Pytorch 入门笔记
1. Pytorch下载与安装
在Pytorch官网进行官方提供的下载方法:
Pytorch官网
,打开官网后选择对应的操作系统和cuda版本。如果需要安装GPU版本的Pytorch则需要下载对应CUDA版本的Torch版本,例如我装的是CUDA 10.1,Python版本是3.7。

查看已安装CUDA、cuDNN版本的方法:
Windows:
访问文件夹
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA
看该目录下文件夹名称,如果是v10.0则代表10.0版本的CUDA;
访问
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.0\include\cudnn.h
来查看cuDNN的版本。
Linux:
使用命令
cat /usr/local/cuda/version.txt
查看cuda版本;
使用命令
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
查看cuDNN版本。
如果没有安装cuda和cuDNN,则需要先安装这两样东西,再装Pytorch
。先安装cuda,进入
cuda官网
,根据自己的操作系统选择对应版本(version 一栏代表的是你Windows的操作系统版本):
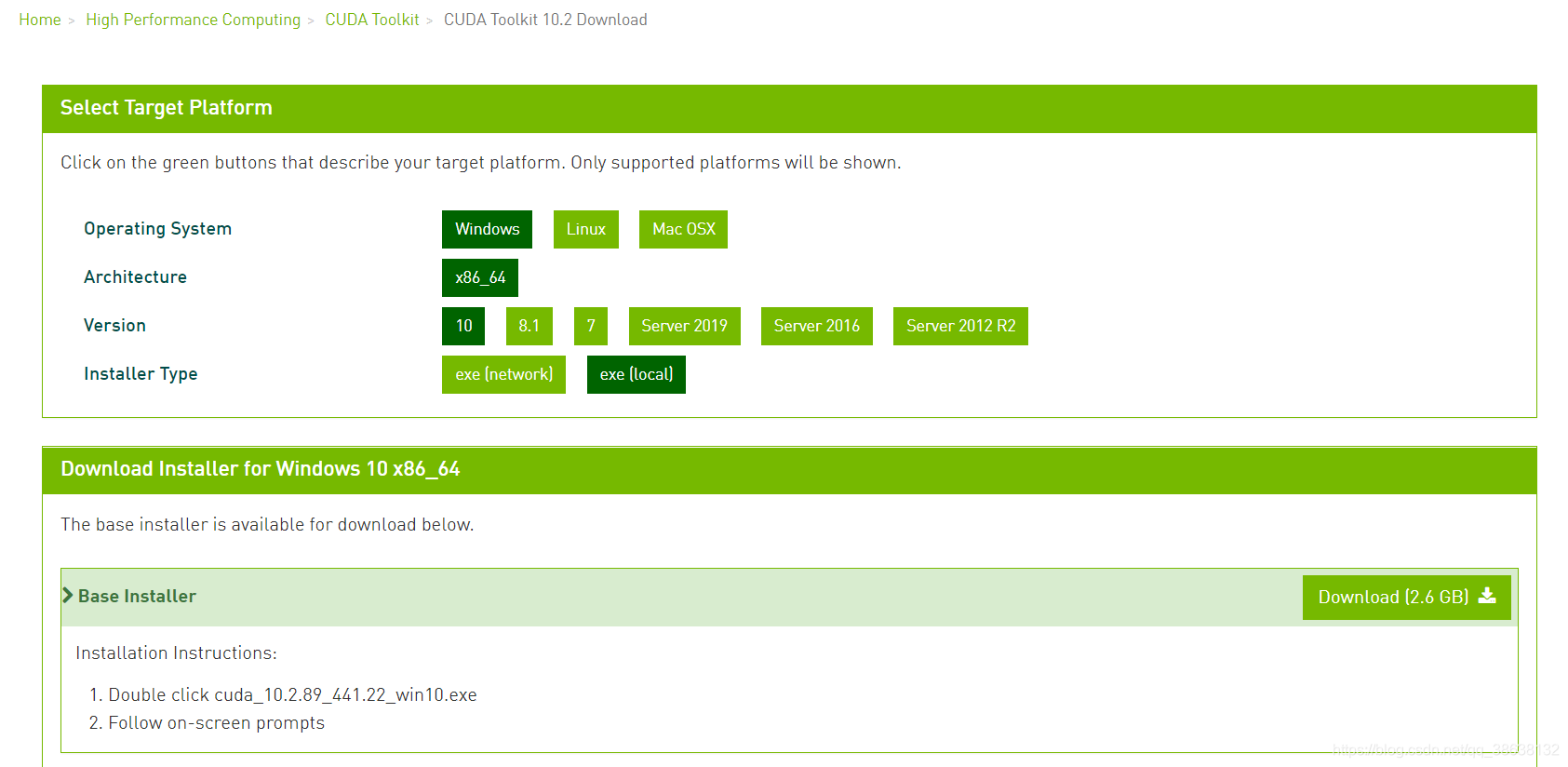
下载exe(local)安装程序,之后一路选择默认安装路径就好了。安装完成后再cmd窗口内输入:
nvcc -V
,若看到以下信息证明cuda安装成功:
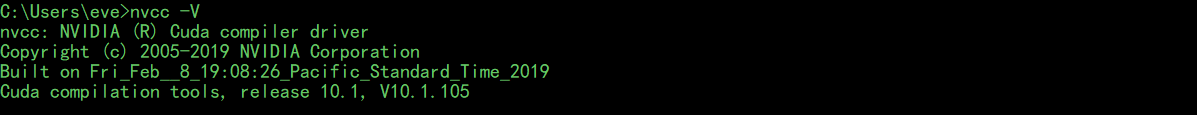
cuda安装好了之后下载对应的cnDNN,进入
cuDNN安装链接
,这里需要先注册一个Nvidia的账号并登录才能进行下一步,登录后看到以下网址:
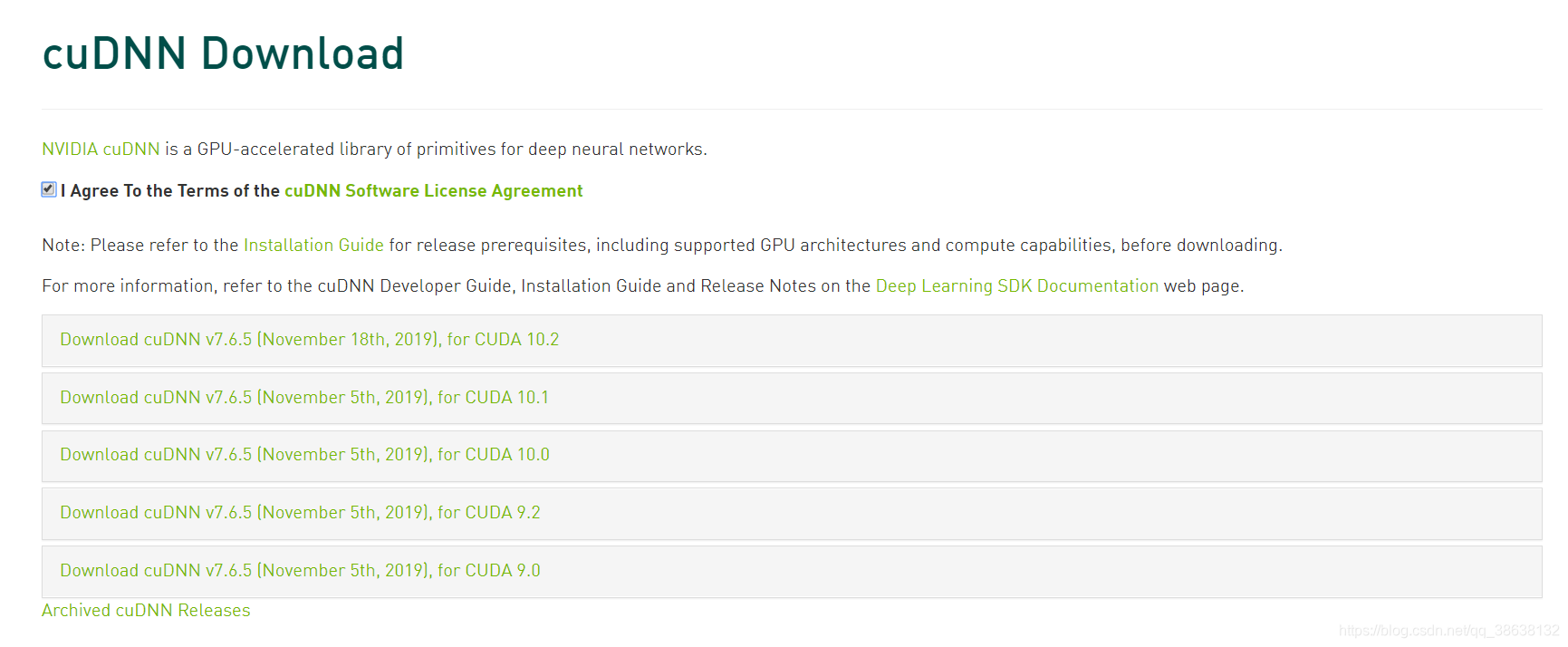
根据安装的cuda版本选择对应的cuDNN的版本即可,比如我们演示的是cuda 10.2版本,这里就选择对应的7.6.5版本的cuDNN就好。下载好后是个压缩文件,解压后得到3个文件夹:bin,include,x64,将这三个文件下的内容分别拷贝到安装的cuda目录对应的bin,include,x64文件夹下即可,cuda的默认安装路径如下:

完成了cuda和cuDNN的安装后,我们就可以回到Pytorch的安装中去了,看文章最开始的那张图,找到对应的版本后,复制图片最下方的pip命令在cmd窗口执行即可开始进行安装:
pip install torch===1.3.1 torchvision===0.4.2 -f https://download.pytorch.org/whl/torch_stable.html -i https://pypi.tuna.tsinghua.edu.cn/simple
这里使用了清华源来加速下载,等待一段时间后,Pytorch就安装完毕了。
2. Pytorch的使用教程
2.1 Pytorch设计理念及其基本操作
Pytorch在设计的时候最大的亮点是在于,其可以替代Numpy库,numpy库中的array运算是依赖于将数组编译成机器码再到CPU运行进行加速的。而Torch是将array(在Pytorch里面叫Tensor)变成GPU上的变量进行运算的,因此在进行大规模运算是Torch能更快速。
- Tensor的运算
Tensor的定义和运算都和np.array()差不多,很多操作都是一样的,下面是一些基本操作的介绍:
import torch
""" 创建 Tensor 的方法 """
x = torch.tensor([3, 3]) # 创建一个值为[3, 3]的Tensor
x = torch.empty(5, 3) # 5x3空矩阵
x = torch.ones(3, 3) # 值全为1的3x3矩阵
y = torch.randn_like(x, dtype=torch.long) # 创建一个和x一样shape的随机矩阵,并将每一个数字dtype变成long
""" Tensor 的属性 """
print(x.size()) # 相当于np.array中的.shape属性,x.size()本质是一个tuple,可以使用tuple的全部属性
""" Resize Tensor """
x = torch.tensor([[1, 2], [3, 4]])
y = x.view(-1, 4) # y = ([1, 2, 3, 4]), 和np.reshape()是一样的
""" Tensor 和 Numpy 的互相转换 """
x_np = np.arrary([1, 1])
x_tensor = torch.from_numpy(x_np) # 从numpy转换到tensor
x_np_2 = x_tensor.numpy() # 从tensor转换到numpy
""" CPU 到 GPU 的转换 """
if torch.cuda.is_available():
device = torch.device("cuda")
x = torch.ones(5, 3)
x_dev = x.to(device) # CPU tensor 转 GPU tensor
x_host= x_dev.to("cpu", torch.doule) # GPU tensor 转 CPU tensor
- 自动求导机制
torch.Tensor这个对象拥有自动求导的功能,每个Tensor在被计算的时候都会自动记录这些运算过程,在最后计算梯度的时候就能够追踪的这些计算过程快速的进行梯度计算。如果要打开计算追踪这个功能需要将
Tensor.requires_grad
这个属性设置为
True
(默认是False的),当该追踪计算功能打开后,只需要调用
.backward()
就能够进行自动的梯度求导了。
在我们训练的时候通常会为Tenosor打开
.requires_grad
属性,但在训练好一个模型后,我们在使用这个模型的时候,这时候我们就不需要计算梯度了(因为不会再做反向传播了),这时候我们就可以关闭
.requires_grad
这个属性来减少运算时间。使用
with torch.no_grad():
来关闭Tensor的计算追踪功能:
with torch.no_grad(): # 整个过程中x, y, z三个tensor均不会开启计算追踪
torch.add(x, y, out=z) # 将tensor x和tensor y相加后放入到tensor z中
2.2 使用torch.nn搭建神经网络
在Pytorch中,搭建一个神经网络需要自己写一个类,该类需要继承自
torch.nn.Module
类,nn.Module主要包含以下两个特点:
-
nn.Module类中已经预先定义好了多种类型的
Layer
(例如:Conv2D,Linear等),使用时直接调用即可。 -
nn.Module中包含一个
forward(input)
方法,该方法接收一个input输入,并return一个output值,通常这个forward()方法都需要用户自己来实现,构建从输入到输出的网络结构。
通常训练一个网络模型的流程如下:
- 首先定义所有的网络架构,模型一共有几层,每一层的类型是什么(Convolution?Linear?),可学习的参数有哪些(weight + bias)。
