ASCII是英文American Standard Code for Information Interchange的缩写。ASCII码是目前计算机最通用的编码标准。
因为信息在计算机上是用二进制表示的,这种表示法让人理解就很困难。因此计算机上都配有输入和输出设备,这些设备的主要目的就是,以一种人类可阅读的形式将信息在这些设备上显示出来供人阅读理解。为保证人类和设备,设备和计算机之间能进行正确的信息交换,人们编制的统一的信息交换代码,这就是ASCII码表,它的全称是“美国信息交换标准代码”。
ASCII码中,第0~32号及第127号是控制字符,常用的有LF(换行)、CR(回车);第33~126号是字符,其中第48~57号为0~9十个阿拉伯数字;65~90号为26个大写英文字母,97~122号为26个小写英文字母,其余的是一些标点符号、运算符号等。
ASCII 非打印控制字符
ASCII 表上的数字 0–31 分配给了控制字符,用于控制像打印机等一些外围设备。例如,12 代表换页/新页功能。此命令指示打印机跳到下一页的开头。
ASCII 非打印控制字符表
| 进制 | 字符 | 进制 | 字符 | |||
|---|---|---|---|---|---|---|
| 0 | 00 | 空 | 16 | 10 | 数据链路转意 | |
| 1 | 01 | 头标开始 | 17 | 11 | 设备控制 1 | |
| 2 | 02 | 正文开始 | 18 | 12 | 设备控制 2 | |
| 3 | 03 | 正文结束 | 19 | 13 | 设备控制 3 | |
| 4 | 04 | 传输结束 | 20 | 14 | 设备控制 4 | |
| 5 | 05 | 查询 | 21 | 15 | 反确认 | |
| 6 | 06 | 确认 | 22 | 16 | 同步空闲 | |
| 7 | 07 | 震铃 | 23 | 17 | 传输块结束 | |
| 8 | 08 | backspace | 24 | 18 | 取消 | |
| 9 | 09 | 水平制表符 | 25 | 19 | 媒体结束 | |
| 10 | 0A | 换行/新行 | 26 | 1A | 替换 | |
| 11 | 0B | 竖直制表符 | 27 | 1B | 转意 | |
| 12 | 0C | 换页/新页 | 28 | 1C | 文件分隔符 | |
| 13 | 0D | 回车 | 29 | 1D | 组分隔符 | |
| 14 | 0E | 移出 | 30 | 1E | 记录分隔符 | |
| 15 | 0F | 移入 | 31 | 1F | 单元分隔符 |
ASCII 打印字符
数字 32–126 分配给了能在键盘上找到的字符,当您查看或打印文档时就会出现。数字 127 代表 DELETE 命令。
ASCII 打印字符表
| 进制 | 字符 | 进制 | 字符 | 进制 | 字符 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| 32 | 20 | space | 64 | 40 | @ | 96 | 60 | ` | ||
| 33 | 21 | ! | 65 | A | 97 | a | ||||
| 34 | 22 | “ | 66 | B | 98 | b | ||||
| 35 | 23 | # | 67 | C | 99 | c | ||||
| 36 | 24 | $ | 68 | D | 100 | d | ||||
| 37 | 25 | % | 69 | E | 101 | e | ||||
| 38 | 26 | & | 70 | F | 102 | f | ||||
| 39 | 27 | ‘ | 71 | G | 103 | g | ||||
| 40 | 28 | ( | 72 | H | 104 | h | ||||
| 41 | 29 | ) | 73 | I | 105 | i | ||||
| 42 | 2A | * | 74 | J | 106 | j | ||||
| 43 | 2B | + | 75 | K | 107 | k | ||||
| 44 | 2C | , | 76 | L | 108 | l | ||||
| 45 | 2D | – | 77 | M | 109 | m | ||||
| 46 | 2E | . | 78 | 4F | N | 110 | n | |||
| 47 | 2F | / | 79 | 5F | O | 111 | 6F | o | ||
| 48 | 30 | 0 | 80 | 50 | P | 112 | 70 | p | ||
