文章目录
KeyPoint
能否将注意力机制和RNN相结合,从而实现更好的视频序列抠图网络,
注意力机制相比于卷积神经网络和循环神经网络都更加耗时。

Overview
注意力池化
注意力机制通过注意力汇聚将
查询
(自主性提示)和
键
(非自主性提示)结合在一起,实现对
值
(感官输入)的选择倾向。
注意力权重
-
注意力机制与全连接层或者池化层的区别源于
增加的自主提示
。
非参数注意力池化
根据输入的位置对输出
y
i
y_i
y
i
进行加权,权函数为
α
(
x
,
x
i
)
\alpha(x, x_i)
α
(
x
,
x
i
)
,则用公式表示为
f
(
x
)
=
∑
i
=
1
n
α
(
x
,
x
i
)
y
i
f(x) = \sum_{i=1}^{n} \alpha (x, x_i) y_i
f
(
x
)
=
i
=
1
∑
n
α
(
x
,
x
i
)
y
i
其中
x
x
x
表示query,
(
x
i
,
y
i
)
(x_i,y_i)
(
x
i
,
y
i
)
表示键值对,注意力池化是
y
i
y_i
y
i
的加权平均,
α
(
x
,
x
i
)
\alpha (x, x_i)
α
(
x
,
x
i
)
表示注意力权重
对于任何query,模型在所有键值对上的注意力权重都是一个有效的概率分布:1. 非负, 2. 总和为1
一个键
x
i
x_i
x
i
越是接近给定的query
x
x
x
,那么分配给这个键对应值
y
i
y_i
y
i
的注意力权重也就越大。
带参数的注意力池化
可以将可学习的参数集成到注意力池化中
评分函数
由于注意力权重是概率分布,因此加权和其本质上是加权平均值。
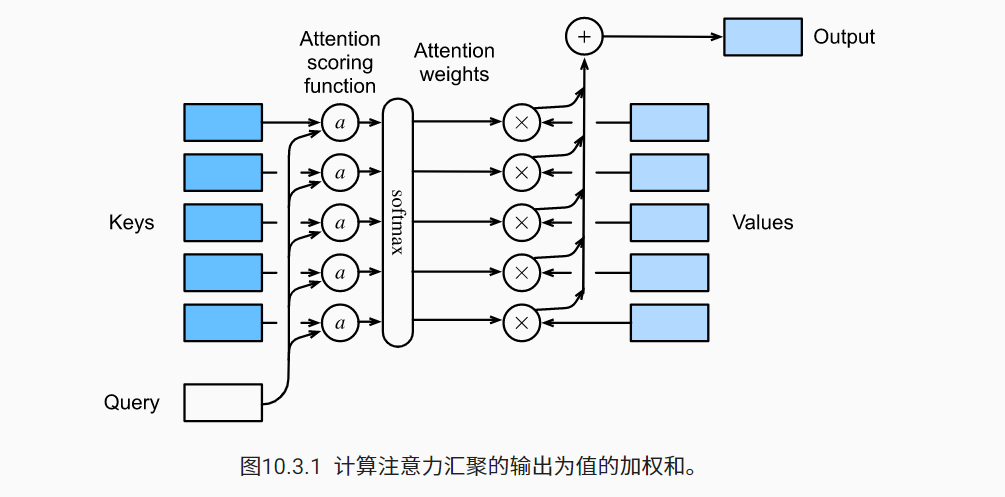
注意力池化函数
f
f
f
可表示为:
f
(
q
,
(
k
1
,
v
1
)
,
.
.
.
,
(
k
m
,
v
m
)
)
=
∑
i
=
1
m
α
(
q
,
k
i
)
v
i
f(q, (k_1, v_1), …, (k_m, v_m))=\sum_{i=1}^{m} \alpha{(q, k_i)v_i}
f
(
q
,
(
k
1
,
v
1
)
,
.
.
.