- 遍历所有的数据集,输入一个 input,通过 forward() 过程计算得到一个 output。
- 比较 output 和 label 的值,计算出 loss。
- 根据梯度和 Loss 计算网络模型中所有可学习参数的梯度信息。
-
进行参数更新, 更新公式通常为:
weight = weight - learning_rate * gradient
我们使用 torch.nn 来搭建一个卷积神经网络用于识别 32*32 的单通道灰度图。首先,我们先来理一下整个网络的结构:
1. Convolutional2D Shape Change
Iw
I_w
I
w
代表输入图层的width,
Ow
O_w
O
w
代表经过Conv2D层后图层的width,
Fw
F_w
F
w
代表卷积核Filter的width,
Sw
S_w
S
w
代表在width上横跨的步长,
Pw
P_w
P
w
代表在width方向上的padding值,则有以下公式(Height方向上同理):
Ow
=
I
w
−
F
w
+
2
P
w
S
w
+
1
O_w=\frac{I_w – F_w + 2P_w}{S_w}+1
O
w
=
S
w
I
w
−
F
w
+
2
P
w
+
1
2. Maxpooling Shape Change
Iw
I_w
I
w
代表输入图层的width,
Ow
O_w
O
w
代表经过Maxpooling2D层后图层的width,
Mw
M_w
M
w
代表池化层的width,
Sw
S_w
S
w
代表在width上横跨的步长(通常是等于池化层的宽度的),则有以下公式(Height方向上同理):
Ow
=
I
w
−
M
w
S
w
+
1
O_w=\frac{I_w – M_w}{S_w}+1
O
w
=
S
w
I
w
−
M
w
+
1
因此,整个网络架构如下:
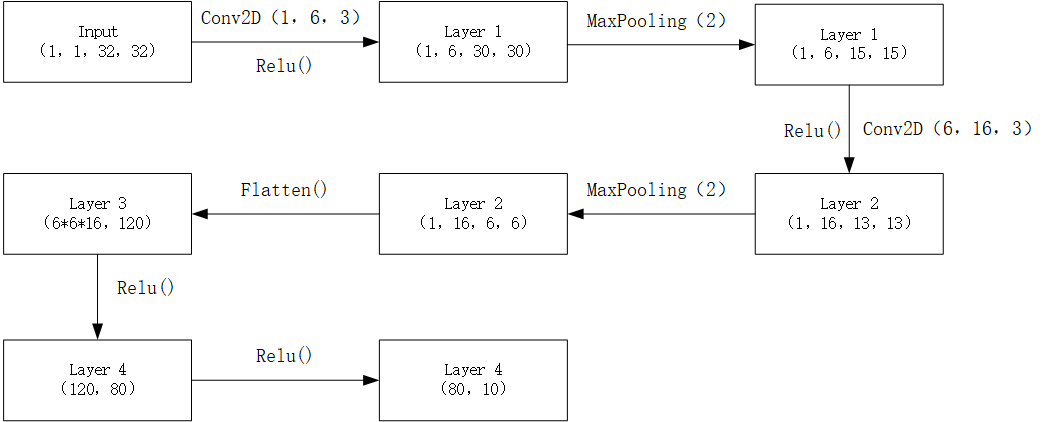
根据上述网络设计编写代码,搭建一个神经网络需要编写:
- 自己写一个类 net(名字自取)继承自torch.nn.Module()
- 利用 torch.nn 中的 Layers 构建自己的Layer
- 实现 net 类中的 forward() 方法
以下是代码实现:
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.Conv1 = nn.Conv2d(1, 6, 3) # params (input_channal_num, out_channal_num, filter_size)
self.Conv2 = nn.Conv2d(6, 16, 3)
self.fc1 = nn.Linear(6*6*16, 120)
self.fc2 = nn.Linear(120, 80)
self.fc3 = nn.Linear(80, 10) # predict 10 classes
def forward(self, x):
x = F.max_pool2d(F.relu(self.Conv1(x)), 2)
x = F.max_pool2d(F.relu(self.Conv2(x)), 2)
x = x.view(-1, self.get_flatten_num(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = F.relu(self.fc3(x))
return x
def get_flatten_num(x):
features_num = x[1:] # drop out the batch size (which is x[0])
flatten_num = 1
for feature_num in features_num:
flatten_num *= feature_num
return flatten_num
net = Net()
print(net)
这样我们就定义好了一个神经网络,打印一下这个神经网络可以看到:
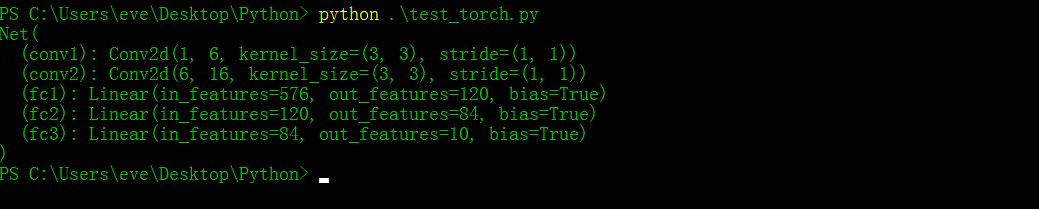
这样一来,整个前向传播就写完了,现在我们来写
反向传播
的过程,首先我们需要计算 Loss 再反向梯度传播,下图是一个简单的反向传播示意图:
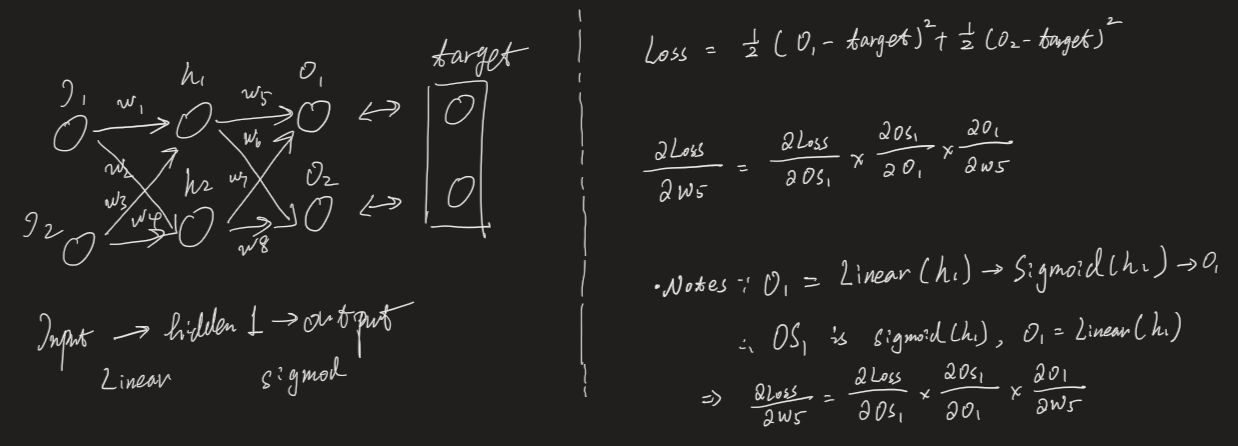
Input 层有两个神经元,hidden layer 也有两个神经元,最终 output 层有两个神经元。target 代表 Label 数据。假设我们网络内不存再bias,只有 weight 是需要学习的,那么我们需要根据 target 和神经网络的 output 之间的误差值(Loss)来修改 weight 值,以达到学习的效果。在这里我们以
w5
w_5
w
5
这个学习参数为例,通过
反向链式求导
来计算它的梯度:Loss 是指两个 output 值与 target 之间的 MSE Error。对
w5
w_5
w
5
进行反向求导,由于从
h1
h_1
h
1
到
o1
o1
o
1
是先经过
Li
n
e
a
r
Linear
L
i
n
e
a
r
层(FC层)再经过一个
si
g
m
o
i
d
sigmoid
s
i
g
m
o
i
d
层,再输出到
o1
o_1
o
1
的。因此从
o1
o_1
o
1
到
h1
h_1
h
1
的反向求导需要先对
si
g
m
o
i
d
sigmoid
s
i
g
m
o
i
d
这个计算过程求导,再对
Li
n
e
a
r
Linear
L
i
n
e
a
r
计算过程求导,这就是为什么上图中会先对
Os
1
Os_1
O
s
1
求导,再对
O1
O_1
O
1
求导。
我们计算随机生成一个 target 让其与我们的 output 进行 Loss 计算:
net.zero_grad() # 先清空网络中的梯度变量中的值
target = torch.rand(1, 10) # 随机生成target标签
criterion = nn.MSELoss()
loss = criterion(target, out) # 计算loss值
loss.backward() # 反向求导函数
这时,我们已经计算出所有的梯度了,现在需要我们去 update 这些 weights 的值,最简单的更新的方式是使用 SGD 的方法,即
w
e
i
g
h
t
=
w
e
i
g
h
t
−
g
r
a
d
i
e
n
t
∗
l
e
a
r
n
i
n
g
r
a
t
e
weight = weight – gradient * learning_rate
w
e
i
g
h
t
=
w
e
i
g
h
t
−
g
r
a
d
i
e
n
t
∗
l
e
a
r
n
i
n
g
r
a
t
e
,除此之外还有 Adam,RMSProp等等,Pytorch 将这些更新的算法称作“优化器”(optimizer)封装在了函数里,我们只需要调用就可以了:
import torch.optim as optim
optimizer = optim.SGD(net.parameters(), lr=0.01)
# 每一轮训练的时候
optimizer.zero_grad() # 一定要记得清空优化器中的上一轮梯度信息
output = net(input)
