目录
2、之后客户端请求与web服务器建立TCP连接(三次握手)。
4、服务器响应HTTP请求,客户端的浏览器得到HTML代码。
5、浏览器解析HTML代码,并请求HTML代码中的资源。(浏览器拿到HTML文件后,开始解析HTML代码,遇到静态资源时,就向服务器去请求下载。)
6、断开TCP连接(四次挥手),浏览器对页面进行渲染呈现给用户。
一、DNS(Dmain Name System域名系统)
1、DNS介绍
域名——因为ip地址不易记忆,所以产生了好记的域名
早期使用hosts文件解析域名,遇到的问题:主机名称重复、主机维护困难
由此产生了DNS(Dmain Name System域名系统)
2、DNS生效顺序
1、hosts文件
2、网卡配置文件
3、etc/resolve.conf
3、DNS特点
分布式——将原来的一个大型数据拆分开处理,比如售票处从原来一个窗口处理一个事项变成多个窗口同是处理一个事项,大大提升了效率(横向处理——但一旦数据会丢失就也丢失了)
层次性——比如DNS解析过程,一层层的处理(纵向式处理——数据不会丢失)
ps——能访问网站是因为DNS服务解析了域名
4、DNS与域名
(1)网络是基于TCP/IP协议进行通信和连接的,每一台主机都有一个唯一的标识(固定的IP地址),用以区别在网络上成千上万个用户和计算机。网络在区分所有与之相连的网络和主机时,均采用一种唯一、通用的地址格式,即每一个与网络相连接的计算机和服务器都被指派一个独一无二的地址。
(2)为了保证网络上每台计算机的IP地址的唯一性,用户必须向特定机构申请注册,分配IP地址网络中的地址方案分为两套:IP地址系统和域名地址系统。这两套地址系统其实是一一对应的关系,由于IP地址是数字标识,使用时难以记忆和书写,因此在IP地址的基础上又发展出一种符号化的地址方案,来代替数字型的IP地址
5、域名空间结构

6、域名注册
域名注册是internat中用于解决地址对应问题的一种方法
域名注册步骤:准备申请资料——寻找域名注册网站——查询域名——正式申请——申请成功
遵循先申请先注册原则
二、网页
1、网页的概念
网页:纯文本格式文件,在浏览器中被翻译成了网页形式显现出来
网站:多个网页的结合体
主页(首页):打开网站后出现的第一个网页为网站主页
域名:浏览网页输入的地址
http/https:通信协议
url:万维网寻址系统
html:编写网页的语言为html
超链接:将不同的网页连接起来
发布 :用文本写了一个页面,然后交给浏览器测试,浏览器测试发现不是html格式,于是无法提供服务,用户不能进行访问,如果测试是html,则提供服务,用户进行访问
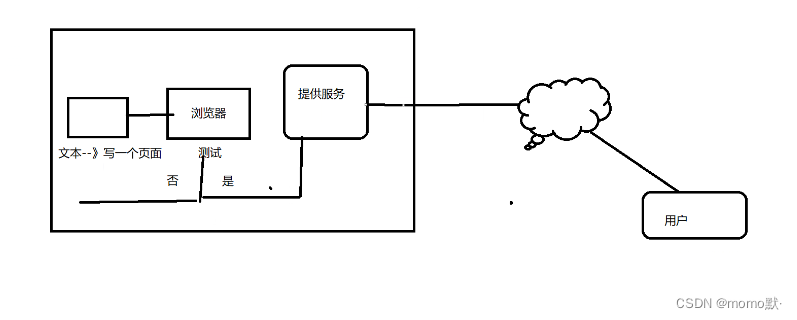
tips:至今host未被淘汰,在小型的内部局域网中依然可以使用
专线从运营商购买,3000-5000租金一月
黑屏(又称字符页面) 白屏(日常的点一点操作)
2、HTML
2.1、HTML——超文本标记语言
一种规范,也是一种标准,它通过标记符号来标记要显示的网页中的各个部分。网页文件本身是一种文本文件,通过在文本文件中添加标记符,可以告诉浏览器如何显示其中的内容。 HTML命令可以说明文字,图形、动画、声音、表格、链接等。
HTML文件可以使用任何能够生成txt文件的文本编辑器来编辑,生成超文本标记语言文件,只用修改文件名后缀为“.html”或“.htm”即可。
2.2、HTML文档结构
HTML文件最外层由< html> < /html>表示,说明该文件是用HTML语言描述的。在它里面是并列的头标签(< head>)和内容标签(< body>)。
- HTML网页
- 头部部分
- 标题部分
- 主题部分
