作者 | ZZZzz 编辑 | 汽车人
原文链接:https://zhuanlan.zhihu.com/p/622919701
点击下方
卡片
,关注“
自动驾驶之心
”公众号
ADAS巨卷干货,即可获取
点击进入→
自动驾驶之心【占用网络】技术交流群
概括:
本文提出了OccFormer,一个双路径的转化器网络,以有效地处理三维体积的语义占有率预测。OccFormer 实现了对摄像机生成的三维体素特征的长距、动态和高效编码。通过将繁重的 3D 处理分解为沿水平面的局部 local 和全局 global 变换路径。对于占用率解码器 occupancy decoder,我们通过提出 preserve-pooling 和类引导采样 class-guided sampling,使虚构的 Mask2Former 适用于三维语义占用,这明显缓解了稀疏性和类不平衡。
Abstract
本文提出了OccFormer,一个双路径的转化器网络,以有效地处理三维体积的语义占有率预测。
OccFormer 实现了对相机生成的三维体素特征的长距、动态和高效编码。
通过将繁重的 3D 处理分解为沿水平面的局部 local 和全局 global 变换路径。
对于占用率解码器 (occupancy decoder),我们通过提出保留池化 (preserve-pooling) 和类引导采样 (class-guided sampling),使 Mask2Former 适用于三维语义占用,这明显缓解了稀疏性和类不平衡。
实验结果表明,OccFormer 在 SemanticKITTI 数据集的语义场景完成方面和 在 nuScenes 数据集的 LiDAR 语义分割方面明显优于现有方法。
1. Introduction
对三维环境的准确感知构成了现代自主驾驶系统的基础 ……
为此,本文着重于为周围环境的多视角图像建立一个精细的三维表示,即三维语义占用。
启发:
受到视觉变换器[14,35]在各种视觉任务中广泛成功的启发。
❝
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16×16 words: Transformers for image recognition at scale. In ICLR, 2020. Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In ICCV, 2021
动机:
我们的动机是利用注意力机制 attention mechanism 来构建三维占用预测的编码器-解码器网络 encoder-decoder network。
对于编码器部分:
我们提出了 dual-path transformer 模块,以释放 self-attention 的能力,同时限制了二次复杂性 (quadratic complexity)。
具体来说,
-
local path 沿每个二维BEV切片运行,并使用共享窗口注意力 ( shared windowed attention) 来捕捉细粒度的细节。
-
而 global path 对 collapsed 的BEV特征进行处理,以获得场景级的理解。
-
最后,双路径的输出被自适应地融合以生成输出的三维特征体 3D feature volume 。
双路径设计明显打破了三维特征体的挑战性处理,我们证明了它比传统的三维卷积有明显优势。
对于解码器部分:
我们是第一个将最先进的 Mask2Former[9] 方法用于三维语义占用预测的。
我们进一步提出使用最大池化而不是默认的双线性来计算 attention的 masked regions,这可以更好地保留小类。此外,我们还提出了 class-guided 的采样方法,以捕获前景区域,从而进行更有效的优化。
实验结果表明, OccFormer 比现有的最先进的方法更有优势,
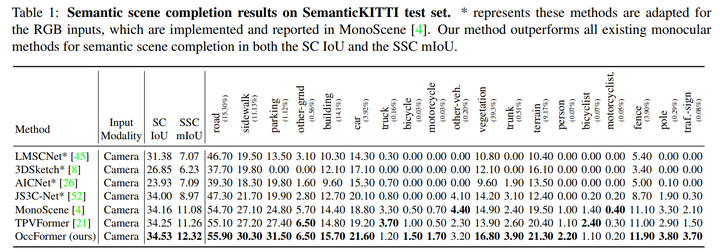
在 SemanticKITTI 单目方法排行榜中居榜首。