loss = criterion(output, target)
loss.backward()
optimizer.step() # 更新梯度信息
至此我们已经完成了 Pytorch 的安装并使用 torch 搭建了一个前向神经网络以及反向传播的全过程。
2.3 创建属于自己的Dataset和DataLoader
现在我们已经成功搭建了一个CNN网络了,问题是我们的CNN网络只能接收数字类型的 Input,而我们往往数据集都是图片类型的,因此为了将图片数据转换为神经网络能够接收的数字类型,我们需要写 Dataset 类和 DataLoader 类,这两个类的作用分别为:
Dataset 类的作用
Dataset 用于读取对应路径的数据集(比如说某个特定文件夹下的图片)并转换成神经网络能够接收的数据类型,举例来说,我们要用人脸识别数据集做训练,那么我们就需要编写一个 FaceDataset() 来把人脸的图片转换向量数据。
DataLoader 类的作用
往往在我们训练神经网络时都会使用到 mini-batch 的方法,一次读取多个样本而不是只读一个样本,那么如何从数据集中去采样一个batch的数据样本就是 DataLoader 要实现的功能了。
我们使用 Face Landmark 的数据集来举例,下载一个
Landmark
数据集,这个数据集中包含【人脸图片】和【Landmark】两个数据,Landmark 是指人脸上的68个特征点(不清楚的可以查查dlib这个库)。如下图所示:

Landmark 就是指红色的68个点,在数据集中存放的是这68个点的(x,y)坐标。
2.3.1 编写Dataset类
我们现在来写一个 FaceLandmarksDataset() 类用于读取数据中的【人脸图片】和【Landmark】信息,对于 FaceLandmarksDataset() 这个类我们继承自 torch 的 Dataset 类,并且实现三个方法:
__init__
,
__len__
,
__getitem__
。
__len__
方法用于返回这个 Dataset 的数据集长度共有多少个。
__getitem__
可以让你在调用 dataset[i] 的时候直接调用这个方法,非常方便。
import os
import torch
import pandas as pd
from skimage import io, transform
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, utils
# Create a Dataset Class to transform the image data to array data
class FaceLandmarksDataset(Dataset):
def __init__(self, root, transform=None):
self.root = root # root 是指你存放数据集的路径
self.transform = transform # transform 是数据预处理的方法,后面会讲,这里先跳过
data = pd.read_csv(os.path.join(root, "face_landmarks.csv"))
self.image_names = data.iloc[:, 0].as_matrix() # 数据集的第一列是图片的名字
self.land_marks = data.iloc[:, 1:].as_matrix() # 数据集的后面列全是landmarks
def __len__(self):
return len(self.image_names)
def __getitem__(self, idx):
assert isinstance(idx, int), "Idx must be int."
land_marks = self.land_marks[idx, :].reshape(-1, 2)
image_name = self.image_names[idx]
image = io.imread(os.path.join(self.root, image_name))
sample = {"image": image, "landmarks": land_marks} # 定义sample的数据结构是个字典{人脸图片(np.array),landmarks(np.array)}
if self.transform:
sample = self.transform(sample)
return sample
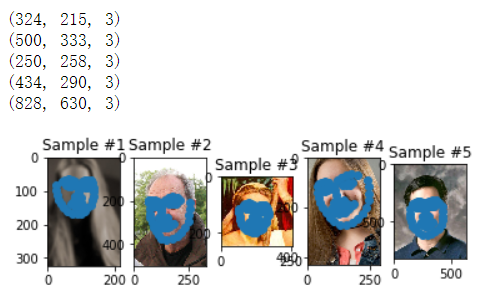
这样我们就写好了一个读取自己数据集的 Dataset 类,现在来尝试使用这个类:
def show_landmarks(sample, ax):
print(sample["image"].shape)
ax.imshow(sample["image"])
ax.scatter(sample["landmarks"][:, 0], sample["landmarks"][:, 1])
face_dataset = FaceLandmarksDataset("./faces") # 实例化
for i in range(5):
sample = face_dataset[i] # 这里会调用类中的 __getitem__()方法
ax = plt.subplot(1, 5, i+1)
ax.set_title("Sample #" + str(i+1))
show_landmarks(sample, ax)
plt.show()
结果如下所示,画出了五张人脸以及他们对应的 landmark 点:
2.3.2 编写Transform类
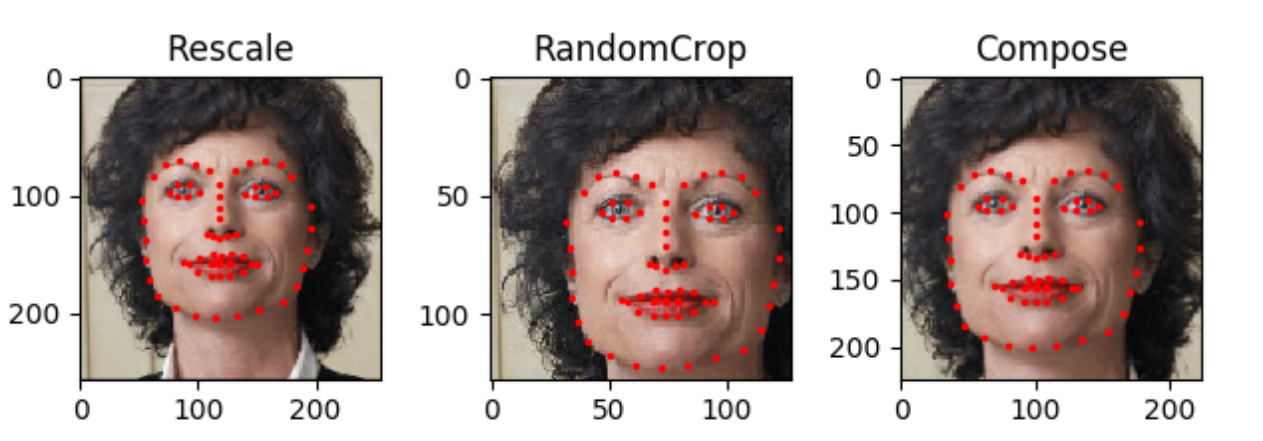
为什么会有 Transform 类?这是因为在很多时候我们并不是把原图传入神经网络,在输入数据之前会对原数据进行一些列的预处理(preprocessing),例如:数据集中的图片不会全部都是相同尺寸的,但大多神经网络都需要输入图片的尺寸是固定的,因此我们需要对数据集中的做预处理,resize 或是 crop 以保证输入数据的尺寸是符合神经网络要求的。Transform 类就是用于做数据预处理而设计的类,我们一共设计三个类来组成 Transform 类:Rescale(), RandomCrop(),ToTensor():
Rescale类
:这个类用于对图片进行 resize。
RandomCrop类
:这个用于对图片进行裁剪,且是任意位置随机裁剪。
ToTensor类
:这个类用于将 np 数组格式转换成 torch 中 tensor 的格式,图片的 np 数组是 [height, width, channel],而 torch 中图片的 tensor 格式是 [channel, height, width]。
这些类中都要实现
__call__
方法,call 方法可以使得这些类在被
实例化
的时候就调用
__call__
函数下的方法。
class Rescale(object):
def __init__(self, output_size):
assert isinstance(output_size, (list, tuple)), "output size must be tuple or list."
