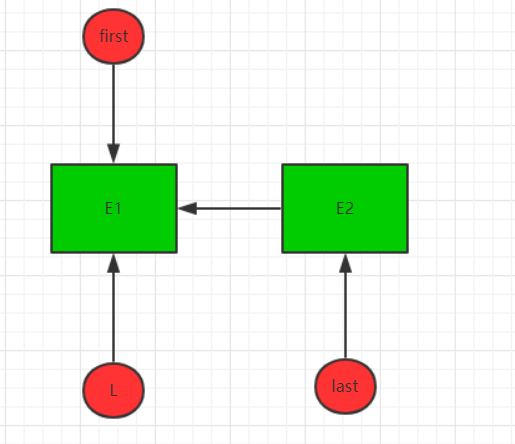
接着,第二次调用该方法,加入新节点E2。首先,将last引用赋值给l,接着new了一个新节点E2,并且E2的prve指向l,接着将新节点E2赋值为last。现在结构如下:
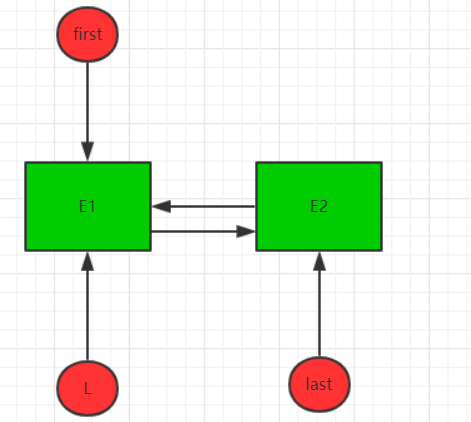
接着判断l==null? 所以走的else语句,将l的next引用指向新节点E2,现在数据结构如下:
接着size+1,modCount+1,退出该方法,局部变量l销毁,所以现在数据结构如下:
3.4.2、add(int index, E element) :在指定位置插入新元素
- index位置检查(不能小于0,大于size)
-
如果index==size,直接在链表最后插入,相当于调用
add(E e)
方法 - 小于size,首先调用node方法将index位置的节点找出,接着调用linkBefore
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
private void checkPositionIndex(int index) {
if (!isPositionIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}这样就完成了链表新节点的构建。
小结:
-
链表批量增加,
是
靠for循环遍历原数组,依次执行插入节点操作
。对比ArrayList是通过System.arraycopy完成批量增加的
-
通过下标获取某个node 的时候,(add select),
会根据index处于前半段还是后半段 进行一个折半
,以
提升查询效率
我们同样作图分析,假设现在链表中有三个节点,调用node方法后找到的第二个节点E2,则进入方法后,结构如下:

接着,将succ的prev赋值给pred,并且构造新节点E4,E4的prev和next分别为pred和suc,同时将新节点E4赋值为succ的prev引用,则现在结构如下:

接着,将新节点赋值给pred节点的next引用,结构如下:

最后,size+1,modCount+1,推出方法,本地变量succ,pred销毁,最后结构如

这样新节点E4就插入在了第二个E2节点前面。新链表构建完成。从这个过程中我们可以知道,这里并没有大量移动移动以前的元素,所以效率非常高!
3.4.3、addAll()
- 待插入的集合为空的话,直接返回
- 记录前置节点:分前插和后插两种方式找前置
- 循环插入
- 分前插和后插两种方式完成后值
public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);
}
public boolean addAll(int index, Collection<? extends E> c) {
checkPositionIndex(index);
Object[] a = c.toArray();
int numNew = a.length;
if (numNew == 0)
return false;
Node<E> pred, succ;
if (index == size) {
succ = null;
pred = last;
} else {
succ = node(index);
pred = succ.prev;
}
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
Node<E> newNode = new Node<>(pred, e, null);
if (pred == null)
first = newNode;
else
pred.next = newNode;
pred = newNode;
}
if (succ == null) {
last = pred;
} else {
pred.next = succ;
succ.prev = pred;
}
size += numNew;
modCount++;
return true;
}
3.4.4、E remove(int index)移除指定节点
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
- 检查index位置
-
调用node方法获取节点,接着调用
unlink(E e)
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
原理就是将当前节点X的前一个节点Pre的next直接指向X的下一个节点Next,这样X就不再关联任何引用,等待垃圾回收即可。这里我们同样知道,相比于
ArrayList
的copy数组覆盖原来节点,效率同样更高!
3.4.5、boolean remove(Object o) 删除链表中的指定节点
//因为要考虑 null元素,也是分情况遍历
public boolean remove(Object o) {
if (o == null) {//如果要删除的是null节点(从remove和add 里 可以看出,允许元素为null)
//遍历每个节点 对比
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
3.4.6、E set( index, E)
public E set(int index, E element) {
checkElementIndex(index);
Node<E> x = node(index);
E oldVal = x.item;
x.item = element;
return oldVal;
}
3.4.7、 int indexOf(Object o) 根据节点对象,查询下标
public int indexOf(Object o) {
int index = 0;
if (o == null) {//如果目标对象是null
//遍历链表
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null)
return index;
index++;
}
} else {遍历链表
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item))
return index;
index++;
}
}
return -1;
}
3.4.8、 int lastIndexOf(Object o) 从尾至头遍历链表,找到目标元素值为o的节点
public int lastIndexOf(Object o) {
int index = size;
if (o == null) {
for (Node<E> x = last; x != null; x = x.prev) {
index--;
if (x.item == null)
return index;
}
} else {
for (Node<E> x = last; x != null; x = x.prev) {
index--;
if (o.equals(x.item))
return index;
}
}
return -1;
}
3.4.9、E get( index)
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
3.4.10、toArray()
public Object[] toArray() {
//new 一个新数组 然后遍历链表,将每个元素存在数组里,返回
Object[] result = new Object[size];
int i = 0;
for (Node<E> x = first; x != null; x = x.next)
result[i++] = x.item;
return result;
4、总结
- LinkedList是基于双向链表实现的,不论是增删改查方法还是队列和栈的实现,都可通过操作结点实现;
- LinkedList无需提前指定容量,因为基于链表操作,集合的容量随着元素的加入自动增加;
- LinkedList删除元素后集合占用的内存自动缩小,无需像ArrayList一样调用trimToSize()方法;
- LinkedList的所有方法没有进行同步,因此它也不是线程安全的,应该避免在多线程环境下使用
- CRUD操作里,都涉及到根据index去找到Node的操作