在 nuScenes 数据集上评估了OccFormer用于LiDAR语义分割的情况。我们的方法超过了TPV- Former 1.4% mIoU,并为三维语义占用预测产生了更完整和现实的预测。
2. Related Work
2.1. Camera-based BEV Perception
在本文中,我们将基于 BEV 的感知方法用于三维语义占用预测,其中进一步包含沿高度维度的结构信息。
2.2. 3D Semantic Occupancy Prediction
TPVFormer[21]提出了三视角视图表示法来描述三维场景的语义占有率预测。尽管它很简单,但 tri-plane 格式很容易受到细粒度语义信息的影响,导致性能下降。
在本文中,我们重新提出了密集三维特征的表达能力,并提出了基于 transformer 的编码器-解码器网络用于三维语义占用预测。
2.3. Efficient 3D Network
在三维语义场景完成领域,人们已经提出了大量的尝试来提高三维网络的效率……这些方法主要用于具有卷积结构的LiDAR点。
在本文中,我们提出了 dual-path transformer,用基于 transformer 的模块有效地处理相机生成的三维特征。
3. Approach
3.1. Overview
OccFormer的整体流程如图1所示。
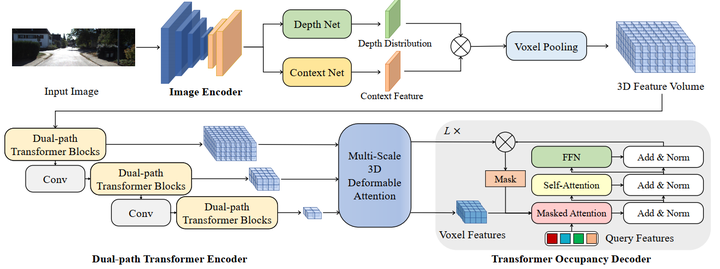
以单目图像或多目图像为输入,首先由图像编码器提取多尺度特征,然后提升为三维特征体。
三维特征被 dual-path transformer encoder(Sec.3.3)进一步处理,产生具有局部和全局语义的多尺度体素特征。最后,transformer occupancy decoder(Sec.3.3)融合多尺度特征,并将占用预测作为基 transformer 的掩码分类进行解码。
Image Encoder

图像编码器的目的是在透视图中提取几何和语义特征,这为后来生成的三维特征提供了基础。
图像编码器由一个用于提取多尺度特征的 backbone 网络和一个用于进一步融合的 neck 组成。
图像编码器的输出为输入分辨率的 1/16 的融合特征图:
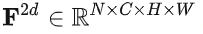
来表示提取的特征。N 是相机视角的数量,C是通道数,(H,W) 代表分辨率.
Image-to-3D Transformation
我们将LSS[40]的范式扩展到图像到三维的转换。
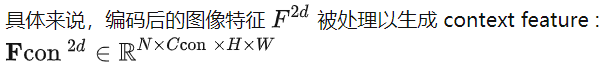


3.2. Dual-path Transformer Encod
为了追求远距离的、动态的、高效的三维特征体的处理,我们提出了 dual-path transformer 来构建三维编码器。
受最近将局部性引入 transformer 的进展的启发[51,58,25],我们也将编码器设计成一个混合结构 (hybrid structure)。编码器由一系列的 dual-path transformer 组成,同时在两个连续的块之间插入一个三维卷积层,以引入局部性并选择性地进行下采样。
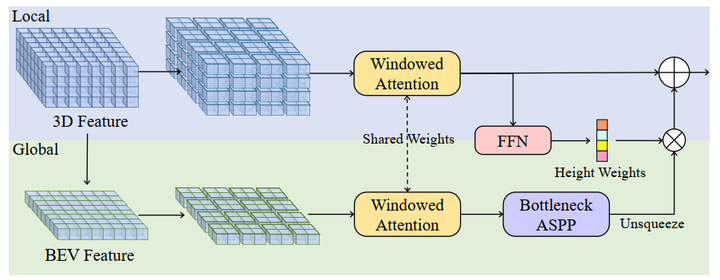
对于输入的三维特征,局部 local 和全局 global 路径首先沿水平方向并行地聚集语义信息。
接下来,双路径输出通过 sigmoid-weighted 进行融合。
最后,应用 skip connection 来确保剩余学习[18]。
local path
主要是提取细粒度语义结构。由于水平方向包含了最多的变化,我们相信用一个共享编码器对所有 BEV 切片进行并行处理能够保留大部分的语义信息。具体来说,我们将高度维度合并到批次维度(batch dimension)中,并采用 windowed self-attention 作为局部特征提取器 ( which can dynamically attend to long-range regions with moderate computations ).