self.output_size = output_size
def __call__(self, sample):
image, land_marks = sample["image"], sample["landmarks"]
h, w = image.shape[:2]
new_h, new_w = self.output_size
img = transform.resize(image, (int(new_w), int(new_h)))
land_marks = land_marks * [new_w / w, new_h / h]
return {'image': img, "landmarks": land_marks}
class RandomCrop(object):
def __init__(self, output_size):
assert isinstance(output_size, (int, tuple)), "output size must be int or tuple."
if isinstance(output_size, int):
self.output_size = [output_size, output_size]
else:
assert len(output_size) == 2, "output size tuple's length must be 2."
self.output_size = output_size
def __call__(self, sample):
image, land_marks = sample["image"], sample["landmarks"]
h, w = image.shape[:2]
crop_h, crop_w = self.output_size
top = np.random.randint(0, h - crop_h)
left = np.random.randint(0, w - crop_w)
image = image[top:top+crop_h, left:left+crop_w]
land_marks -= [left, top]
return {"image":image, "landmarks":land_marks}
class ToTensor(object):
def __call__(self, sample):
image, land_marks = sample["image"], sample["landmarks"]
image = image.transpose((2, 0, 1))
return {"image":image, "landmarks":land_marks}
这样我们就实现好了这三个功能的类,接下来我们将这三个方法合成一个方法,可以依次按顺序对一个 sample 做这三个操作。通过
torchvision.transforms()
来融合这三个方法。
scale = Rescale((256, 256)) # 单实现 Resacle 处理
random_crop = RandomCrop(128) # 单实现 RandomCrop 处理
compose = transforms.Compose([Rescale((256, 256)), RandomCrop(224)]) # 对一个sample先Rescale再RandomCrop
sample = face_dataset[66]
for i, tsfm in enumerate([scale, random_crop, compose]): # 同时展示Rescale、RandomCrop和先Resacle再RandomCrop的效果
transformed_data = tsfm(sample)
ax = plt.subplot(1, 3, i+1)
ax.set_title(type(tsfm).__name__)
show_landmarks(transformed_data, ax)
plt.show()
效果如下,Compose 是指结合了前两种方法,先 resize 后再随机 Crop 后的样子:
2.3.3 将Transform融合到Dataset中去
前面提到,Transform 的作用是做数据预处理的,因此我们期望每次从 Dataset 中读取数据的时候,这些数据都被预处理一次,因此我们可以把 Transform 融合到 Dataset 中去,还记得我们在写 Dataset 的时候有留一个参数 transform 吗?我们现在可以传进去就好了:
transformed_dataset = FaceLandmarksDataset(root='./faces',
transform=transforms.Compose([Rescale((256, 256)),
RandomCrop(224),
ToTensor()]))
这样我们就写好了一个带有 Transform 的 Dataset 了。
2.3.4 编写DataLoader类
在有了 Dataset 类后,我们就可以开始编写 DataLoader 类了,Dataloader 主要是从Dataset 中去 sample 一个batch 的数据。我们可以直接使用 Pytorch 提供的 Dataloader 类:
dl = torch.utils.data.DataLoader(transformed_dataset, batch_size=4, shuffle=True, num_workers=4) # windows下num_workers参数要等于0,不然会报错
这样就可以从我们的 Dataset 中取一个batch 的数据了,下面我们来看看怎么用 dataloader 取出 batch data:
def show_landmark_batch(sample_batch):
images_batch, landmarks_batch = sample_batch["image"], sample_batch["landmarks"]
batch_size = len(images_batch)
im_size = images_batch.size(2)
grid = utils.make_grid(images_batch)
plt.imshow(grid.numpy().transpose(1, 2, 0))
grid_border_size = 2
for i in range(batch_size):
plt.scatter(landmarks_batch[i, :, 0].numpy() + i * im_size + (i + 1) * grid_border_size, landmarks_batch[i, :, 1].numpy() + grid_border_size, s=10)
plt.title("Batched Samples")
for i_batch, sample_batch in enumerate(dl): # dataloader是一个迭代器,迭代一次取出一个batch的sample
if i_batch == 0:
show_landmark_batch(sample_batch)
plt.show()
可视化结果如下:

2.4 使用Tensorboard来可视化训练过程
Tensorboard 无疑是一个非常好用且直观的神经网络训练可视化利器,Pytorch 中也集成了使用 Tensorboard 方法,建立一个SummaryWriter() 类即可完成各种类型的可视化,下面我们就一起尝试使用 Tensorboard 来做可视化。
2.4.1 Images可视化
有时候我们拿到的只是图片信息的向量信息(例如MNIST数据集),我们想查看这些图片到底长什么样,这时候我们可以往 Tensorboard 中添加图片数据信息来可视化这些图片,首先我们先建立一个 writer 对象。