,
(
k
m
,
v
m
)
)
=
i
=
1
∑
m
α
(
q
,
k
i
)
v
i
其中
α
(
q
,
k
i
)
\alpha (q, k_i)
α
(
q
,
k
i
)
表示注意力权重函数,具体形式为:
α
(
q
,
k
i
)
=
s
o
f
t
m
a
x
(
a
(
q
,
k
i
)
)
=
e
a
(
q
,
k
i
)
∑
j
=
1
m
e
a
(
q
,
k
j
)
\alpha(q, k_i) = softmax(a(q, k_i))= \frac{e^{a(q,k_i)}}{\sum_{j=1}^{m}e^{a(q, k_j)}}
α
(
q
,
k
i
)
=
s
o
f
t
m
a
x
(
a
(
q
,
k
i
)
)
=
∑
j
=
1
m
e
a
(
q
,
k
j
)
e
a
(
q
,
k
i
)
其中
a
(
q
,
k
i
)
a(q, k_i)
a
(
q
,
k
i
)
表示注意力评分函数。
通过使用不同的评分函数,可以得到不同的注意力池化层。
masked softmax operation
通过指定有效的序列尺寸(size),使得在计算softmax时自动过滤掉超出大小的位置,(直接设置为0或其他值)
additive attention
其评分函数
a
(
q
,
k
)
a(q, k)
a
(
q
,
k
)
为
a
(
q
,
k
)
=
w
v
T
t
a
n
h
(
W
q
q
+
W
k
k
)
a(q, k)=w_v^Ttanh(W_q q+W_k k)
a
(
q
,
k
)
=
w
v
T
t
a
n
h
(
W
q
q
+
W
k
k
)
其中
t
a
n
h
(
x
)
=
e
x
−
e
−
x
e
x
+
e
−
x
tanh(x)=\frac{e^x-e^{-x}}{e^x+e^{-x}}
t
a
n
h
(
x
)
=
e
x
+
e
−
x
e
x
−
e
−
x
,
W
q
、
W
k
、
w
v
T
W_q、W_k、w_v^T
W
q
、
W
k
、
w
v
T
为可学习的参数
scaled dot-product attention
其评分函数
a
(
q
,
k
)
a(q, k)
a
(
q
,
k
)
为
a
(
q
,
k
)
=
q
T
k
d
a(q,k) = \frac{q^Tk }{\sqrt{d}}
a
(
q
,
k
)
=
d
q
T
k
这个函数的目的是为了确保无论向量长度如何,对于两个方差为1的向量,其点积的方差在不考虑向量长度的情况下仍然是1。
Bahdanau 注意力
注意力池化函数
f
f
f
可表示为:
f
t
′
=
∑
t
=
1
T
α
(
q
t
′
−
1
,
k
t
)
k
t
f_{t’}=\sum_{t=1}^{T} \alpha(q_{t’-1}, k_t)k_t
f
t
′
=
t
=
1
∑
T
α
(
q
t
′
−
1
,
k
t
)
k
t
多头注意力
在实践中,当给定相同的查询、键和值的集合时,我
们希望模型可以基于相同的注意力机制学习到不同的行为,然后将不同的行为作为知识组合起来,例如捕获序列内各种范围的依赖关系(例如,短距离依赖和长距离依赖)
。因此,允许注意力机制组合使用查询、键和值的不同
子空间表示
(representation subspaces)可能是有益的。多头注意力融合了来自于相同的注意力汇聚产生的不同的知识,这些知识的不同来源于相同的查询、键和值的不同的子空间表示
为此,与使用单独一个注意力汇聚不同,
-
我们可以用独立学习得到的 hh组不同的
线性投影
(linear projections)来变换查询、键和值。 - 然后,这 h 组变换后的查询、键和值将并行地送到注意力汇聚中。
-
最后,将这 hh个注意力汇聚的输出拼接在一起,并且通过另一个可以学习的线性投影进行变换,以产生最终输出。这种设计被称为
多头注意力
,其中 hh 个注意力汇聚输出中的每一个输出都被称作一个
头
(head)。
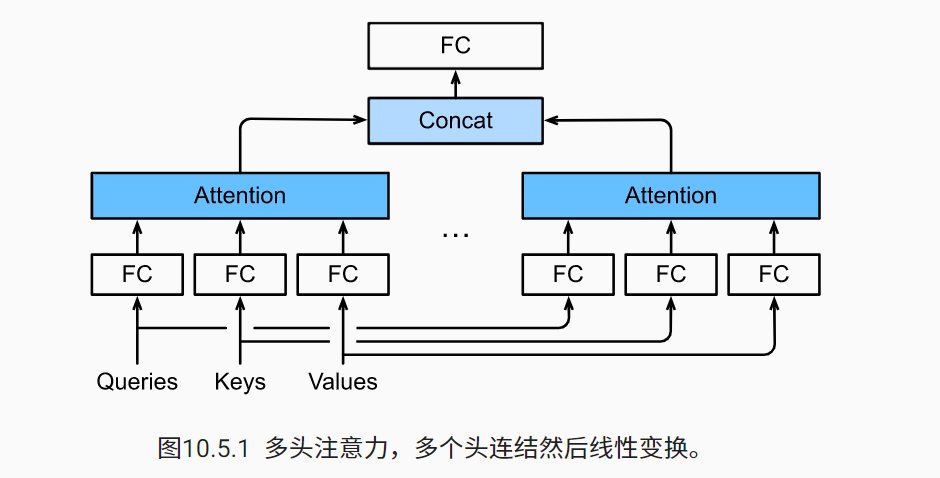
h
i
=
f
(
W
i
(
q
)
q
,
W
i
(
k
)
k
,
W
i
(
v
)
v
)
h_i=f(W_i^{(q)}q,W_i^{(k)}k,W_i^{(v)}v)
h
i
=
f
(
W
i
(
q
)
q
,
W
i
(
k
)
k
,
W
i
(
v
)
v
)
f可以是加性注意力和缩放点积注意力,多头注意力的输出需要经过另一个线性变换,它对应着h个头连结的结果。
o
u
t
p
u
t
=
W
0
[
h
1
,
h
2
,
.