global path
的目的是有效地捕捉场景级的语义布局 (scene-level semantic layouts)
首先通过沿高度维度的平均池化来获得BEV特征,利用来自 local path 的相同的windowed self-attention 来处理相邻语义的BEV特征。
由于我们发现 BEV 平面上的 global self-attention 会消耗过多的内存,因此采用ASPP[6]来捕捉全局的语义。
在实践中,我们采用 bottleneck 结构使 ASPP 的通道数减少了4倍。
最后, 来自 global path 的场景级信息从 local path 传播到整个 3D volume。
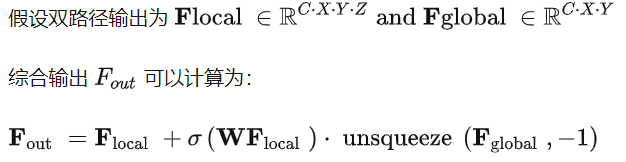
其中, W指的是沿高度维度生成聚合权重的 FFN;σ(·) 是 sigmoid 函数;“unsqueeze” 是沿高度方向扩展全局 2D 特征。
尽管 dual-path 处理只沿水平方向进行二维推理,但它们的结合有效地聚合了语义推理的重要的信息包括局部语义结构 (local semantic structures) 和全局语义布局 (global semantic layouts)
此外, dual-path transformer encoder 与经典的三维卷积相比,参数更少,需要的计算量也更少,这得益于共享模块和大部分二维推理。
3.3. Transformer Occupancy Decoder
受最近用于图像分割的掩码分类模型 (mask classification models)[10,9]的启发,我们也将三维语义占有率表述为预测一组有相应的类标签相关联的二进制3D掩膜 (binary 3D masks)。
继 Mask2Former 之后,我们的 transformer occupancy decoder 包括 pixel decoder 和 transformer decoder:
-
pixel decoder (Sec. 3.3.1) for per-voxel embeddings
-
transformer decoder (Sec. 3.3.2) for per-query embeddings and class predictions.
最终的掩码预测由这两个嵌入之间的点乘得出的。
此外,我们还介绍了两个重要的修改方法,以有效地提高占用率预测,包括:
-
preserve-pooling (Sec. 3.3.3)
-
class-guided sampling (Sec. 3.3.4)
transformer encoder 输入的多尺度特征体积表示为:
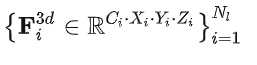
是层级号, C 是通道数, X,Y,Z 是体积尺寸。
3.3.1 Pixel Decoder
有了多尺度的三维特征作为输入,像素解码器的任务就是聚合多层次的语义并创建高分辨率的体素嵌入 (voxel embeddings)。
由于每个特征层次 (feature level) 对低层次细节和高层次语义的重视程度不同,我们采用了多尺度的可变形注意力 (multi-scale deformable attention ), 以促进尺度内 (intrascale) 和尺度间 (inter-scale) 的互动。
以第 i 级特征 为例:

最后,更新过程如下述公式:
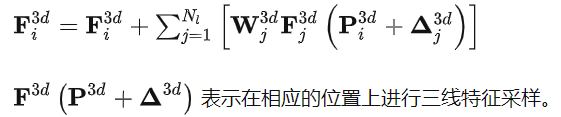
通过以上的相互作用,每个处理过的特征体都被多尺度语义信息所增强,这有利于下面的 transformer decoder 的工作。
3.3.2 Transformer Decoder
利用输入的多尺度体素特征 (multi-scale voxel features) 和参数化的查询特征 (parameterized query features) ,transformer decoder 对查询特征进行迭代更新,以达到预期的类别语义。
在每个迭代内,查询特征 (queries features) 首先通过 masked attention 来关注它们相对应前景区域:
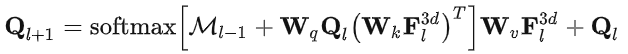
然后进行 self-attention,以交换上下文信息,然后用FFN进行特征投影。