from torch.utils.tensorboard SummaryWriter
writer = SummaryWriter("run/experience_1") # 将log信息都保存在run/experience_1的目录下
这样我们就建立好了一个 writer 对象,之后的所有操作都通过 writer 对象来完成。
import matplotlib.pyplot as plt
import numpy as np
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
trainset = torchvision.datasets.FashionMNIST('./data', download=True, train=True, transform=transform) # 加载数据集
testset = torchvision.datasets.FashionMNIST('./data', download=True, train=False, transform=transform) # 加载数据集
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4, shuffle=True)
testloader = torch.utils.data.DataLoader(testset, batch_size=4, shuffle=True)
classes = ('T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle Boot')
dataiter = iter(trainloader)
images, labels = dataiter.next()
img_grid = torchvision.utils.make_grid(images) # 获取一个batch的数据并将4张图片合并成一张图片
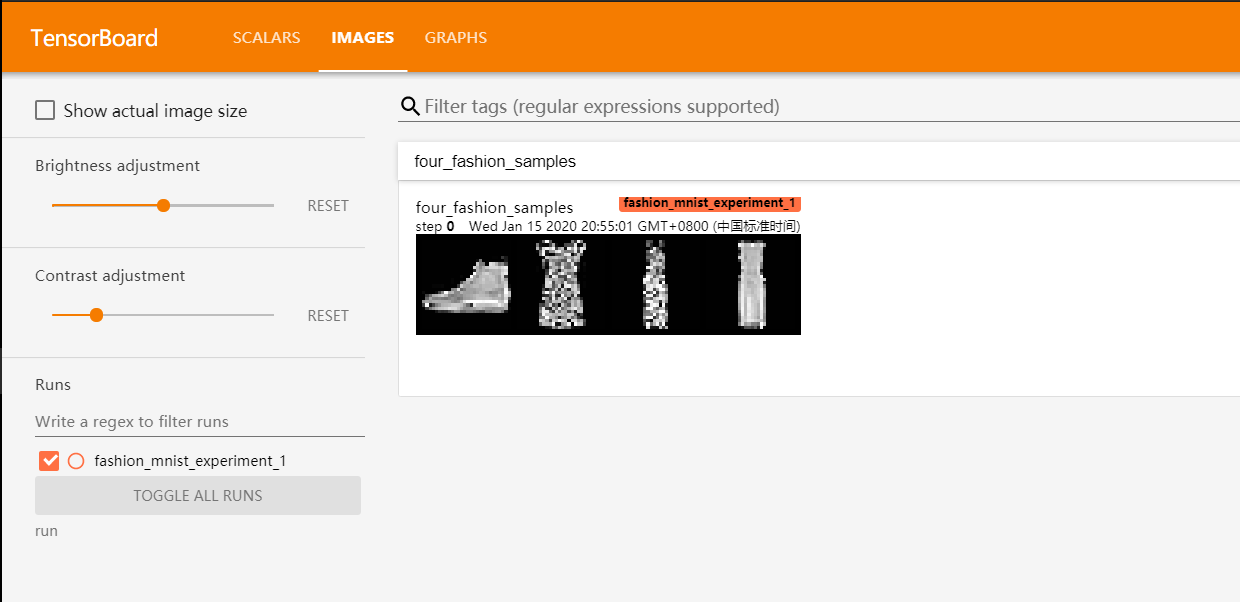
writer.add_image("four_fashion_samples", img_grid) # 将图片数据添加到 Tensorboard->(图片名称,图片数据)
这时候我们前往“run”文件夹存放的目录,在终端中输入
tensorboard --logdir=run
来开启Tensorboard:

打开后如下所示,可以看到在
Images
这一栏已经显示了我们刚才添加进去的图片信息:
2.4.2 Graph可视化
如果我们想更清楚的看到我们建立的神经网络模型长什么样,我们可以使用
writer.add_graph()
方法来将模型添加入 Tensorboard:
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 4 * 4, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 4 * 4)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net() # 实例化CNN网络
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
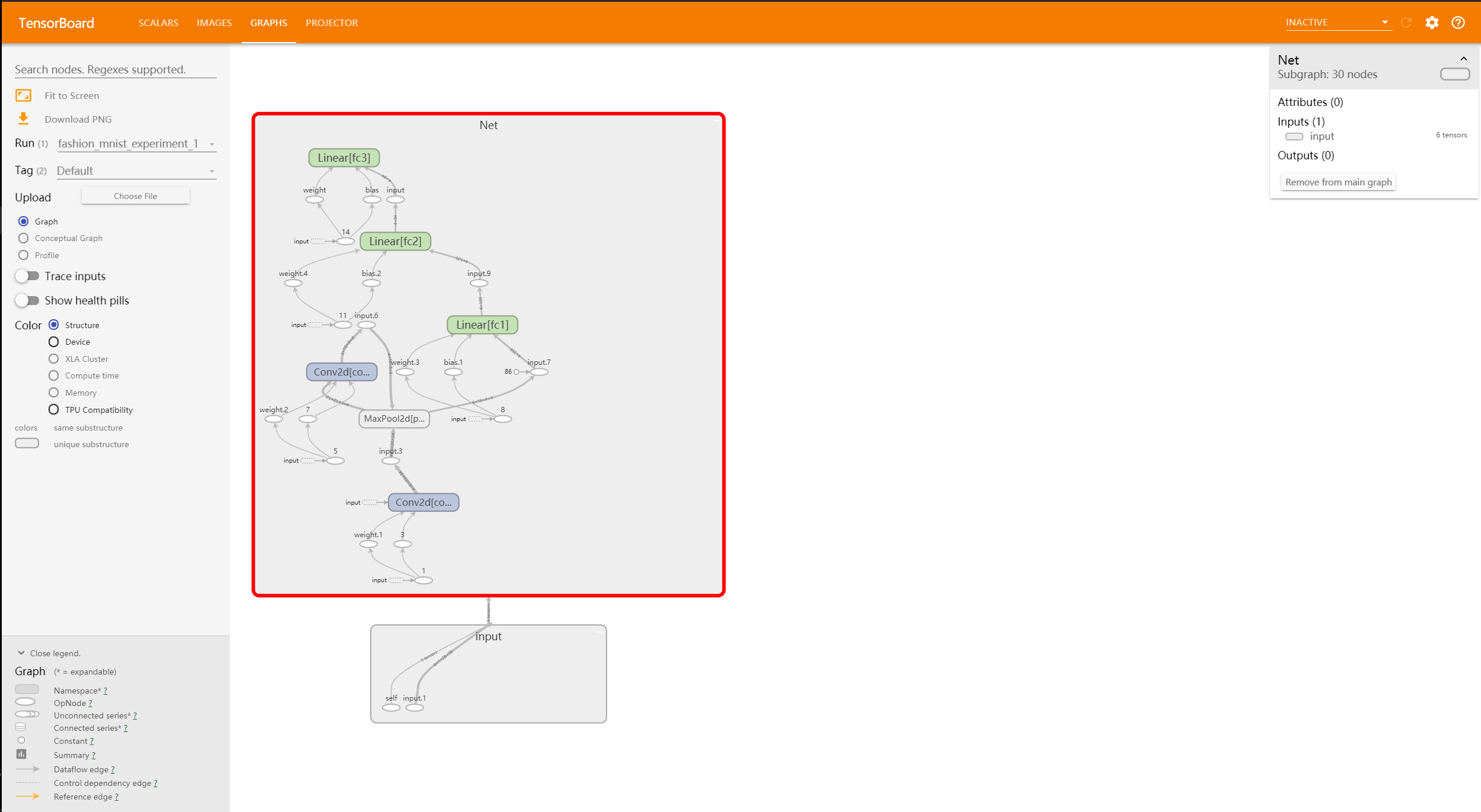
writer.add_graph(net, images) # 将网络添加入Tensorboard->(神经网络对象,随机传一组Input)
之后,我们可以在 Tensorboard 的
Graphs
这一栏看到我们整个神经网络的架构:
2.4.3 训练中的Loss,Accuracy可视化
在模型训练过程中,我们想实时的监测 Loss,Accuracy 等值的变化,我们可以通过
writer.add_scalar()
方法往 Tensorboard 中加入监测变量:
running_loss = 0.0
right_num = 0
for epoch in range(1): # loop over the dataset multiple times
for i, data in enumerate(trainloader, 0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
_, preds_tensor = torch.max(outputs, 1)
right_num += (preds_tensor.numpy() == labels.numpy()).sum()
running_loss += loss.item()
if i % 1000 == 999: # 每1000步更新一次
running_loss /= 1000
accaracy = right_num / 4000
writer.add_scalar('training/loss', running_loss, epoch * len(trainloader) + i) # 添加Loss监测变量->(变量名称,变量值,step)
writer.add_scalar('training/accaracy', accaracy, epoch * len(trainloader) + i) # 添加Accuracy监测变量->(变量名称,变量值,step)
print("[%d] Loss: %.4f Acc: %.2f" % (i, running_loss, accaracy))
running_loss = 0.0
right_num = 0
print('Finished Training')
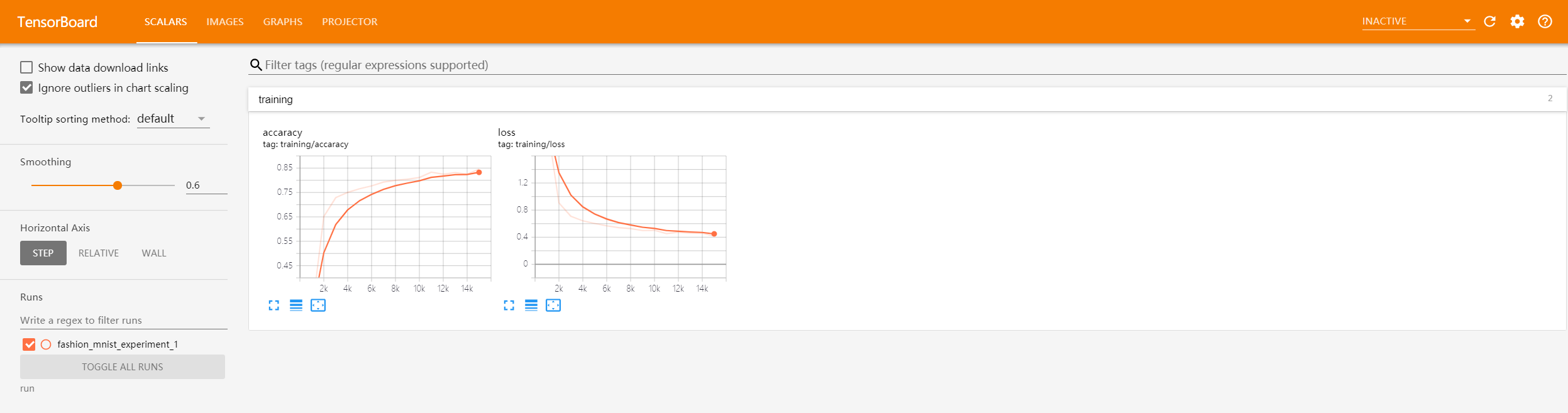
在训练过程中,在
Scalars
一栏可以监测“Loss”和“Accuracy”的变化情况(Tensorboard默认每30s刷新一次),训练结果如下所示:
2.5 Pytorch实现DQN算法
Deep Reinforcement Learning 结合了深度学习和增强学习,使得增强学习能有更好的效用。这次我们使用Pytorch来实现一个DQN,学会玩 CartPole-v0 的立杆游戏。DQN 一共分为
target network
和
evaluate network
,我们在 DQN 类中会实现这两个网络。在更新 evaluate network 时,我们使用
q
e
v
a
l
q_{eval}
q
e
v
a
l
和
r
t
+
γ
∗
q
n
e
x
t
r_t+\gamma*q_{next}
r
t
+
γ
∗
q
n
e
x
t
之间的差作为 Loss 值来更新网络,其中
q
e
v
a
l
q_{eval}
q
e
v
a
l
来自
evaluate network
,
q
n
e
x
t
q_{next}
q
n
e
x
t
来自
target network
。DQN架构图和 net 示意图如下所示:(这里默认已经有DQN的基础,如果不清楚DQN可以参考
强化学习入门笔记
)。

import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import gym
from torch.utils.tensorboard import SummaryWriter
# Hyper Parameters
EPOCH = 400
BATCH_SIZE = 32
LR = 0.01 # learning rate
EPSILON = 0.9 # greedy policy
GAMMA = 0.9 # reward discount
TARGET_REPLACE_ITER = 100 # target update frequency
MEMORY_CAPACITY = 2000
env = gym.make('CartPole-v0')
