这里写自定义目录标题
Opencv中简单的图像分割
图像分割:将图像分成若干有相似区域性质的区域。
主要方法:基于阈值、基于区域、基于边缘、基于聚类、基于图论、基于深度学习。
参考链接: opencv图像分割方法.
本文头文件及命名空间:
#pragma once
#include <opencv2\opencv.hpp>
#include <iostream>
using namespace std;
using namespace cv;
阈值分割
基于阈值分割,使用opencv中二值化函数,threshold(),选择不同的类型和阈值对图像进行分割。本质是二值化,只能区分与分割一些像素值间隔打、色彩单一的简单图像。
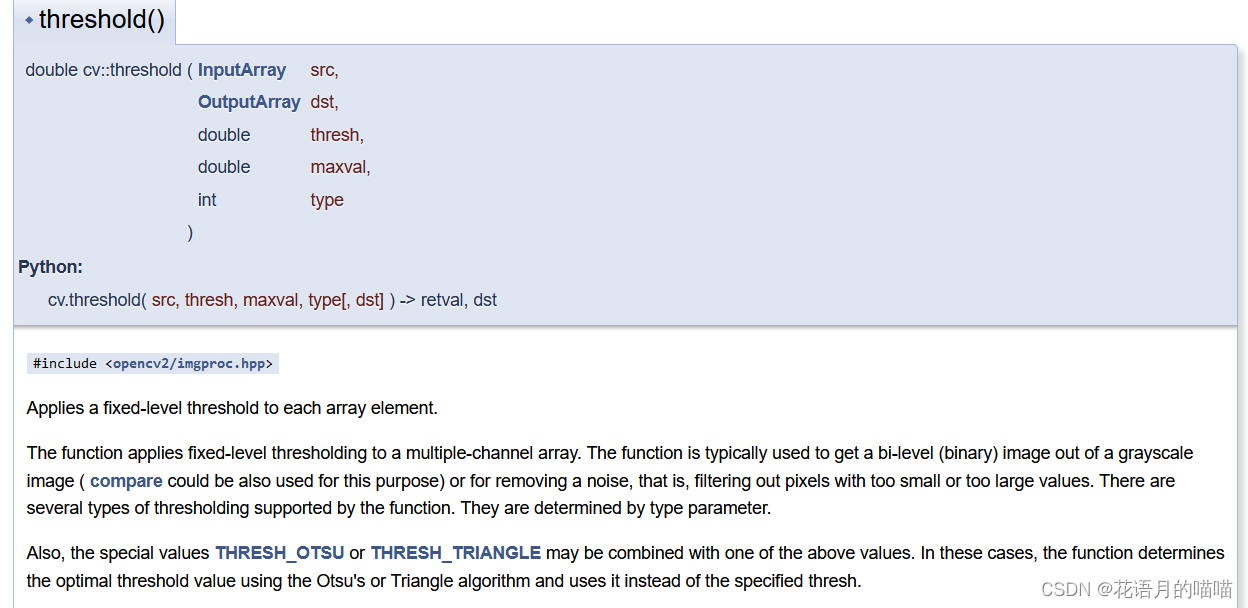
src : 输入图像
dst : 输出图像
thresh : 阈值
maxval : 最大值
type : 二值化类型
不同类型的具体取值由下列函数得出:

测试代码:
//阈值分割
Mat m1 = imread(path4, 1);
Mat m2, m3, m4;
//图像灰度化,也可以不灰度化,这里为了让结果更容易理解
cvtColor(m1, m1, COLOR_BGR2GRAY);
//类型1
threshold(m1, m2, 127, 255, THRESH_BINARY);
//类型2
threshold(m1, m3, 127, 255, THRESH_BINARY_INV);
//类型3
threshold(m1, m4, 127, 255, THRESH_TRUNC);
imshow("truth image" , m1);
imshow("1 image", m2);
imshow("2 image", m3);
imshow("3 image", m4);
waitKey(0);
测试结果(图像来源网络,侵权告知立即删除)

二值化函数阈值分割的结果由所选取的阈值和类型决定,只能分割简单图像。
分水岭分割
分水岭分割使用分水岭方法,实现图像不同区域的分割。在分割的过程中,它会把跟临近像素间的相似性作为重要的参考依据,从而将在空间位置上相近并且灰度值相近(求梯度)的像素点互相连接起来构成一个封闭的轮廓。
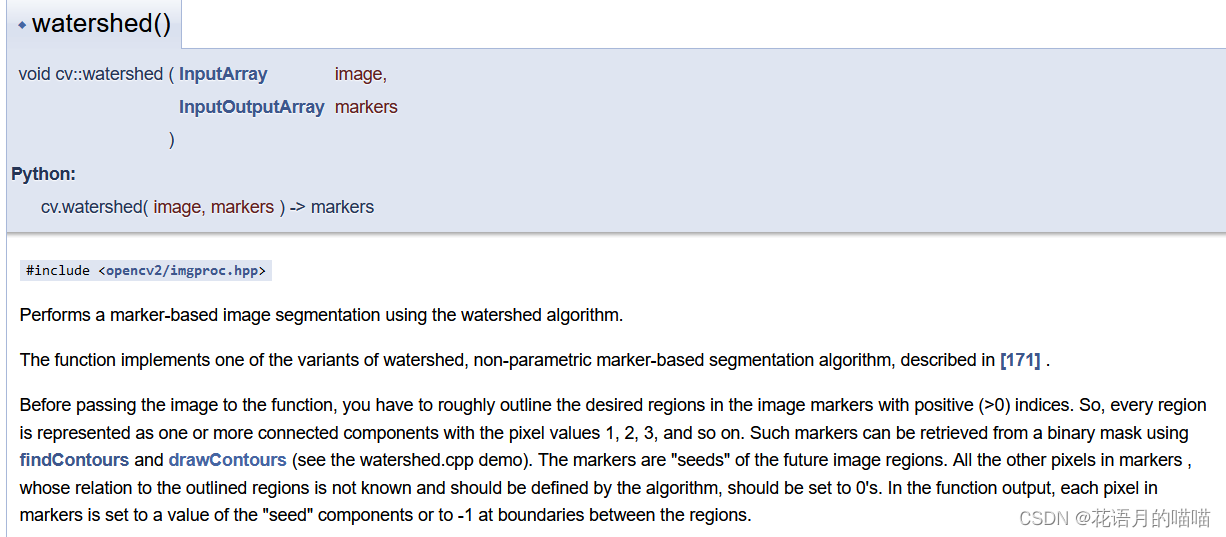
image :输入图像,代码中为锐化后的原图像,类型需为CV_8UC3
markers :轮廓图,类型需为CV_32SC1
使用watershed之前需要依步骤找出图像的轮廓,在以这些轮廓为种子使用分水岭算法进行分割。
需要了解的图像处理知识有:图像滤波与卷积、图像二值化、图像色域转换、图像距离变换、图像形态学(腐蚀)、寻找绘制轮廓、图像像素操作。
分水岭具体步骤(总结而来):
1.使用拉普拉斯算子滤波,使图像锐化,增强图像对比度
2.二值化
3.距离变换
4.归一化,不归一化距离变换的结果与未变换前相同
5.二次二值化,凸显标记
6.腐蚀,去除分散的错误标记
7.寻找轮廓
8.绘制轮廓
9.分水岭算法
10.对每个轮廓重新赋色,并显示。
不同的函数的输入类型可能不同,需要进行适当转换。
测试代码:
//分水岭算法分割
Mat m1 = imread(path10, 1);
//laplace算子增强对比
Mat imgLp;
Laplacian(m1, imgLp, -1, 3);