3.3.3 Preserve-Pooling
当把高分辨率的掩膜预测转换为下一次迭代的低分辨率的注意力掩膜 (attention mask) 时 Mask2Former[9]采用了双线性插值进行下采样。该操作足以保护局部结构 (local structures),因为图像分割掩膜是比较完整和连续的。
然而,我们发现其三线插值的适应性,即三线插值 (trilinear interpolation),不能很好地处理三维语义占用预测。由于LiDAR生成的三维物体的分割掩膜通常是不完整的和稀疏的,三线性下采样会去除局部结构甚至整个物体。
为此,我们提出了 preserve-pooling,即简单地使用最大池化对注意力掩膜进行下采样。
3.3.4 Class-Guided Sampling
为了有效训练, Mask2Former 在计算匹配成本和最终损失时,对图像空间中的K个点进行均匀采样(或进一步使用重要性采样 (importance sampling))。
然而,在三维占用空间中,由于稀疏性和类的不平衡性,均匀采样难以捕捉到前景区域,特别是小类。为了解决这个问题,我们提出了类引导 (class-guided) 的采样方法。

在训练过程中,每个体素根据它的真实类别被分配一个采样权重。
然后,我们使用多项分布 (multinomial distribution) 对 K 个体素位置进行抽样,用于匹配和监督。
请注意,对于只有稀疏 LiDAR 点监督的 nuScenes 数据集,我们只是用 LiDAR 点和随机坐标以1:1的比例作为采样点。
3.4. Loss Functions
按照Mask2Former[10],我们只考虑采样位置,计算预测值和真实分割之间的二分图匹配 (bipartite matching)……
4. Experiments
4.1. Datasets
SemanticKITTI
:ground truth semantic occupancy 表示为 256 × 256 × 32 的体素网格,每个体素大小都是 0.2m×0.2m×0.2m。
nuScenes
:与TPVFormer[21]类似,我们用稀疏的 LiDAR 点监督来训 OccFormer,进行三维语义占用预测。
4.2. Implementation Details
Network Structures
image backbone network
SemanticKITTI: EfficientNetB7
nuScenes : ResNet-101
The view transformer 创建了尺寸为128×128×16的三维特征体,有128个通道。
transformer encoder 由4个阶段组成,其中每个阶段有2个双路径 transformer 模块。生成的 多尺度 3D 特征被投影到 192 个通道上,并由6层的多尺度可变形自注意力处理。
transformer decoder 主要遵循Mask2Former[9]的实现,我们将采样点的数量增加到50176个(4×),并将β设定为0.25,用于类指导采样。
预测的占用率被上采样2倍,以256×256×32,用于全尺寸评估。
4.4. Main Results
Semantic Scene Completion
OccFormer 与最近的TPVFormer[21]相比,我们的方法实现了1.06 mIoU的显著提升,证明了OccFormer对于语义场景完成的有效性.
SemanticKITTI test set
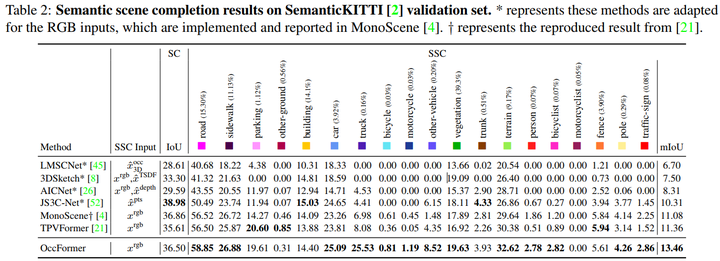
SemanticKITTI validation set
LiDAR语义分割
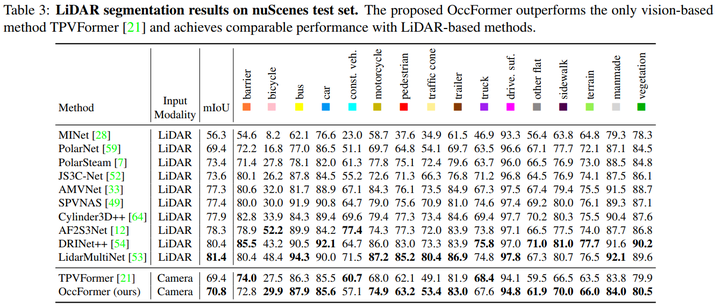
我们的方法只需要一个模型来执行激光雷达的分割和语义占用预测,而为激光雷达分割训练的TPVFormer[21]模型不能产生可重复的占用预测结果。
4.5. Ablation Studies
消融是在SemanticKITTI验证集上进行的,并从三个角度:
-
dual-path encoder
-
pixel decoder
-
transformer decoder
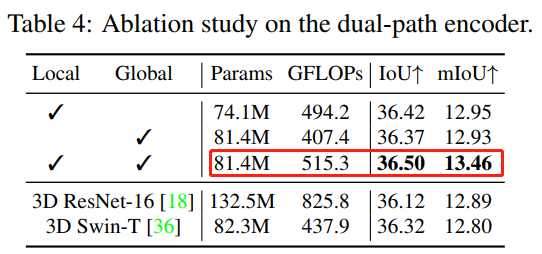
Ablation on the Dual-path Encoder.