env = env.unwrapped
N_ACTIONS = env.action_space.n
N_STATES = env.observation_space.shape[0]
import 一些包和定义一些超参数,这里要用到 gym 库,需要先pip install gym。
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(N_STATES, 20)
self.fc1.weight.data.normal_(0, 0.1)
self.fc2 = nn.Linear(20, N_ACTIONS)
self.fc2.weight.data.normal_(0, 0.1)
def forward(self, x):
x = F.relu(self.fc1(x))
return self.fc2(x)
定义一个Net类,这里我们只有一层 Hidden Layer。输入为 gym 给的 observation 的维度,输出为 action_space 的维度,下面我们实现 DQN 类。
class DQN(object):
def __init__(self):
self.target_net, self.evaluate_net = Net(), Net()
self.memory = np.zeros((MEMORY_CAPACITY, N_STATES * 2 + 2))
self.loss_Function = nn.MSELoss()
self.optimizer = torch.optim.Adam(self.evaluate_net.parameters(), lr=LR)
self.point = 0
self.learn_step = 0
def choose_action(self, s):
s = torch.unsqueeze(torch.FloatTensor(s), 0) # torch 不支持传入单样本,只能传入batch的data,因此这里单样本数据需要提升一个维度
if np.random.uniform() < EPSILON: # epsilon-greedy探索
return torch.max(self.evaluate_net.forward(s), 1)[1].data.numpy()[0]
else:
return np.random.randint(0, N_ACTIONS)
def store_transition(self, s, a, r, s_):
self.memory[self.point % MEMORY_CAPACITY, :] = np.hstack((s, [a, r], s_))
self.point += 1
def sample_batch_data(self, batch_size):
perm_idx = np.random.choice(len(self.memory), batch_size)
return self.memory[perm_idx]
def learn(self) -> float:
if self.learn_step % TARGET_REPLACE_ITER == 0:
self.target_net.load_state_dict(self.evaluate_net.state_dict())
self.learn_step += 1
batch_memory = self.sample_batch_data(BATCH_SIZE)
batch_state = torch.FloatTensor(batch_memory[:, :N_STATES])
batch_action = torch.LongTensor(batch_memory[:, N_STATES : N_STATES + 1].astype(int))
batch_reward = torch.FloatTensor(batch_memory[:, N_STATES + 1 : N_STATES + 2])
batch_next_state = torch.FloatTensor(batch_memory[:, -N_STATES:])
q_eval = self.evaluate_net(batch_state).gather(1, batch_action) # 由于返回的是对每个action的value,因此用gather()去获得采取的action对应的value
q_next = self.target_net(batch_next_state).detach() # target network是不做更新的,所以要detach()
q_target = batch_reward + GAMMA * q_next.max(1)[0].view(BATCH_SIZE, 1)
loss = self.loss_Function(q_eval, q_target)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
return loss.data.numpy()
DQN中一共有几个需要注意的部分:
memory
,
target network
,
evaluate network
。其中 memory 是一个环形的队列,当经验池满了之后就会把旧的数据给覆盖掉。
target network
会在一定的steps之后把
evaluate network
的参数直接复制到自己的网络中。
dqn = DQN()
writer = SummaryWriter("run/MemoryCapacity_100_CustomReward/")
writer.add_graph(dqn.evaluate_net, torch.randn(1, N_STATES))
global_step = 0
for i in range(EPOCH):
s = env.reset()
running_loss = 0
cumulated_reward = 0
step = 0
while True:
global_step += 1
env.render()
a = dqn.choose_action(s)
s_, r, done, _ = env.step(a)
# 自定义reward,不用原始的reward
x, x_dot, theta, theta_dot = s_
r1 = (env.x_threshold - abs(x)) / env.x_threshold - 0.8
r2 = (env.theta_threshold_radians - abs(theta)) / env.theta_threshold_radians - 0.5
r = r1 + r2
dqn.store_transition(s, a, r, s_)
cumulated_reward += r
if dqn.point > MEMORY_CAPACITY: # 在经验池满了之后才开始进行学习
loss = dqn.learn()
running_loss += loss
if done or step > 2000:
print("【FAIL】Episode: %d| Step: %d| Loss: %.4f, Reward: %.2f" % (i, step, running_loss / step, cumulated_reward))
writer.add_scalar("training/Loss", running_loss / step, global_step)
writer.add_scalar("training/Reward", cumulated_reward, global_step)
break
else:
print("\rCollecting experience: %d / %d..." %(dqn.point, MEMORY_CAPACITY), end='')