- 网页内容,包括文本、图像等
|
头标签中常用标签 |
描述 |
|---|---|
|
<title> |
定义了文档的标题 |
|
<base> |
定义了页面链接标签的默认链接地址 |
|
<link> |
定义了一个文档和外部资源之间的关系 |
|
<meta> |
定义了HTML文档中的元数据 |
|
<script> |
定义了客户端的脚本文件 |
|
<style> |
定义了HTML文档的样式文件 |
|
内容标签中常用标签 |
描述 |
|---|---|
|
<table> |
定义了一个表格 |
|
<tr> |
定义了表格中的一行 |
|
<td> |
定义了表格中某一行的一列 |
|
<img> |
定义了一个图像 |
|
<a> |
定义了一个超链接 |
|
<p> |
定义了一行 |
|
<br> |
定义了换行 |
|
<font> |
定义了字体 |
3、web
3.1、web概述
即全球广域网,也称为万维网
一种分布式图形信息系统
建立在internet上的一种网络服务
3.2、 web1.0 和web2.0
web1.0
以编辑为特征,网站提供给用户的内容是编辑处理后的,然后用户阅读网站提供的内容
这个过程是网站到用户的单向行为
web2.0
更注重用户的交互作用,用户既是网站内容的消费者(浏览者),也是网站内容的制造者
加强了网站与用户之间的互动,网站内容基于用户提供,网站的诸多功能也由用户参与建设,实现了网站与用户双向的交流与参与
Web2.0特征(用户分享、 以兴趣为聚合点的社群、开放的平台,活跃的用户)
4、静态网页
标准的html文件
扩展名有.htm/.html(文本、图像、声音、Flash动画、客户端脚本和ActiveX控件及Java小程序等)
网站建设的基础,早期的web1.0就是以此制作的
没有后台数据库,不含程序和不可交互的网页
相对更新起来比较麻烦,适用于一般更新较少的展示型网站
每个静态网页都有一个固定的URL,且URL以.htm、.html、.shtml等常见形式为后缀,而不含有“?”
网页内容一经发布到网站服务器上,无论是否有用户访问,每个静态网页都是保存在网站服务器
静态网页的内容相对稳定,容易别搜索引擎检测
静态网页没有数据库的支持,在网站制作和维护方面工作量较大,因此当网站信息量很大时完全依靠静态网页制作方式比较困难
静态网页的交互性较差,在功能方面有较大的限制
页面浏览速度迅速,过程无需连接数据库,开启页面速度快于动态页面
TIPS——静态页面没有高频发
5、动态网页
网页URL不固定,能通过后台与用户交互
在动态网页网址中有一个标志性的符号——“?”
常用的语言有PHP、JSP、Python、Rudy等
交互性
网页会根据用户的要求和选择而动态改变和响应,将浏览器作为客户端界面,这将是今后WEB发展的大势所趋
自动更新
无须手动地更新HTML文档,便会自动生成新的页面,可以大大节省工作量
因时因人进行变化
当不同的时间,不同的人访问同一网址时会产生不同的页面
注:动态可以交互,静态不可以交互
三、HTTP
3.1、HTTP协议概述
http协议是互联网上应用最为广泛的一种网络协议,涉及这个协议的目的是为了发布和接收web服务器上的html页面。
HTTP协议采用了请求/响应模型。客户端向服务器发送一个请求,请求头包含请求的方法、URL、协议版本、以及包含请求修饰符、客户信息和内容的类似于MIME的消息结构。服务器以一个状态行作为响应,响应的内容包括消息协议的版本,成功或者错误编码加上服务器信息、实体元信息以及可能的实体内容。
客户端先是进行域名解析,然后再利用三次握手与服务器建立TCP连接。其次发送http请求,然后服务器进行回应。在断开连接时,若服务器发出的信号为Keepalive,则该连接会保持一段时间,再该时间内可继续接收请求。