Mat sharpImg = m1 - imgLp;
imshow("truth image", m1);
imshow("sharp image", sharpImg);
//图像二值化
Mat binaryImg;
cvtColor(sharpImg, binaryImg, COLOR_BGR2GRAY);
threshold(binaryImg, binaryImg, 130,255 , THRESH_BINARY);
imshow("binary image", binaryImg);
//距离变换
Mat distanceImg;
distanceTransform(binaryImg, distanceImg, DIST_L1, 3,5);
//归一化,不归一化距离变换结果与变换前相同
imshow("distance image", distanceImg);
normalize(distanceImg, distanceImg, 0, 1, NORM_MINMAX);
imshow("distance image after normalize", distanceImg);
//再次二值化,寻找标记
threshold(distanceImg, distanceImg, 0.3, 1 , THRESH_BINARY);
//腐蚀标记
Mat kernel = getStructuringElement(MORPH_RECT, Size(13, 13), Point(-1, -1));
Mat erodeImg;
morphologyEx(distanceImg, erodeImg, MORPH_ERODE, kernel);
imshow("erode image", erodeImg);
//发现轮廓
Mat erodeU8;
erodeImg.convertTo(erodeU8, CV_8U);
//contours被定义成二维浮知点型向量,用于存储找到的边界的(x,y)坐标
vector<vector<Point>> contours;
vector<Vec4i> hierarchy;
findContours(erodeU8, contours, hierarchy,RETR_EXTERNAL, CHAIN_APPROX_SIMPLE, Point(0, 0));
//绘制轮廓
Mat makers = Mat::zeros(m1.size(), CV_8UC1);
cout << contours.size();
for (size_t i = 0; i < contours.size(); i++) {
drawContours(makers, contours, i, Scalar::all(static_cast<int>(i) + 1), FILLED);
}
imshow("contours ", makers);
//分水岭算法
makers.convertTo(makers, CV_32SC1);
watershed(m1 - imgLp, makers);
Mat mark = Mat::zeros(makers.size(), CV_8UC1);
makers.convertTo(mark, CV_8UC1);
bitwise_not(mark, mark, Mat());
imshow("watershed image", mark);