if done:
break
if step % 100 == 99:
print("Episode: %d| Step: %d| Loss: %.4f, Reward: %.2f" % (i, step, running_loss / step, cumulated_reward))
step += 1
s = s_
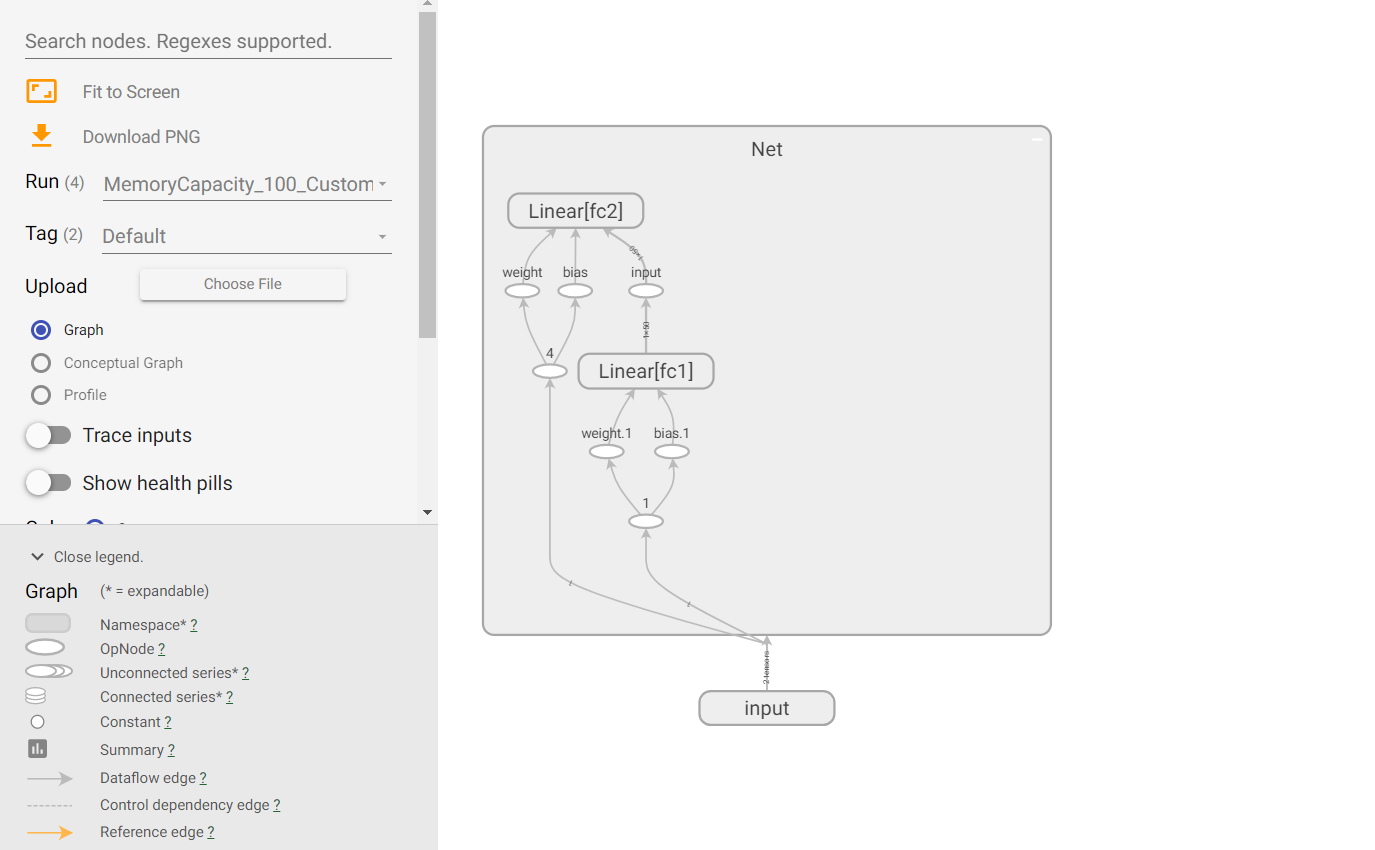
以上是学习的过程,在 reward 的那个地方,使用了自定义的 reward,而不是使用 gym 给定的 r,合理的制定 reward 可以帮助模型学的更好的效果,我们后面会对使用不同的 reward 学习的效果进行对比。模型结构如下图所示:
训练过程中,按照上一节讲的内容利用 tensorboard 追踪 Loss 和 Reward 两个变量的值变化情况:
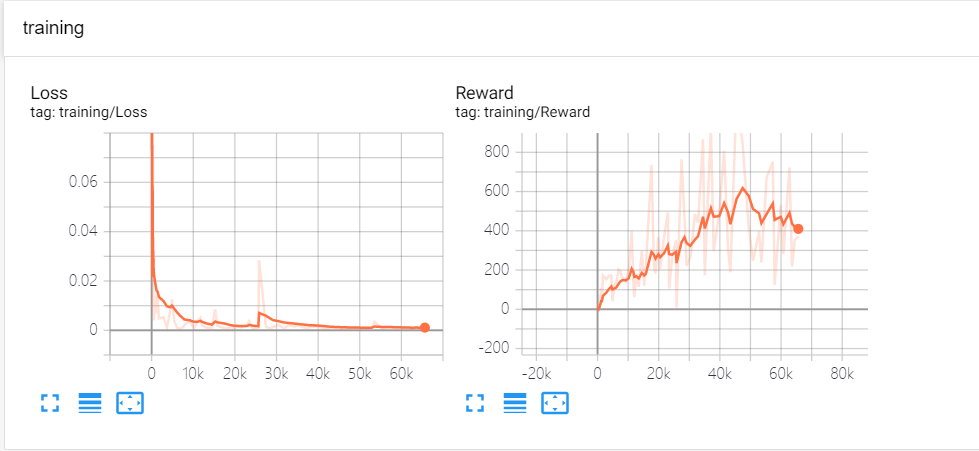
可以看到,Loss 的值在逐步趋于0,这说明模型是趋于收敛的,Reward 值也在总体上升,最高达到600左右(做了 smooth 后的值,不是原本值),倒立摆能够稳住很长一段时间。下面我们来看一下,如果我们修改部分超参数的值会出现什么样的训练效果,我一共做了4个对比试验:
- 使用自定义回报值,经验池容量设置为100
- 使用默认回报值,经验池容量为100
- 使用默认回报值,使用更为复杂的网络结构,经验池容量为100
- 使用默认回报值,使用更为复杂的网络结构,经验池容量为2000
-
回报值设定对模型效果的影响
在经验池容量和模型结构都相同的情况下,使用自定义回报(橘色)和默认回报(蓝色)的效果如下图所示:
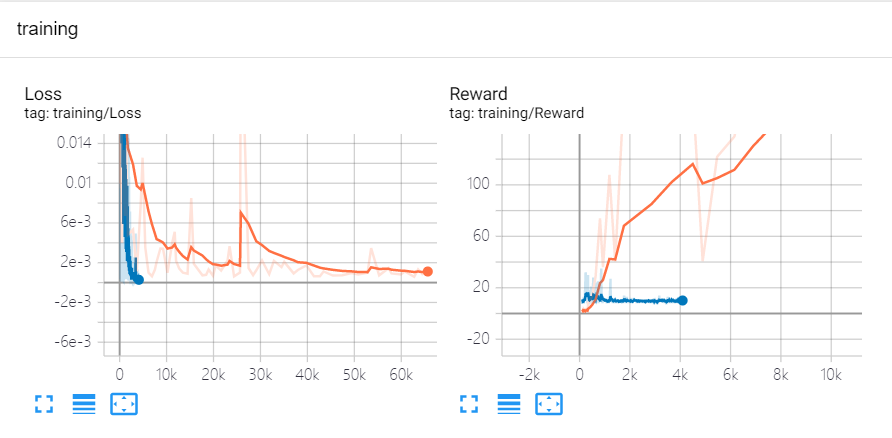
可以看到,Loss 函数最终都是趋于很小的值,这说明使用两种方法模型都是收敛的,但是 Reward 值差别非常大。为什么同样都是收敛的情况下,效果差这么多?这是因为,模型收敛是指:训练出来的Q-Net总会选择含有最大Q值的Action(这样的Loss最小)。但是Action的Q值是通过 Reward 来计算的:
r
t
+
a
r
g
m
a
x
a
Q
π
(
s
,
a
)
r_t + argmax_aQ^\pi(s, a)
r
t
+
a
r
g
m
a
x
a
Q
π
(
s
,
a
)
。因此, reward 的制定直接决定了模型效果的好坏。所以,如果 reward 不能很好的与最终效用产生紧密的联系,模型虽然能有找到最大效用行为的能力,但这个最大效用的行为并不能产生很好的效果。
因此,如果看到 Loss 已经很小,但最终效用不怎么好的情况下,一般就考虑重新制定 reward,选择一个能够更精准表示最终效用的评价函数。
-
模型复杂度对效用的影响
在经验池容量相同且均使用默认回报的情况下,尝试修改原有模型,使得模型变得稍微复杂一些,看看效果会不会更好一些,将模型再加一层 hidden layer 并且增加每一层神经元的个数,代码如下:
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(N_STATES, 80)
self.fc1.weight.data.normal_(0, 0.1)
self.fc2 = nn.Linear(80, 40)
self.fc2.weight.data.normal_(0, 0.1)
self.fc3 = nn.Linear(40, N_ACTIONS)
self.fc3.weight.data.normal_(0, 0.1)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
return self.fc3(x)
模型结构如下:
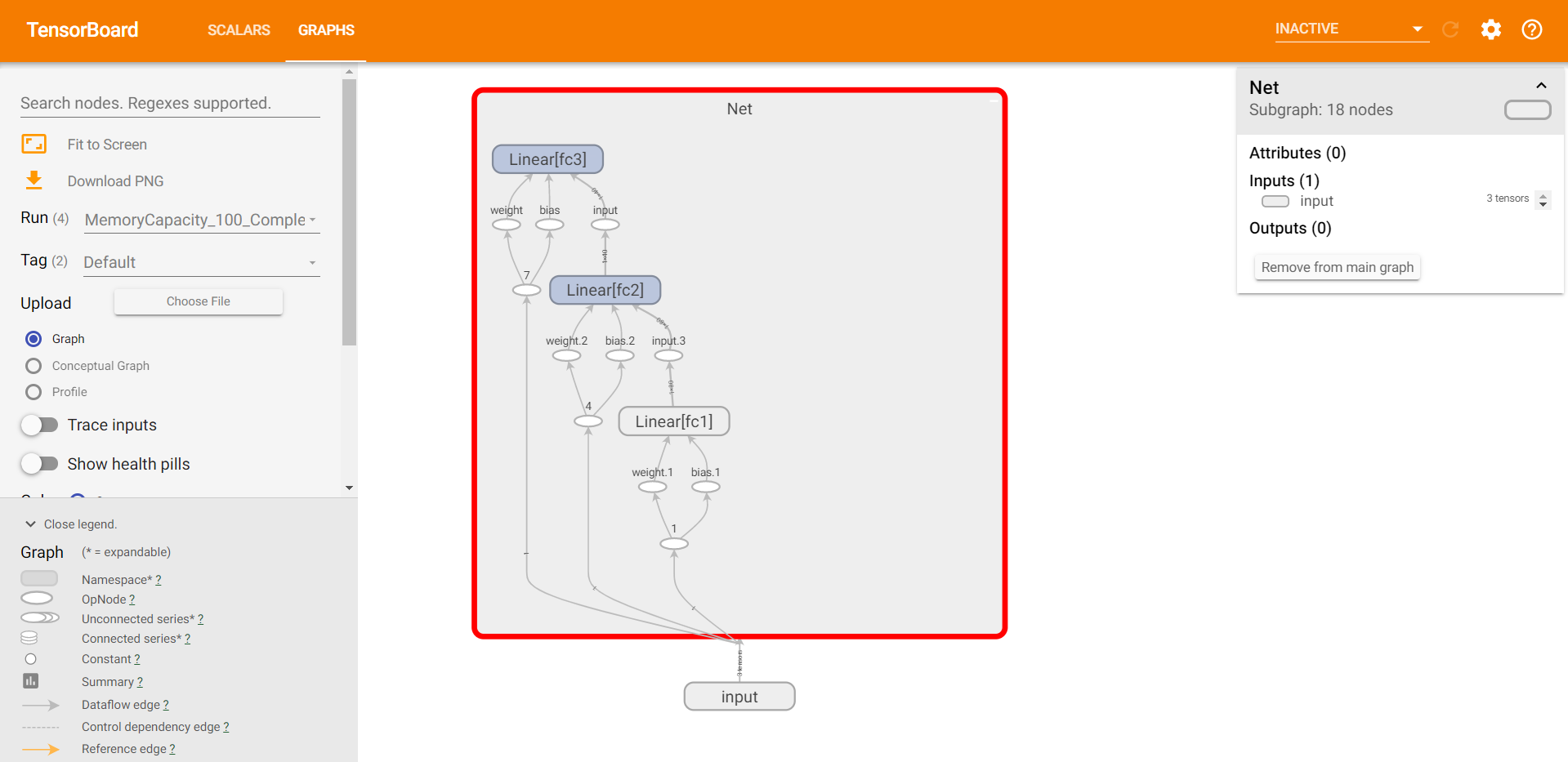
使用复杂模型(红色)和使用简单模型(蓝色)的 Reward 情况对比如下:
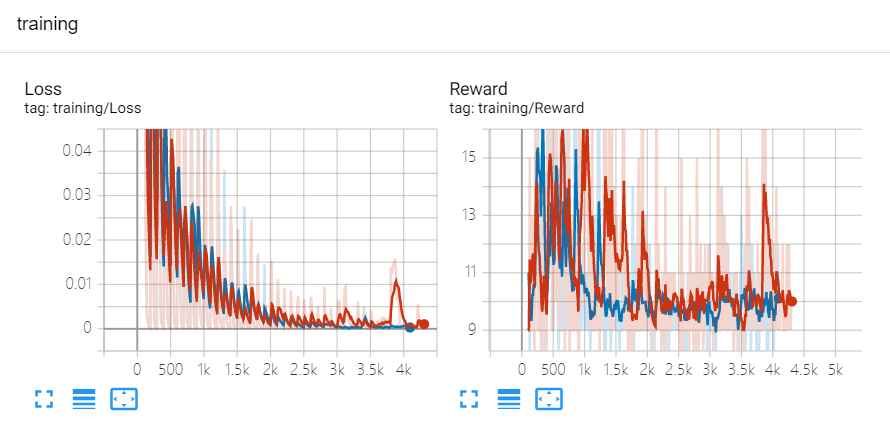
可以看到,两个模型 Loss 都是趋于0,证明模型均收敛,红色(复杂)模型的得比蓝色(简单)模型要稍微高一些,但和使用自定义回报的模型比起来还是差很远。
-
经验池容量对模型效果的影响
对于相同复杂度的模型,使用相同回报值,通过改变经验池容量来观察对模型效果有什么影响,容量为100(红色)和容量为2000(蓝色)模型的对比结果如下:
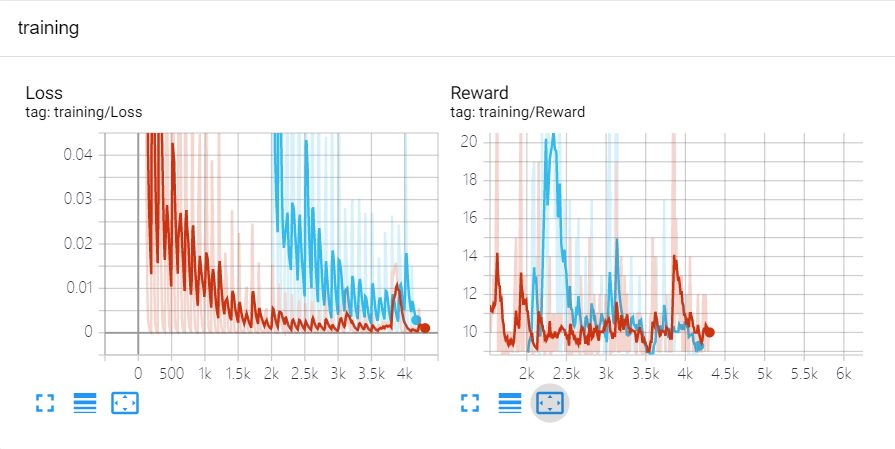
观察可得,扩展经验池后的效果会比小经验池的效果要好一些。因此,通过以上总结,我们可以得出在DQN中不同超参数对模型效果影响程度的结论,即:
回报函数制定 > 经验池容量 > 模型复杂度
。
2.6 Pytorch实现Policy Gradient算法
在实现了 DQN 这种 value-based 的算法之后,我们尝试实现一种 policy-based 的方法:Policy-Gradient。策略梯度是很多经典算法的基石,包括 A3C,PPO在内的多种算法都是基于策略梯度的基本思想来实现的,因此这次我们同样基于 CartPole 的简单场景来实现 Policy Gradient 算法(默认已经有PG的基础,如果不清楚PG可以参考
强化学习入门笔记
)。
Policy Gradinet 的示意图如下,根据输入observation,策略决策网络会输出每一个action对应被采取的概率(效用越高的action概率就会被预测的越大)。我们可以根据这个概率来进行行为选择,这里和上面的DQN不一样,DQN的行为选择是一定概率选择最大效用的行为,一定概率随机选行为,在PG算法中直接按照概率来选行为,即结合了多选择高效用的行为的标准,又结合了一定概率进行行为探索的标准。一旦选择好了一个行为后,我们就去计算这个行为的效用是多少,如果效用高,我们就增加这个动作的概率;反之则降低选择该行为的概率。
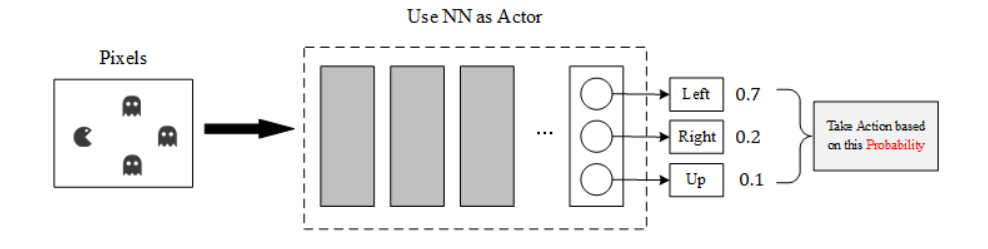
先定义神经网络层,这里使用1个 hidden layer,10个神经元:
import gym
import numpy as np
import torch
import torch.nn.functional as F
import torch.nn as nn
import matplotlib.pyplot as plt
from torch.utils.tensorboard import SummaryWriter
WRITE_TENSORBOARD_FLAG = True
class Net(nn.Module):
def __init__(self, observation_dim, action_dim):
super(Net, self).__init__()
self.observation_dim = observation_dim
self.action_dim = action_dim
self.fc1 = nn.Linear(self.observation_dim, 10)
self.fc2 = nn.Linear(10, self.action_dim)
def forward(self, x):
x = F.tanh(self.fc1(x))
return F.softmax(self.fc2(x))
随后我们定义PolicyGradient类,由于Policy Gradient中梯度计算公式为:
▽
θ
l
o
g
π
θ
(
a
∣
s
)
R
(
a
)
\bigtriangledown{_\theta}log\pi_\theta(a|s)R(a)
▽
θ
l
o
g
π
θ
(
a
∣
s
)
R
(
a
)
,
π
θ
(
a
∣
s
)
\pi_\theta(a|s)
π
θ
(