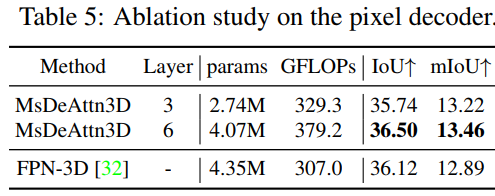
Ablation on the Pixel Decoder
Ablation on the Transformer Decoder

4.6. Qualitative Results
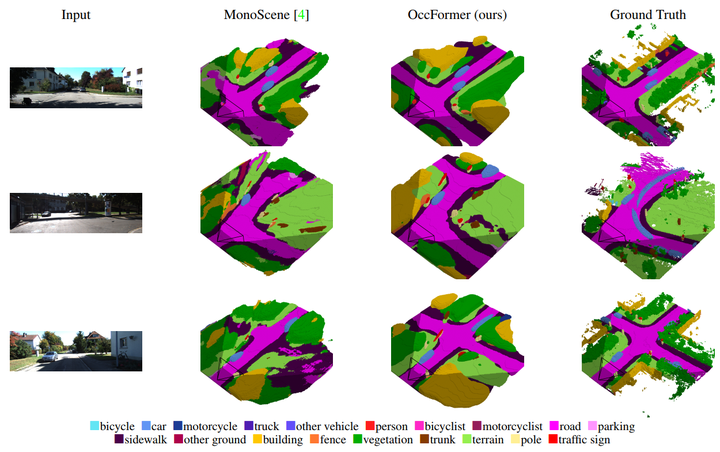
Semantic Scene Completion
LiDAR Segmentation and 3D Semantic Occupancy
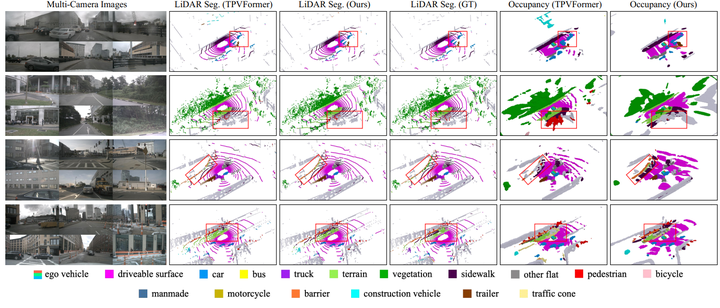
TPVFormer用两个单独训练的模型生成所需的输出,而我们的方法使用一个单一模型。尽管如此,OccFormer仍然在 LiDAR 分割上取得了更准确的结果。更重要的是, OccFormer预测的三维语义占用比TPVFormer更加连续、完整和现实。例如,预测的可行驶表面更加连续,像汽车和交通锥这样的前地面物体具有更准确的结构。
5. Conclusion
在本文中,我们提出了OccFormer,一个用于基于相机的三维语义占用预测的双路径变换器网络。
为了有效地处理摄像机产生的三维体素特征,我们提出了双路径变换器块,它通过局部和全局路径有效地捕捉细粒度的细节和场景级的布局。同时,我们也是第一个采用掩码分类模型进行三维语义占有率预测的人。考虑到固有的稀疏性和类的不平衡性,所提出的保留池和类引导的取样方法大大改善了性能 。
视频课程来了!
自动驾驶之心为大家汇集了毫米波雷达视觉融合、高精地图、BEV感知、传感器标定、传感器部署、自动驾驶协同感知、语义分割、自动驾驶仿真、L4感知、决策规划、轨迹预测等多个方向学习视频,欢迎大家自取(扫码进入学习)

(扫码学习最新视频)
国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、Occpuancy、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,
与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频
,期待交流!

【
自动驾驶之心
】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称