.
.
,
h
h
]
=
W
0
H
output=W_0[h_1, h_2, …, h_h]=W_0H
o
u
t
p
u
t
=
W
0
[
h
1
,
h
2
,
.
.
.
,
h
h
]
=
W
0
H
在实现过程中,为避免计算成本和参数数量的大幅增长,
p
q
=
p
k
=
p
v
=
p
o
/
h
p_q=p_k=p_v=p_o/h
p
q
=
p
k
=
p
v
=
p
o
/
h
。
自注意力
- 在自注意力中,查询、键和值都来自同一组输入。
- 卷积神经网络和自注意力都拥有并行计算的优势,而且自注意力的最大路径长度最短。但是因为其计算复杂度是关于序列长度的二次方,所以在很长的序列中计算会非常慢。
-
为了使用序列的顺序信息,我们可以通过在输入表示中添加位置编码来注入绝对的或相对的位置信息。
自注意力同时具有并行计算和最短的最大路径长度这两个优势
yi
=
f
(
x
i
,
(
x
1
,
x
1
)
,
.
.
.
,
(
x
n
,
x
n
)
)
y_i=f(x_i, (x_1,x_1),…,(x_n, x_n))
y
i
=
f
(
x
i
,
(
x
1
,
x
1
)
,
.
.
.
,
(
x
n
,
x
n
)
)
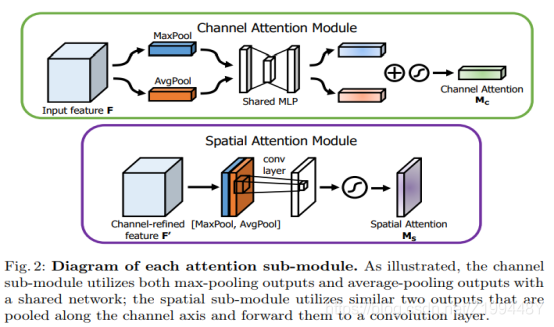
spatial-wise and channel-wise attention 空间和通道注意力
Attention mechanism可以加权作用在空间尺度(Spatial attention)上,给不同空间区域加权,也可以作用在channel尺度(channel attention)上,给不同通道特征加权,甚至可以给特征图上每个元素加权。类似于逐点卷积和深度卷积。
spatial-wise attention:对所有的特征图的同一个位置进行操作,得到空间中单通道各像素分数,通过softmax函数后得到单个通道内各像素的概率分布
channel-wise attention:对所有的特征图的不同通道进行操作,得到各通道特征分数,通过softmax函数后得到特征图中各通道的概率分布
《CBAM:channel and spatial block modulation》(ECCV 2018)
Channel-wise attention的处理:average pooling——为了聚合spatial information;max-pooling——可以得到区别object features的另一个重要线索(max-pooling更像做了特征选择,选出分类区别度更好的特征,提供了非线性)
Spatial attention的处理:用max-pooling和average-pooling沿着channel操作,然后cancatenate产生特征描述子(这样做的目的突出信息区域);再通过一个卷积层产生spatial attention map。
Transformer
该模型完全基于注意力机制,没有任何卷积层或循环神经网络层
Keywords
query
attention pooling
Values
attention function
参考
部分图参考
动手学深度学习