a
∣
s
)
是在网络参数为
θ
\theta
θ
的情况下,行为a被选择的概率,
R
(
a
)
R(a)
R
(
a
)
是行为a选择后能得到的总回报值,这个回报值通常使用
R
(
a
)
=
∑
t
=
0
T
γ
t
R
n
R(a) = \sum_{t=0}^{T}\gamma^tR_n
R
(
a
)
=
∑
t
=
0
T
γ
t
R
n
来计算,因此我们必须完整的收集了一个Epoch的数据信息后才能进行一次梯度更新(不然无法计算累计回报)。这一点也和DQN不一样,DQN可以进行单步更新,而PG不可以。
class PolicyGradient(object):
def __init__(self, observation_dim, action_dim, learning_rate=0.01, gamma=0.95):
self.observation_dim = observation_dim
self.action_dim = action_dim
self.gamma = gamma
self.ep_obs, self.ep_r, self.ep_a = [], [], []
self.net = Net(observation_dim, action_dim)
self.optimizer = torch.optim.Adam(self.net.parameters(), lr=learning_rate)
def choose_action(self, observation):
prob_list = self.net(observation)
action = np.random.choice(range(prob_list.size(0)), p=prob_list.data.numpy())
return action
def store_transition(self, obs, r, a):
self.ep_obs.append(obs)
self.ep_r.append(r)
self.ep_a.append(a)
def learn(self):
cumulative_reward_list = self.get_cumulative_reward()
batch_obs = torch.FloatTensor(np.vstack(self.ep_obs))
batch_a = torch.LongTensor(np.array(self.ep_a).reshape(-1, 1))
batch_r = torch.FloatTensor(cumulative_reward_list.reshape(-1, 1))
action_prob = self.net(batch_obs)
action_prob.gather(1, batch_a)
gradient = torch.log(action_prob) * batch_r
loss = -torch.mean(gradient) # 网络会对loss进行minimize,但我们是想做梯度上升,所以加一个负号
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
self.reset_epoch_memory()
return loss.data.numpy()
def get_cumulative_reward(self):
running_r = 0
cumulative_reward = np.zeros_like(self.ep_r)
for i in reversed(range(len(self.ep_r))):
running_r = running_r * self.gamma + self.ep_r[i]
cumulative_reward[i] = running_r
# normalize cumulative reward
cumulative_reward -= np.mean(cumulative_reward)
cumulative_reward /= np.std(cumulative_reward)
return cumulative_reward
def reset_epoch_memory(self):
self.ep_a.clear()
self.ep_obs.clear()
self.ep_r.clear()
值得注意的是,在策略梯度中其实是没有loss这个概念的(因为根本就没有标签),这个loss的梯度是我们通过
l
o
g
π
θ
(
a
∣
s
)
R
(
a
)
log\pi_\theta(a|s)R(a)
l
o
g
π
θ
(
a
∣
s
)
R
(
a
)
算出来的,由于在神经网络中我们做的是梯度下降:
θ
−
=
g
r
a
d
i
e
n
t
∗
L
e
a
r
n
i
n
g
R
a
t
e
\theta -= gradient*LearningRate
θ
−
=
g
r
a
d
i
e
n
t
∗
L
e
a
r
n
i
n
g
R
a
t
e
,但在策略梯度算法中我们是希望做梯度上升的
θ
+
=
g
r
a
d
i
e
n
t
∗
L
e
a
r
n
i
n
g
R
a
t
e
\theta += gradient*LearningRate
θ
+
=
g
r
a
d
i
e
n
t
∗
L
e
a
r
n
i
n
g
R
a
t
e
,因此我们在求得了梯度之后要添加一个负号再将其作为loss。最后,我们建立 CartPole 场景并将该算法用在训练场景上:
def main():
DISPLAY_REWARD_THRESHOLD = 200
RENDER = False
env = gym.make('CartPole-v0')
env = env.unwrapped
PG = PolicyGradient(env.observation_space.shape[0], env.action_space.n)
if WRITE_TENSORBOARD_FLAG:
writer = SummaryWriter("run/simple_model_experiment")
writer.add_graph(PG.net, torch.rand(env.observation_space.shape))
for i_eposide in range(120):
obs = env.reset()
obs = torch.FloatTensor(obs)
while True:
if RENDER: env.render()
action = PG.choose_action(obs)
obs_, reward, done, _ = env.step(action)
PG.store_transition(obs, reward, action)
if done:
ep_r = sum(PG.ep_r)
if ep_r > DISPLAY_REWARD_THRESHOLD: RENDER = True
print("episode: %d | reward: %d" % (i_eposide, ep_r))
loss = PG.learn()
if WRITE_TENSORBOARD_FLAG:
writer.add_scalar("training/loss", loss)
writer.add_scalar("training/reward", ep_r)
break
obs = torch.FloatTensor(obs_)
if __name__ == '__main__':
main()
Policy Gradient 训练结果如下:
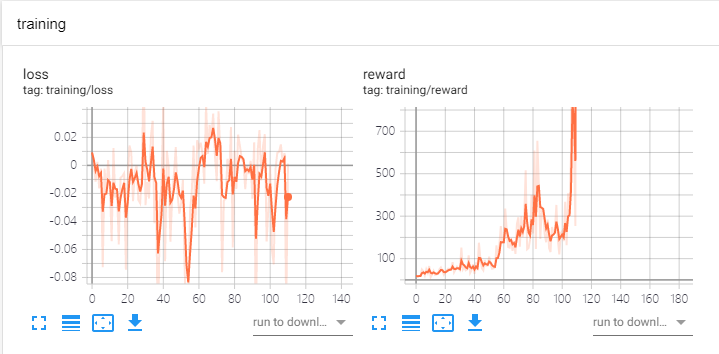
loss对应的就是每一次更新的梯度,reward对应的是模型的得分。可以看到使用策略梯度的效果还是蛮不错的,在100个Epoch之后杆子基本就可以被很好的稳住了。