| 49 | 1 | 81 | 51 | Q | 113 | q | ||||
| 50 | 2 | 82 | 52 | R | 114 | r | ||||
| 51 | 3 | 83 | 53 | S | 115 | s | ||||
| 52 | 4 | 84 | 54 | T | 116 | t | ||||
| 53 | 5 | 85 | 55 | U | 117 | u | ||||
| 54 | 6 | 86 | 56 | V | 118 | v | ||||
| 55 | 7 | 87 | 57 | w | 119 | w | ||||
| 56 | 8 | 88 | 58 | X | 120 | x | ||||
| 57 | 9 | 89 | 59 | Y | 121 | y | ||||
| 58 | : | 90 | 5A | Z | 122 | z | ||||
| 59 | ; | 91 | 5B | [ | 123 | { | ||||
| 60 | < | 92 | 5C | \ | 124 | | | ||||
| 61 | = | 93 | 5D | ] | 125 | } | ||||
| 62 | > | 94 | 5E | ^ | 126 | ~ | ||||
| 63 | 3F | ? | 95 | 5F | _ | 127 | 70 | DEL |
扩展ASCII字符表:


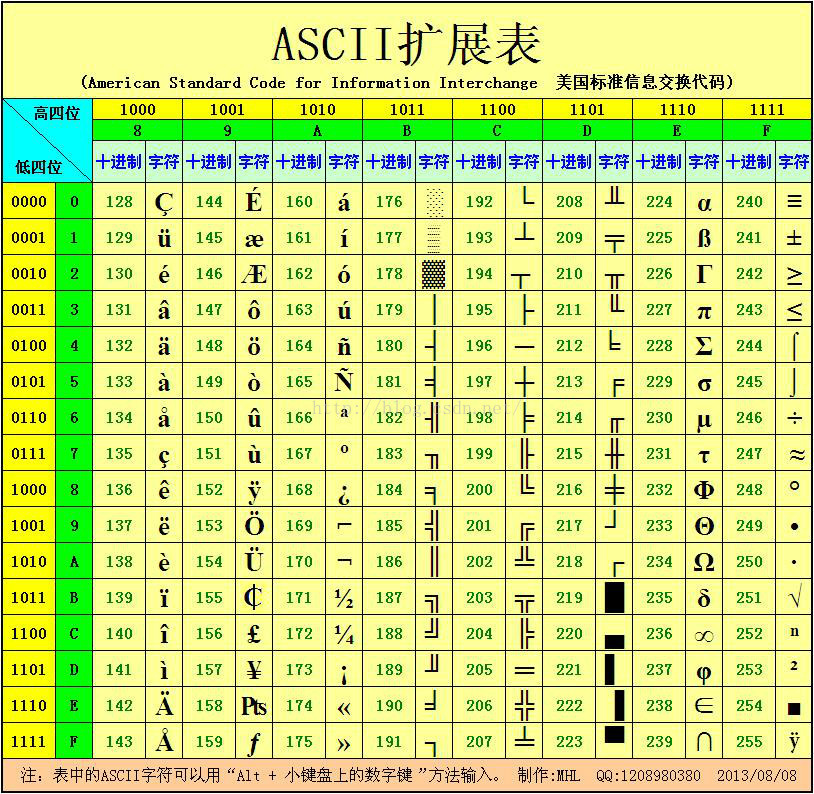
计算机发明后,为了在计算机中表示字符,人们制定了一种编码,叫ASCII码。ASCII码由一个字节中的7位(bit)表示,范围是0x00 – 0x7F 共128个字符。他们以为这128个数字就足够表示abcd….ABCD….1234 这些字符了。
咳……说英语的人就是“笨”!后来他们突然发现,如果需要按照表格方式打印这些字符的时候,缺少了“制表符”。于是又扩展了ASCII的定义,使用一个字节的全部8位(bit)来表示字符了,这就叫扩展ASCII码。范围是0x00 – 0xFF 共256个字符。
咳……说中文的人就是聪明!中国人利用连续2个扩展ASCII码的扩展区域(0xA0以后)来表示一个汉字,该方法的标准叫GB-2312。后来,日文、韩文、阿拉伯文、台湾繁体(BIG-5)……都使用类似的方法扩展了本地字符集的定义,现在统一称为 MBCS 字符集(多字节字符集)。这个方法是有缺陷的,因为各个国家地区定义的字符集有交集,因此使用GB-2312的软件,就不能在BIG-5的环境下运行(显示乱码),反之亦然。
咳……说英语的人终于变“聪明”一些了。为了把全世界人民所有的所有的文字符号都统一进行编码,于是制定了UNICODE标准字符集。UNICODE 使用2个字节表示一个字符(unsigned shor int、WCHAR、_wchar_t、OLECHAR)。这下终于好啦,全世界任何一个地区的软件,可以不用修改地就能在另一个地区运行了。虽然我用 IE 浏览日本网站,显示出我不认识的日文文字,但至少不会是乱码了。UNICODE 的范围是 0x0000 – 0xFFFF 共6万多个字符,其中光汉字就占用了4万多个。嘿嘿,中国人赚大发了:0)
在程序中使用各种字符集的方法:
const char * p = "Hello"; // 使用 ASCII 字符集 const char * p = "你好"; // 使用 MBCS 字符集,由于 MBCS 完全兼容 ASCII,多数情况下,我们并不严格区分他们 LPCSTR p = "Hello,你好"; // 意义同上 const WCHAR * p = L"Hello,你好"; // 使用 UNICODE 字符集 LPCOLESTR p = L"Hello,你好"; // 意义同上 // 如果预定义了_UNICODE,则表示使用UNICODE字符集;如果定义了_MBCS,则表示使用 MBCS const TCHAR * p = _T("Hello,你好"); LPCTSTR p = _T("Hello,你好"); // 意义同上
在上面的例子中,T是非常有意思的一个符号(TCHAR、LPCTSTR、LPTSTR、_T()、_TEXT()…),它表示使用一种中间类型,既不明确表示使用 MBCS,也不明确表示使用 UNICODE。那到底使用哪种字符集那?嘿嘿……编译的时候决定吧。设置条件编译的方式是:VC6中,”Project\Settings…\C/C++卡片 Preprocessor definitions” 中添加或修改 _MBCS、_UNICODE;VC.NET中,”项目\属性\配置属性\常规\字符集”然后用组合窗进行选择。使用 T 类型,是非常好的习惯,严重推荐!