HTTP 已经演化出了很多版本,它们中的大部分都是向下兼容的。
HTTP/0.9
:已过时。只接受 GET 一种请求方法,没有在通讯中指定版本号,且不支持请求头。由于该版本不支持 POST 方法,所以客户端无法向服务器传递太多信息。
HTTP/1.0
:这是第一个在通讯中指定版本号的 HTTP 协议版本,至今仍被广泛采用,特别是在代理服务器中。
HTTP/1.1
:当前版本。持久连接被默认采用,即TCP连接默认不关闭,可以被多个请求复用,并能很好地配合代理服务器工作。还支持以管道方式同时发送多个请求,以便降低线路负载,提高传输速度。
HTTP/2.0
:完全多路复用,在一个连接里,客户端和浏览器都可以同时发送多个请求和回应,而且不用按照顺序一一对应。引入头部信息压缩机制。支持服务端推送,允许服务器未经过请求,主动向客户端发送资源。
3.2、HTTP方法
HTTP 支持几种不同的请求命令,这些命令被称为 HTTP 方法(HTTP method)。每条 HTTP 请求报文都包含一个方法, 告诉服务器要执行什么动作,包括:获取一个页面,运行一个网关程序,删除一个文件等。最常用的获取资源的方法是 GET、POST。
|
HTTP 方法 |
描述 |
|
GET |
对服务器资源获取的简单请求 |
|
PUT |
向服务器提交数据,以修改数据 |
|
POST |
用于发送包含用户提交数据的请求 |
|
DELETE |
删除服务器上的某些资源 |
|
HEAD |
请求页面的首部,获取资源的元信息 |
|
CONNECT |
用于ssl隧道的基于代理的请求 |
|
OPTIONS |
返回所有可用的方法,常用于跨域 |
|
TRACE |
|
1、GET请求会向数据库发索取数据的请求,从而来获取信息,该请求不会产生副作用。无论进行多少次操作,结果都是一样的。
2、与GET不同的是,PUT请求是向服务器端发送数据的,从而改变信息,无论进行多少次PUT操作,其结果并没有不同。
3、POST请求同PUT请求类似,都是向服务器端发送数据的,但是该请求会改变数据的种类等资源,几乎目前所有的提交操作都是用POST请求的。
4、DELETE请求顾名思义,就是用来删除某一个资源的。
GET 和 POST 比较:
GET 方法
- 从指定的服务器上获得数据
- GET请求能被缓存
- GET请求会保存在浏览器的浏览纪录里
- GET请求有长度的限制
- 主要用于获取数据
- 查询的字符串会显示在URL后缀中,不安全
POST 方法
- 提交数据给指定服务器处理
- POST请求不能被缓存
- POST请求不会保存在浏览器的浏览纪录里
- POST请求没有长度限制
- 查询的字符串不会显示在URL中,比较安全
3.3、HTTP 状态码
|
状态码首位 |
已定义范围 |
分类 |
|
1xx |
100-101 |
信息提示 |
|
2xx |
200-206 |
成功 |
|
3xx |
300-305 |
重定向 |
|
4xx |
400-415 |
客户端错误 |
|
5xx |
500-505 |
服务器错误 |
|
状态码 |
功能描述 |
|---|---|
|
200 |
一切正常 |
|
301 |
永久重定向 |
|
302 |
临时重定向 |
|
401 |
用户名或密码错误 |
|
403 |
禁止访问(客户端IP地址被拒绝) |
|
404 |
文件不存在 |
|
414 |
请求URI头部过长 |
|
500 |
服务器内部错误 |
|
502 |
无效网关 |
|
503 |
当前服务不可用 |
|
504 |
网关请求超时 |
补充:409:请求的资源与资源状态发生冲突
