LiST: Lite Prompted Self-training Makes Parameter-efficient Few-shot Learners
这篇文章是清华大学放在了Deta tuning的论文列表中但是论文的内容似乎是和prompt learning有关
这篇文章在介绍的时候是说他们的模型参数量比较少然后也取得了比较好的效果,但其实这篇文章它的应用的模型并不少包括的知识点,有知识蒸馏还有就是promote learning的一些相关知识.
创新点
我觉得这篇文章的创新点主要是在于,
第一个是对无标注数据的使用上,
第2个是对于无标注数据在使用过程中可能会出现为标签问题的解决方式上,在第2个方向会面临着伪标签的问题对于伪标签问题他也采用了一个权重的方式,对于不同的伪标签数据根据它的重要性的程度设置了不同的权值。
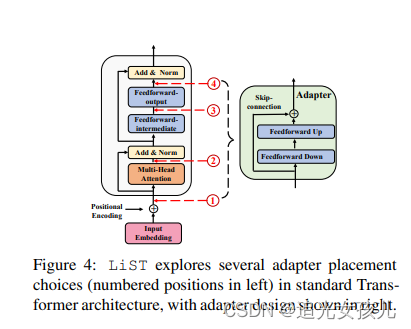
第3个方向是这篇文章探索了adapter它放置在整个的transformer中的不同的位置会带来的不同的效果的影响
整个过程:
整篇文都是分成了5个部分。
第一个部分呢主要是通过一个teacher adapter的tuning,在有标签的小数据集上完成adapter tuning的训练过程。
然后通过在有标签数据上微调的teacher adapter tuning的模型对无标注数据分配伪标签。
第三是使用meta-learning方式也就是元学习的方式对于伪标签分配不同的权重。
第四步就是应用对于重新分配权重的数据来训练student adapter模型
第五部是通过知识蒸馏的手段,将student adapter作为新的teacher adapter。
整个文章的训练过程是把分类问题建模为了填空问题。(fill-in-mask任务)按照提示学习的范式建模整个任务。