// generate random color,每个轮廓赋予随机颜色
vector<Vec3b> colors;
for (size_t i = 0; i < contours.size(); i++) {
int r = theRNG().uniform(0, 255);
int g = theRNG().uniform(0, 255);
int b = theRNG().uniform(0, 255);
colors.push_back(Vec3b((uchar)b, (uchar)g, (uchar)r));
}
// fill with color and display final result
Mat dst = Mat::zeros(makers.size(), CV_8UC3);
for (int row = 0; row < makers.rows; row++) {
for (int col = 0; col < makers.cols; col++) {
int index = makers.at<int>(row, col);
//cout << index;
if (index > 0 && index <= static_cast<int>(contours.size())) {
dst.at<Vec3b>(row, col) = colors[index - 1];
}
else {
dst.at<Vec3b>(row, col) = Vec3b(0, 0, 0);
}
}
}
imshow("Final Result", dst);
waitKey(0);
测试结果(未找到合适的图片,使用他人博客中的图像,其他图像效果很差):

参考文章:opecnv 分水岭算法.
Canny算子边缘分割
待添加
基于深度学习
上述方法在测试中均只能检测较为简单的单一的图像,处理一类相似的简单问题有着速度快、不复杂的优点。适用于单一固定场景的检测。但对于复杂、多变、高鲁棒性需求的图像分割,效果不佳,深度学习的方法在这些问题上有着其独特的优点。
深度学习是机器学习的分支,传统机器学习有SVM、聚类等多用于处理线性问题;深度学习依赖卷积层中的激活函数多用于处理非线性问题。在图像处理(检测、分割)CV、音频识别、NLP有着其他方法难以超越的优势。我自己研究的方向也是使用不同的深度学习算法进行卫星图像相关检测和处理。
就图像分割而言,深度学习方法仍主要使用 全卷积网络,优点是在经过同样次数的上采样、下采样后,输出图像的大小与输入相同。图像分割不同于图像检测,图像检测最后无论多少维度的结果只需使用一个FC层在Softmax即可得到所需的输出概率,根据所需判别类别调整FC的神经元数目。而图像分割,我们期望结果是在原图上的区域分割、标定,因此输出最好同输入大小相同。从最初的FCN到DeeplabV3、Unet、Mutires-Unet均使用全卷积结构,并加入不同的模块(残差、金字塔池化、注意力等) 来提升网络的性能。
具体算法,可在GitHub搜索。
总结
图像分割是检测的下一步目标,依据所处理的问题的不同,应当使用不同的方法。对于背景色单一、图像中目标少易区分的图像,使用传统的分割方法即可有较好的效果。而当处理到图像色域接近、目标复杂尤其是实现语义分割与实例分割时,需要使用深度学习的方法。
深度学习的方法在我看来提供了一种较好的方法,实现在一群猫中找到你喜欢的那只猫,喵。
文章内容有误或可改正地方,可私信,会即使修改。