410:请求文件永久删除
3.4、HTTP 请求流程分析
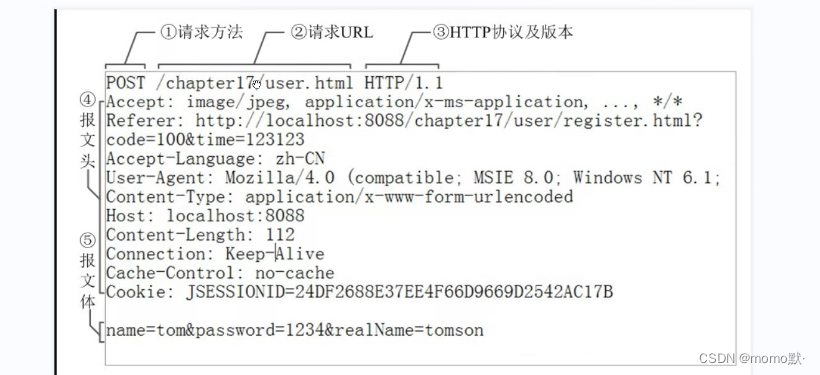
用户在浏览器输入URL访问时,发起HTTP请求报文,请求中包括请求行、请求头、请求体,服务器收到请求后返回响应报文,包括状态行、响应头、响应体。
3.4.1、请求报文
请求行
:请求行由请求方法、URL 以及协议版本三部分组成。
请求头
:请求头为请求报文添加了一些附加信息,由“名/值”对组成,每行一对,名和值之间使用冒号分隔。
空行
:请求头部的最后会有一个空行,表示请求头部结束,接下来为请求体,这一行非常重要,必不可少。
请求体:
请求体是请求提交的参数,GET 方法已经在 URL 中指明了参数,所以提交时没有数据。POST 方法提交的参数在请求体中。
|
常用请求头 |
描述 |
|
Host |
接受请求的服务器地址,可以是 IP:端口号 ,也可以是域名 |
|
User-Agent |
发送请求的应用程序名称 |
|
Connection |
指定与连接相关的属性,如Connection:Keep-Alive |
|
Accept-Charset |
通知服务端可以发送的编码格式 |
|
Accept-Encoding |
通知服务端可以发送的数据压缩格式 |
|
Accept-Language |
Accept-Language |
3.4.2、响应报文
状态行:状态行由协议版本,状态码,状态码描述三部分组成。
响应头:响应头与请求头部类似,为响应报文添加了一些附加信息
空行:响应头部的最后会有一个空行,表示响应头部结束
响应体:服务器返回的相应 HTML 数据,浏览器对其解析后显示页面。
|
响应头 |
描述 |
|
Server |
服务器应用程序软件的名称和版本 |
|
Content-Type |
响应正文的类型(是图片还是二进制字符串) |
|
Content-Length |
响应正文长度 |
|
Content-Charset |
响应正文使用的编码 |
|
Content-Encoding |
响应正文使用的数据压缩格式 |
|
Content-Language |
响应正文使用的语言 |

3.4.3、访问过程
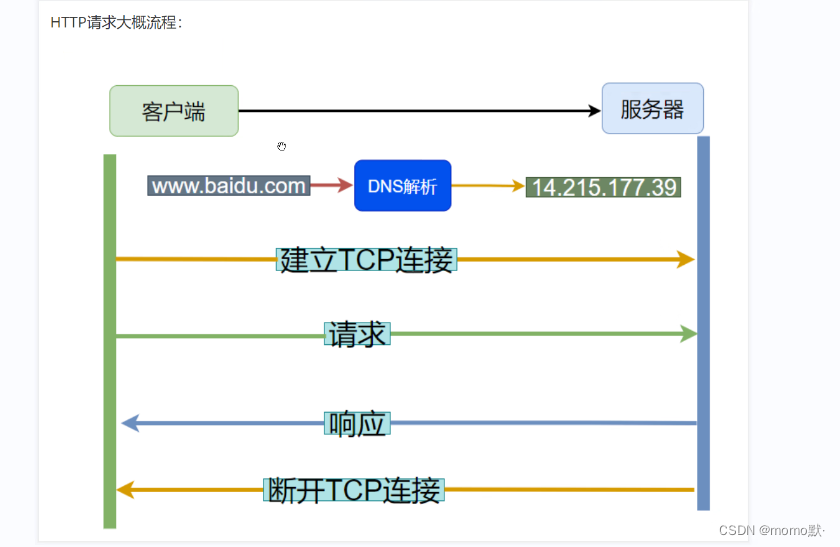
1、客户端通过域名进行访问,先进行DNS域名解析。
2、之后客户端请求与web服务器建立TCP连接(三次握手)。
3、建立连接后,客户端向web服务器发送一个HTTP请求。
4、服务器响应HTTP请求,客户端的浏览器得到HTML代码。
5、浏览器解析HTML代码,并请求HTML代码中的资源。(浏览器拿到HTML文件后,开始解析HTML代码,遇到静态资源时,就向服务器去请求下载。)
6、断开TCP连接(四次挥手),浏览器对页面进行渲染呈现给用户。
四、总结
1、socket通信=ip+端口
2、无状态——每次访问这个网页都不产生变化
3、有状态——第一次访问这个网页是这样,第二次访问就多了些变化
4、断开分两种,一种请求断开一种自动断开,当客户端超时
5、dns的产生是为了方便人们记忆
6、dns有分布式和层次性
7、(静态)web1.0是单向性的
8、(动态)web2.0是可以用户分享,双向性的
9、客户端先是进行域名解析,然后再利用三次握手与服务器建立TCP连接。其次发送http请求,然后服务器进行回应。在断开连接时,若服务器发出的信号为Keepalive,则该连接会保持一段时间,再该时间内可继续接收请求。
10、用户在浏览器输入URL访问时,发起HTTP请求报文,请求中包括请求行、请求头、请求体,服务器收到请求后返回响应报文,包括状态行、响应头、响应体。